文章阅读总结:视频理解论文串讲(Li Mu+ Yi zhu)
文章目录
-
- 视频理解论文串讲(文章末尾有多数文章的地址)
-
- 1. Hand-Craft ===> CNN : DeepVideo
- 2. Two-Stream
-
- 2.1 2014_Two stream ConvolutionalNetworks for action recognition in vedios
- 2.2 2015_Beyond Short Snippets_Beyond Short Snippets_Deep Networks for Video Classification
- 2.3 2016_CTN_Convolutional Two-Stream Network Fusion for Video Action Recognition
- 2.4 2016_TSN_Temporal Segment Networks Towards Good practives fro deep action recognition
- 3. 3D ConvNet
-
- 3.1 2015_C3D_Learning Spatiotemporal Features with 3D Convolutional Networks
- 3.2 2018_I3D_quo vadis action recognition a new model and the kinetics dataset
- 3.3 2018_Non-local neural networks
- 3.4 2018_A Closer Look at Spatiotemporal Convolutions for Action Recognition.pdf
- 3.5 2019_SlowFast Networks for Video Recognition
- 4. Video Transformer
- 5.总结
- 6. 引用
-
- 6.1 视频与Github
- 6.2 文章
视频理解论文串讲(文章末尾有多数文章的地址)

1. Hand-Craft ===> CNN : DeepVideo
探索可以用在视频上的各种神经网络:

- 从视频中抽取单帧进行分类
- 对不同的帧使用抽取不同的特征,最后使用全连接层融合各个不同帧的特征
- 在输入层上融合不同的帧,同时输入进行特征抽取,再进行分类
- 使用不同的神经元抽取不同的视频帧的特征,然后逐渐融合非常多的视频帧
各种方法的测试结果效果差不多,第四种会稍微好一些。
多分辨率神经网络:两个权值共享的网络,一个处理低分辨率的图像,一个处理高分辨率的图像(图片的中心区域),人为提高了注意力


2. Two-Stream
双流网络在这里指的是同时使用光流抽取的特征和图片(视频帧)本身的特征进行网络训练;经测试这种方法可以很大地提高网络捕捉动态效果的能力
2.1 2014_Two stream ConvolutionalNetworks for action recognition in vedios

2.2 2015_Beyond Short Snippets_Beyond Short Snippets_Deep Networks for Video Classification
想办法适应更长时间的视频、动作特征的提取等等。
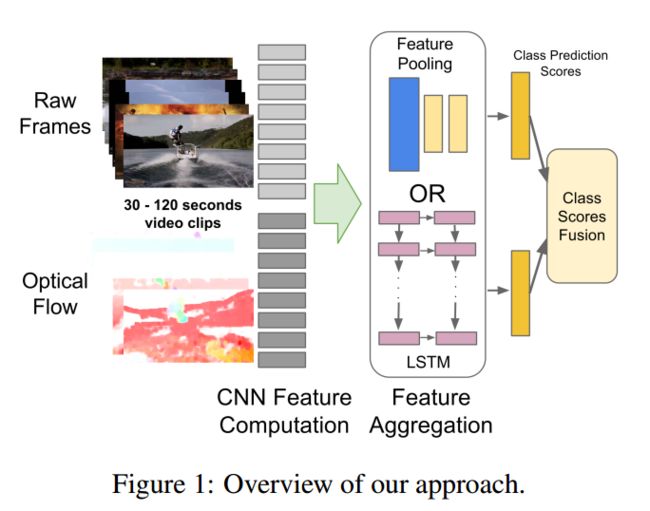
- 在抽取特征之后应该选择什么样的pooling方法? -> 使用一个CNN
- 怎么融合抽取的特征 -> LSTM
- 在短视频上加上LSTM的优化程度很低,基本没有什么变化
2.3 2016_CTN_Convolutional Two-Stream Network Fusion for Video Action Recognition
通常对于一个具有三个维度特征的数据而言我们有很多的探究方向:
- Spatial fusion : 空间特征融合
- Time fusion : 时间维度特征融合
- 在网络的那一层进行特征融合
本文采用了一种Early fusion的方法:在早期就融合特征(通过不同的方法抽取特征,在输入网络前期就将这些特征进行融合)。

网络架构:一个网络分支抽取空间特征一个抽取时间特征,然后进行融合;另一个分支只融合空间特征;最后使用加权平均进行特征整体融合。

2.4 2016_TSN_Temporal Segment Networks Towards Good practives fro deep action recognition
这篇文章使用用特别简单的方法来处理特别长的视频,而且效果非常好,并且提供了很多好的技巧(数据增强、选择网络、处理光流数据)
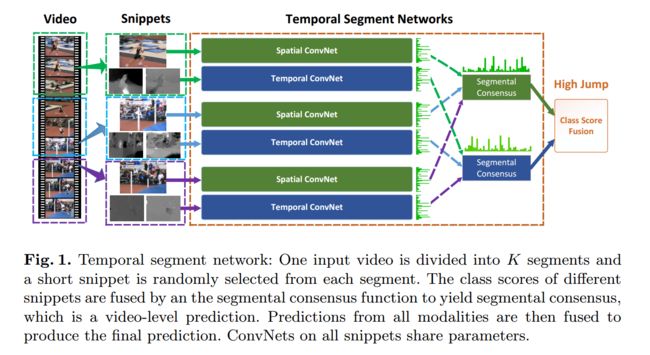
步骤如下:
- 将视频分为多个段,从每段中抽取一帧的RGB图片,然后对这个图片进行光流计算
- 重复工作,对不同段进行相同工作
- 如果段分得比较小,那么抽取的特征在理论上是描述的同一个物体的运动特征
- 最后进行一个特征融合,进行分类工作
好用的技巧
- 预训练迁移:图片领域有预训练模型应用于视频是非常好的,但是光流没有一个非常好的预训练模型,但是也可以用ImageNet这些预训练的模型(注意通道数的变化)
- 模型正则化(一个令人又爱又恨的层):BN可以加速训练,但是会让模型容易过拟合。这里采用了partial BN:冻住部分层的BN,只要第一层的BN
- 数据增强,crop边缘的数据、改变长宽比
3. 3D ConvNet
- 2D convNet毕竟是只是关注于空间信息,串连2D图片其实也只是强行添加了时序信息,而采用3D网络可以直接利用隐藏于其中的时序信息
- 2D convNet通常需要使用光流信息,抽取光流是一个耗时的操作,使用3D网络希冀可以不用抽取光流等辅助数据
- 对于视频的各种处理工作我们希望是一个实时的工作,抽取光流的时间消耗使得这种方法的实时性大大降低
3.1 2015_C3D_Learning Spatiotemporal Features with 3D Convolutional Networks
使用特别深的网络、特别大的数据进行训练(sprots 1million数据集)

C3D主要是提供了一种抽取特征做其他任务的方法(因为训练一个大型的3D网络非常昂贵,很多研究者无法训练),C3D作者将训练好的模型的接口提供给其他人,其他人只需要输入视频就可以得到抽取的特征(4096序列),这样就可以根据抽取的特征进行后续处理了。
3.2 2018_I3D_quo vadis action recognition a new model and the kinetics dataset
贡献:
- 可以方便地将2D网络扩张到3D之中,可以用巧妙的方法利用预训练模型
- 提出了kinetics数据集
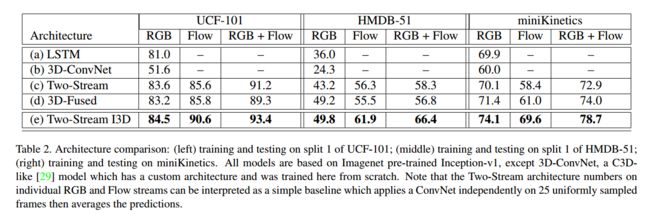
几种不同的视频分类策略和网络结构:

- 2D convNet + LSTM
- 3D convNet
- 2D convNet + optical flow (使用加权平均进行聚合)
- 2D convNet + optical flow ==> 3D convNet(使用3D网络进行聚合)
- 3D convNet + 3D convNet optical flow(I3D)
不同策略的效果如下,可见使用3D+双流的效果是最优秀的
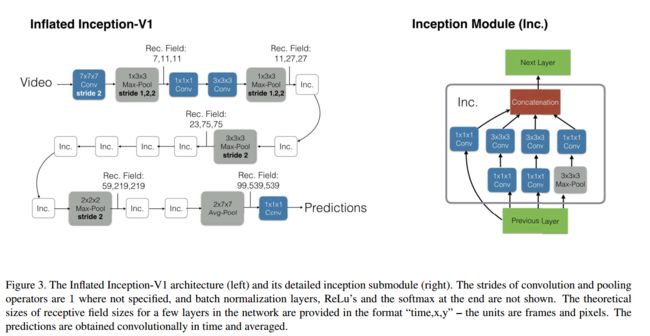
Two-Stream Inflated 3D ConvNet的一些方法策略
- Inflating 2D ConvNets into 3D : 从一个2D结构出发,扩展其中的2D卷积核和池化核为3D的(增加一个额外的时间维度):NxN --> N x N x N
- Bootstrapping 3D filters from 2D filters : 从2D预训练模型中提升3D。验证预训练模型是否是等效替换到3D网络结构中的一个方法:将2D图片复制n次叠加成一个n帧的视频使用3D卷积网络进行预测,如果预测输出结构和2D网络一模一样说明预训练模型完全继承。
- 在空间、时间和网络深度上对感受野的增长进行调整:对于图片的两个空间维度,我们通常使用相同的卷积长度/池化长度,但是在时间维度上并不相同,时间维度的kernel长度取决于帧率和图片大小。如果在时域内变化太块,它可能会混淆不同物体的边缘,破坏早期的特征检测,而如果它增长得太慢,它可能无法很好地捕捉场景的动态。动态性。
3.3 2018_Non-local neural networks
将注意力机制加入到视频分析领域(这里叫做non-local block算子,其实也就是注意力机制)
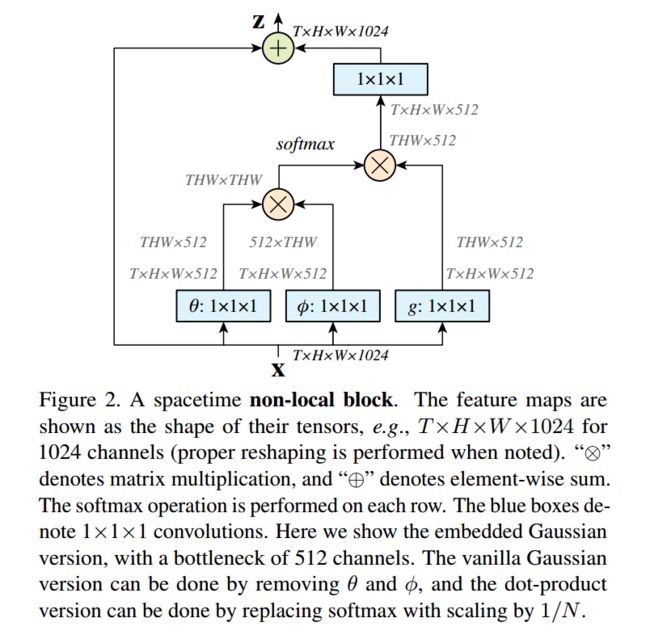
3.4 2018_A Closer Look at Spatiotemporal Convolutions for Action Recognition.pdf
R2+1D,将3D网络拆分为空间上的2D和时间上的1D网络效果会非常好,同时计算消耗和空间消耗大大降低

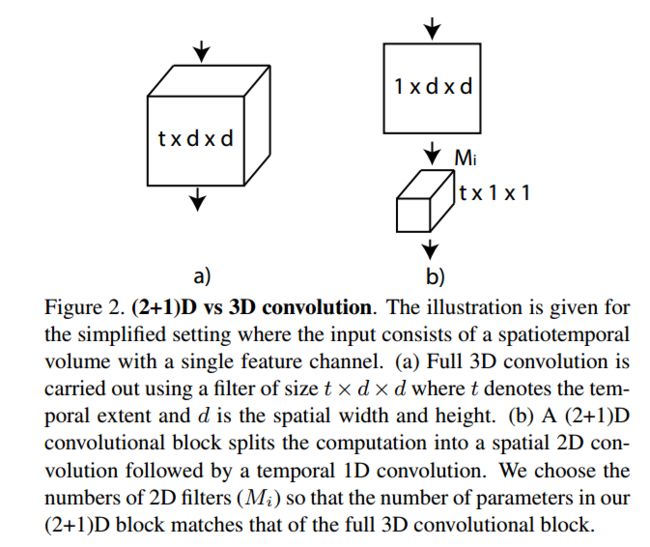
就是先让时间上的维度是1然后进行一个特征投射,最后只在时间上进行一个1D卷积
- 增加了网络的非线性(每一个卷积后面都会有激活)
- 直接学3D卷积不容易学习,但是1个2D+1个1D更容易学习
3.5 2019_SlowFast Networks for Video Recognition
慢的分支网络学习视频中的静态特征,快分支学习视频中的动态特征。
- 慢分支使用小输入,大网络
- 快分支使用大输入,小网络
- 中间使用natural connection进行特征融合


4. Video Transformer
将图片领域的VIT迁移到视频领域

- 直接将Attention应用到图片的方法迁移到视频之中(空间注意力)
- 在时间上和空间上分别做三个自注意力机制,进行融合
- 拆分为空间和时间上分别进行注意力机制计算(时间-> 空间)
- local global拆分(在局部进行注意力计算)
- 沿着特定的轴进行注意力计算(将三维拆分为三个一维进行注意力机制计算)

想法简单、效果好、容易迁移、可以用于处理超过1min的视频
5.总结

视频领域可以借鉴的内容:
- 对于时间和空间相结合的一些策略可以借鉴
- 3D卷积怎么做:最新的方法都是做一些拆分,将3D卷积分为时间和空间分别的卷积
- 特征融合的方法:early fusion、latent fusion
- 三维网络中一些关键层(如BN)如何设置:只要第一层的BN?
- 3D网络中的时间维度尽量不要做下采样
- Vision Transformer降维打击,提高精度、减小计算消耗、加大处理时长(看到更长的时序信息)
- 应用人工智能在一个新的领域的发展历史
- 直接应用2D CNN处理 --> DeepVideo
- 加入提取好的特征进行处理(双流网络、Two-stream、TDD、ZDT)
- 提取光流效率低、存储空间占用大、只能处理短时序序列的视频 --> 改进特征融合、网络结构
- 3D卷积直接利用视频的信息(但是加入光流的提升效果还是非常明显)
- Vision Transformer
6. 引用
6.1 视频与Github
-
视频理解论文串讲(上)【论文精读】
-
视频理解论文串讲(下)【论文精读】
-
https://github.com/mli/paper-reading/
6.2 文章
-
A Comprehensive Study of Deep Video Action Recognition
-
Large-Scale Video Classification with Convolutional Neural Networks
-
Two-Stream Convolutional Networks for Action Recognition in Videos
-
Beyond Short Snippets: Deep Networks for Video Classification
-
Convolutional Two-Stream Network Fusion for Video Action Recognition
-
Temporal Segment Networks: Towards Good Practices for Deep Action Recognition
-
Learning Spatiotemporal Features with 3D Convolutional Networks
-
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
-
Non-local Neural Networks
-
A Closer Look at Spatiotemporal Convolutions for Action Recognition
-
SlowFast Networks for Video Recognition
-
Is Space-Time Attention All You Need for Video Understanding?