【YOLOv5】
学习摘抄来自
- Yolov5技术总结
- YOLOv5-Lite 详解教程 | 嚼碎所有原理、训练自己数据集、TensorRT部署落地应有尽有
- YOLOV5代码解析(更新中) —— https://github.com/Laughing-q/yolov5_annotations
- yolov5特征图可视化
文章目录
- 1 Backbone
- 2 Neck
- 3 Detection (YOLO) layer
- 4 输出
- 5 损失函数
- 6 优化策略
- 7 数据增强:
- 8 后处理
- 9 特征图可视化
- 10 Yolov5-1.0、2.0、3.0
1 Backbone
1)Focus
减少计算量加快速度

yolov5中的Focus模块的理解
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Focus, self).__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act) # 这里输入通道变成了4倍
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
用 Focus 的原因

yolov5中的Focus模块的理解
2)SPP
分别采用 5/9/13 的最大池化,再进行 concat 融合,提高感受野;
3)BottleNeckCSP
Cross Stage Partial Networks,减少计算量,提高卷积神经网络学习能力;
4)C3
C3 Leyer 是 YOLOv5 作者提出的 CSPBottleneck 改进版本,它更简单、更快、更轻,在近乎相似的损耗上能取得更好的结果。但 C3 Layer 采用多路分离卷积,测试证明,频繁使用 C3 Layer 以及通道数较高的 C3 Layer,占用较多的缓存空间,减低运行速度。
为什么通道数越高的 C3 Layer 会对 cpu 不太友好?,主要还是因为 Shufflenetv2 的 G1 准则,通道数越高,hidden channels 与 c1、c2 的阶跃差距更大,来个不是很恰当的比喻,想象下跳一个台阶和十个台阶,虽然跳十个台阶可以一次到达,但是你需要助跑,调整,蓄力才能跳上,可能花费的时间更久
5)ShuffleNetV2
是 YOLOv5 Lite 中的主要结构

stride = 2

stride = 1
Channel Split 的好处
整个特征图分为 2 个组了,但是这样的分组又不像分组卷积一样,增加了卷积时的组数,符合准则 2;这样分开之后,将 A 组认为是通过 short-cut 通道的,而 B 组经过的 bottleneck 层的输入输出的通道数就可以保持一致,符合准则1;
同时由于最后使用的 concat 操作,没有用 TensorAdd 操作,符合准则4;
可以看到,这样一个简单的通道分离的操作带来了诸多好处;但是从理论上来说,这样的结构是否还符合 short-cut 的初衷(即bottleneck 学到的是残差 Residual 部分)?这里笔者也不好妄加揣测,但是可以想到的是经过后面的 Channel Shuffle 的乱序之后,每个通道应该都会经过一次 bottleneck 结构。
上述的结构是不改变输入输出通道数和特征图大小的情况,而池化操作使用图(d)代替了,跟 ShuffleNetV1 类似,经过这样的结构之后,图像通道数扩张为原先的 2 倍。
2 Neck
在 Backbone 和输出层,会插入一些层,这个部分称为 Neck



3 Detection (YOLO) layer
1)Anchor
根据超参数中的 hyp[‘anchor_t’] 来检查默认 anchor 与数据集标签的契合度,如果<0.98,则根据数据集标签进行聚类重新获得anchor;
默认anchor如下:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/3
自适应计算 Anchor,流程如下
1)载入数据集,得到数据集中所有数据的wh;
2)将每张图片中wh的最大值等比例缩放到指定大小img_size,较小边也相应缩放;
3)将bboxes从相对坐标改成绝对坐标(乘以缩放后的wh);
4)筛选bboxes,保留wh都大于等于两个像素的bboxes;
5)使用k-means聚类得到n个anchors(掉k-means包 涉及一个白化操作);
6)使用遗传算法随机对anchors的wh进行变异,如果变异后效果变得更好(使用anchor_fitness方法计算得到的fitness(适应度)进行评估)就将变异后的结果赋值给anchors,如果变异后效果变差就跳过,默认变异1000次;
2)anchor 匹配机制
这里先说一下 YOLOv3 的匹配策略:
假设一个图中有一个目标,这个被分割成三种格子的形式,分割成13×13 、26 × 26、52 × 52 。
-
这个目标中心坐标下采样8倍,(416/8=52),会落在 52 × 52 这个分支的所有格子中的某一个格子,落在的格子会产生3个anchor,3个anchor和目标(已经下采样8倍的目标框)分别计算iou,得到3个iou,凡是iou大于阈值0.3的,就记为正样本,就会将label[0]中这个iou大于0.3的anchor的相应位置 赋上真实框的值。
-
这个目标中心坐标下采样16倍,(416/16=26),会落在 26 × 26 这个分支的所有格子中的某一个格子,落在的格子会产生3个anchor,3个anchor和目标(已经下采样16倍的目标框)分别计算iou,得到三个iou,凡是iou大于阈值0.3的,就记为正样本,就会将label[1]中这个iou大于0.3的anchor的相应位置 赋上真实框的值。
-
这个目标中心坐标下采样32倍,(416/32=13),会落在 13 × 13 这个分支的所有格子中的某一个格子,落在的格子会产生3个anchor,3个anchor和目标(已经下采样32倍的目标框)分别计算iou,得到三个iou,凡是iou大于阈值0.3的,就记为正样本,就会将label[2]中这个iou大于0.3的anchor的相应位置 赋上真实框的值。
-
如果目标所有的anchor,9个anchor,iou全部小于阈值0.3,那么选择9个anchor中和下采样后的目标框iou最大的,作为正样本,将目标真实值赋值给相应的anchor的位置。
总的来说,就是将目标先进行 3 种下采样,分别和目标落在的网格产生的 9 个 anchor 分别计算 iou,大于阈值 0.3 的记为正样本。如果 9 个 iou 全部小于 0.3,那么和目标 iou 最大的记为正样本。对于正样本,我们在label上 相对应的anchor位置上,赋上真实目标的值。
下面再看看 yolov5 的匹配机制
采用了跨网格匹配规则,增加正样本 Anchor 数目的做法
对于任何一个输出层,yolov5 抛弃了 Max-IOU 匹配规则而采用 shape 匹配规则,计算标签 box 和当前层的 anchors 的宽高比,即:wb/wa,hb/ha。如果宽高比大于设定的阈值说明该 box 没有合适的 anchor,在该预测层之间将这些box 当背景过滤掉。
# r为目标wh和锚框wh的比值,比值在0.25到4之间的则采用该种锚框预测目标
r = t[:, :, 4:6] / anchors[:, None] # wh ratio:计算标签box和当前层的anchors的宽高比,即:wb/wa,hb/ha
# 将比值和预先设置的比例anchor_t对比,符合条件为True,反之False
j = torch.max(r, 1 / r).max(2)[0] < self.hyp['anchor_t'] # compare
eg:hyp['anchor_t'] 设置为 4,则 0.25~4 之间的 shape 符合
对于剩下的 GT bbox,计算其落在哪个网格内,同时利用四舍五入规则,找出最近的2个网格,将这3个网格都认为是负责预测该bbox 的,可以发现粗略估计正样本数相比前 yolo 系列,增加了3倍。code 如下
在 general.py 的 build_targets 中可以找到
g = 0.5
# Offsets
# 得到相对于以左上角为坐标原点的坐标
gxy = t[:, 2:4] # grid xy
# 得到相对于右下角为坐标原点的坐标
gxi = gain[[2, 3]] - gxy # inverse
# 这两个条件可以用来选择靠近的两个邻居网格
# jk和lm是判断gxy的中心点更偏向哪里
j, k = ((gxy % 1 < g) & (gxy > 1)).T
l, m = ((gxi % 1 < g) & (gxi > 1)).T
j = torch.stack((torch.ones_like(j), j, k, l, m))
# yolov5不仅用目标中心点所在的网格预测该目标,还采用了距目标中心点的最近两个网格
# 所以有五种情况,网格本身,上下左右,这就是repeat函数第一个参数为5的原因
t = t.repeat((5, 1, 1))[j]
# 这里将t复制5个,然后使用j来过滤
# 第一个t是保留所有的gtbox,因为上一步里面增加了一个全为true的维度,
# 第二个t保留了靠近方格左边的gtbox,
# 第三个t保留了靠近方格上方的gtbox,
# 第四个t保留了靠近方格右边的gtbox,
# 第五个t保留了靠近方格下边的gtbox,
offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
对于 YOLOv5,不同于 yolov3, yolov4 的是:其 gt box 可以跨层预测,即有些 gt box 在多个预测层都算正样本;同时其 gt box 可匹配的 anchor 数可为 3~9个,显著增加了正样本的数量。不再是 gt box 落在那个网格就只由该网格内的 anchor 来预测,而是根据中心点的位置增加 2 个邻近的网格的 anchor 来共同预测。

如下图所示,绿点表示该 gt bbox 中心,现在需要额外考虑其2个最近的邻域网格的 anchor 也作为该 gt bbox 的正样本,明显增加了正样本的数量。
目标检测重中之重可以理解为 Anchor 的匹配策略
补充(标签分配):
每个网格除了回归中心点在该网格的目标,还会回归中心点在该网格附近周围网格的目标,
grid(i, j)也会回归grid(i, j+1),grid(i, j-1),grid(i+1, j),grid(i-1, j)中的部分框,如下图中红色部分,
这也契合了上面的边框回归中心点的范围为-0.5~1.5;

总结;
-
跨预测分支预测(多个 feature map):假设一个ground truth框可以和2个甚至3个预测分支上的anchor匹配,则这2个或3个预测分支都可以预测该ground truth框,即一个ground truth框可以由多个预测分支来预测。
-
跨网格预测(多个 cell):假设一个ground truth框落在了某个预测分支的某个网格内,则该网格有左、上、右、下4个邻域网格,根据ground truth框的中心位置,将最近的2个邻域网格也作为预测网格,也即一个ground truth框可以由3个网格来预测;
-
跨 anchor 预测(多个 anchor):假设一个ground truth框落在了某个预测分支的某个网格内,该网格具有3种不同大小anchor,若ground truth可以和这3种anchor中的多种anchor匹配,则这些匹配的anchor都可以来预测该ground truth框,即一个ground truth框可以使用多种anchor来预测。
3)边框回归
先回顾下 v3 和 v4 的
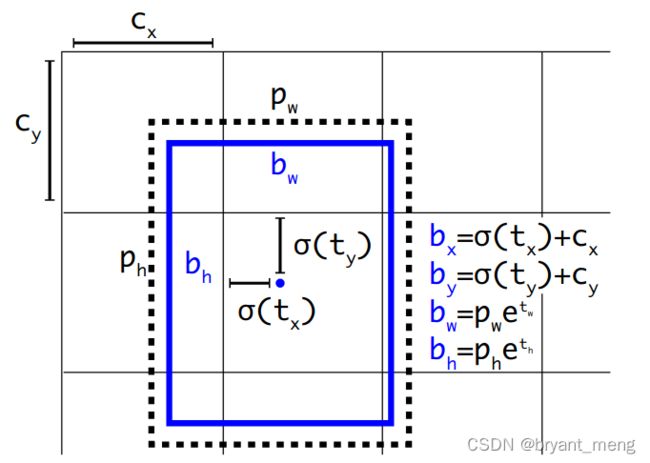

下面看看 v5 的
在进行边框回归 筛选样本对应 anchor 的时候,就是通过 hyp[‘anchor_t’] 来筛选,而不是 iou;
新的边框回归方式:

( 2 ∗ y [ . . . , 0 : 2 ] − 0.5 + g r i d [ 0 ] ) ∗ s t r i d e [ 0 ] (2*y[..., 0:2] -0.5 + grid[0])* stride[0] (2∗y[...,0:2]−0.5+grid[0])∗stride[0]
以 640x640 输入为例
g r i d [ 0 ] grid[0] grid[0] 的维度为 [1,1,80,80,2],两个 80 表示 1/8 特征图的每个空间位置,2 表示 anchor 的横纵坐标
s t r i d e [ 0 ] stride[0] stride[0] 的维度为 [8, 8]
y [ . . . , 0 : 2 ] y[..., 0:2] y[...,0:2] 是经过 sigmoid 的输出,可以看出,偏移的范围为 2 ∗ ( 0 ∼ 1 ) − 0.5 = − 0.5 ∼ 1.5 2*(0 \sim 1)-0.5 = -0.5\sim 1.5 2∗(0∼1)−0.5=−0.5∼1.5
( 2 ∗ y [ . . . , 2 : 4 ] ) 2 ∗ a c h o r _ g r i d [ 0 ] (2*y[..., 2:4])^2*achor\_grid[0] (2∗y[...,2:4])2∗achor_grid[0]
a c h o r _ g r i d [ 0 ] achor\_grid[0] achor_grid[0] 维度为 [1,3,1,1,2],3 表示 3 种 anchor
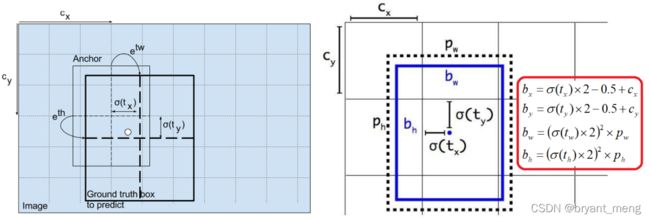
中心偏移的范围是 [-0.5,1.5],hw偏移的范围是 (0, 4),范围是 0~4 的 anchor ,这是因为采用了跨网格匹配规则,要跨网格预测了。
为啥这么改造

可以看出,对于不同的 t w tw tw 和 t h th th,当他们大于零比较多时,YOLOv5 的反馈更加平滑,相对于v 3、v4也就更容易收敛
4 输出

图中向量包含 4 个坐标信息,一个包含目标概率和 80 个类别得分,换句话解释就是“这个图像中是否有目标(物体出现的概率)?有的话是什么(80 类的类别得分)?然后就是这个目标物体在哪里(box 坐标位置)?
5 损失函数
- 边框回归:CIOU loss(GIoU)
- Objectness:BCEWithLogits Loss
- 分类:BCE
损失平衡:ciou = 0.05,objectness = 1, cls = 0.5;
三个输出层损失平衡:4.0, 1.0, 0.4 分别对应下采样 8,16,32 的输出层
6 优化策略
- Warmup热身训练;
- Cosine余弦退火;
- 梯度累积;
- EMA;
7 数据增强:
- Mosaic;
- 仿射变换,随机的旋转,平移,缩放,裁剪,上下左右翻转;
- 随机hsv;
进行数据增强操作还有一个 bbox 筛选的过程:
去除被裁剪过小的框(面积小于裁剪前的20%),并且还有长和宽必须大于 2 个像素,且长宽比范围在 (1/20, 20) 之间的限制;
def box_candidates(xxx):
xxx
8 后处理
DIoU NMS
因为前面讲到的 CIOU loss,是在 DIOU loss 的基础上,添加的影响因子,包含 ground truth 标注框的信息,在训练时用于回归。但在测试过程中,并没有 ground truth的信息,不用考虑影响因子,因此直接用DIOU NMS即可。
补充材料
YOLO系列算法在构建回归目标时一个主要的区别就是如果将图像划分成 SxS 的格子,每个格子只负责目标中心点落入该格子的物体的检测,如果没有任何目标的中心点落入该格子,则为负样本
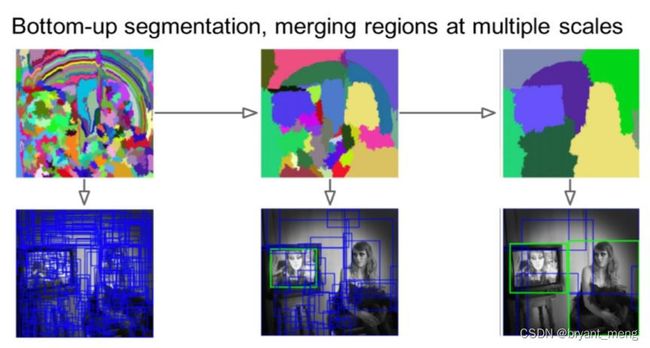
Selective Search,主要思路是通过图像中的纹理、边缘、颜色等信息对图像进行自底向上的分割,然后对分割区域进行不同尺度的合并,每个生成的区域即一个候选Proposal,如下图所示。这种方法基于传统特征,速度较慢
Soft NMS相对于NMS的改进即每次并不是直接排除掉和已选框重叠大于一定阈值的框,而是以一定的策略降低对应框的得分,直到低于某个阈值,从而不至于过多删除拥挤情况下定位正确的框。
Softer NMS相对于NMS的改进即每次并不是直接以得分最大的框的坐标作为当前选择框的坐标,而是和得分最大的框重叠大于一定阈值的所有框的坐标进行一定策略的加权平均,所得的新的框作为当前选择的得分最大的框的坐标,从而尽可能准确地定位物体。
IOU-Guided NMS:即以IOU(交并比)得分作为NMS的排序依据,因为IOU得分直接反应了对应框的定位精确程度,优先考虑定位精度较高的框,防止定位精度较低但是其他得分较高的框被误排序到前面。
9 特征图可视化
来自 yolov5特征图可视化
在 utils 中的 general.py 或者 plots.py 添加如下函数
import matplotlib.pyplot as plt
from torchvision import transforms
def feature_visualization(features, model_type, model_id, feature_num=64):
"""
features: The feature map which you need to visualization
model_type: The type of feature map
model_id: The id of feature map
feature_num: The amount of visualization you need
"""
save_dir = "features/"
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# print(features.shape)
# block by channel dimension
blocks = torch.chunk(features, features.shape[1], dim=1)
# # size of feature
# size = features.shape[2], features.shape[3]
plt.figure()
for i in range(feature_num):
torch.squeeze(blocks[i])
feature = transforms.ToPILImage()(blocks[i].squeeze())
# print(feature)
ax = plt.subplot(int(math.sqrt(feature_num)), int(math.sqrt(feature_num)), i+1)
ax.set_xticks([])
ax.set_yticks([])
plt.imshow(feature)
# gray feature
# plt.imshow(feature, cmap='gray')
# plt.show()
plt.savefig(save_dir + '{}_{}_feature_map_{}.png'
.format(model_type.split('.')[2], model_id, feature_num), dpi=300)
接着在 models 中的 yolo.py 中的这个地方:
def forward_once(self, x, profile=False):
y, dt = [], [] # outputs
for m in self.model:
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
o = thop.profile(m, inputs=(x,), verbose=False)[0] / 1E9 * 2 if thop else 0 # FLOPS
t = time_synchronized()
for _ in range(10):
_ = m(x)
dt.append((time_synchronized() - t) * 100)
print('%10.1f%10.0f%10.1fms %-40s' % (o, m.np, dt[-1], m.type))
x = m(x) # run
y.append(x if m.i in self.save else None) # save output
# add in here
if profile:
print('%.1fms total' % sum(dt))
return x
添加
feature_vis = True
if m.type == 'models.common.C3' and feature_vis:
print(m.type, m.i)
feature_visualization(x, m.type, m.i)
yolo.py 的开头添加 from utils.general import feature_visualization
添加在 yolo.py后,无论是在 detect.py还是在 train.py 中都会进行可视化特征图。
10 Yolov5-1.0、2.0、3.0
1)1.0->2.0:
yolov5x mAP有提升,但yolov5s mAP却下降了,
训练策略的改变,包括余弦退火的公式更新了,以及类别损失 cls_loss 的系数 gain,对数据进行仿射变换 (dataset.py数据增强部分) 的超参数进行调整,三个output的损失比重balance的调整。
2)2.0->3.0:
V3.0据作者所说,大约10%的推理速度为代价提高了所有模型的mAP。尽管CUDA内存需求增加了约10%,但训练速度并未受到明显影响,具体未测试;
最小的模型从Hardswish()**中受益最大,YOLOv5s / m / l / x的增加幅度为+0.9/+0.8/+0.7/[email protected]:0.95。
主要做出的变化是,采用了hardswish**函数替换CONV(下图右下角模块)模块的LeakyReLu,但是注意:BottleneckCSP模块中的LeakyReLu未被替换,采用了CIOU作为损失函数(但这个更新好像是还在v2.0版本过度的时候已经更新),还更改了一个默认超参数:translate=0.5 → 0.1(数据增强的仿射系数)。