基于pytorch的Swim Transformer代码实现与讲解
Swim transformer是2021年ICCV的best paper。
论文题目:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows(使用移动窗口的层级式的Vision transformer)
论文地址:https://arxiv.org/abs/2103.14030
动机:
transformer从NLP用于CV任务中主要有两个挑战:
1、尺度问题。例如一张图像中包含很多车和行人,物体有大有小,而且代表同一个语义的词可能在图像中具有不同的尺寸。
2、图像的分辨率大,如果以像素为单位,序列的长度太长。之前减少序列长度主要有一下三方面的工作:
1、使用网络后续的特征图,当做transformer的输入。
2、图片打成patch,减少图像的resolution。
3、将图片划成小窗口,在窗口中做自注意力。
本文作者提出层级式的transformer结构,特征通过移动窗口的方式学习得到。窗口自注意力(Window Multi-heads Self-Attention, W-MSA)相比于基于全局的自注意力(Multi-heads Self-Attention, MSA)方法的方式,减少了计算复杂度;但由于每个窗口之间互不重叠,导致相邻窗口之间信息无法交互,因此提出移动窗口(Shifted Window Multi-heads Self-Attention, SW-MSA)的方法,使相邻两个窗口之间的信息有了交互,上下层之间有了cross window connection,变相的达到了全局建模的能力。层级结构的好处在于可以提供各个尺度的特征信息,使transformer拥有了像CNN一样的分层结构,有了多尺度特征,更好的应用在下游任务上。

模型结构
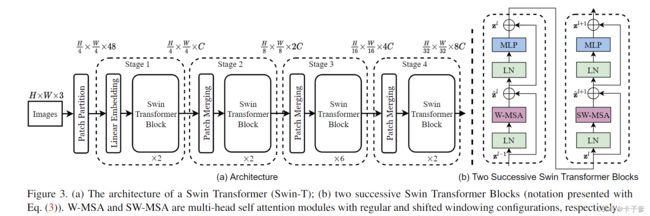
由图可知模型主要包含Patch partition、Linear embedding、Swim Transformer Block、W-MSA和SW-MSA组成。接下来一一介绍以及代码实现。
Patch Partition + Linear Embedding
Patch Partition对输入图像进行下采样,将原始输入图像H,W,C,宽高下降1/4,通道进调整到48。Linear Embedding是对Patch Partition的输出在通道维度进行调整为C后,过Layer Normalization。C为不同的模型设置不同的C值。 实现是直接使用nn.Conv2d直接从输入图像的通道维度转为模型的需要设置的通道维度,即[H, W, C] -> [H/4, W/4, C].
class patchEmbed(nn.Module):
# 将图片分割成不重叠的小patch 尺寸下采样尺寸为patch size的大小
def __init__(self, patch_size=4, in_channels=3, embed_dim=96, norm_layer=None):
super(patchEmbed, self).__init__()
patch_size = (patch_size, patch_size)
self.patch_size = patch_size
self.in_channels = in_channels
self.embed_dim = embed_dim
self.proj = nn.Conv2d(in_channels, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
_, _, H, W = x.shape
# padding 如果输入image的H, W不是patch size的整数倍,进行padding
pad_input = (H % self.patch_size[0] != 0) or (W % self.patch_size[1] != 0)
if pad_input:
# 图像的W方向的右侧padding H方向的下方padding
# Pad (w_left, w_right, h_top, h_bottle, c_front, c_back)
# (左边填充数, 右边填充数, 上边填充数, 下边填充数, 前边填充数,后边填充数)
x = F.pad(x, (0, self.patch_size[1] - W % self.patch_size[1],
0, self.patch_size[0] - H % self.patch_size[0],
0, 0))
# down-sample 下采样率为patch size的大小
x = self.proj(x)
_, _, H, W = x.shape
# flatten [B, C, H, W] -> [B, C, HW]
# transpose [B, C, HW] -> [B, HW, C]
x = x.flatten(2).transpose(1, 2)
x = self.norm(x)
return x, H, W
Patch Merging
下采样的作用。通过该模型特征图的H,W缩小一半,通道维度翻倍。使用2*2的窗口大小对图像进行切分,然后分割成不同的小块,在通道维度进行concat,通道维度提高了4倍,过Layer Norm后,使用全连接进行通道维度的调整,调整为2倍。
class patchmerging(nn.Module):
# down-sample
def __init__(self, dim, norm_layer=nn.LayerNorm):
super(patchmerging, self).__init__()
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x, H, W):
# x: [B, HW, C]
B, L, C = x.shape
x = x.view(B, H, W, C)
# padding 如果H,W不是2的整数倍,进行填充
pad_input = (H % 2 == 1) or (W % 2 == 1)
if pad_input:
x = F.pad(x, (0, W % 2, 0, H % 2, 0, 0))
# [B, H, W, C]
x0 = x[:, 0::2, 0::2, :] # [B, H/2, W/2, C] 左上
x1 = x[:, 1::2, 0::2, :] # [B, H/2, W/2, C] 左下
x2 = x[:, 0::2, 1::2, :] # [B, H/2, W/2, C] 右上
x3 = x[:, 1::2, 1::2, :] # [B, H/2, W/2, C] 右下
x = torch.cat([x0, x1, x2, x3], -1) # [B, H/2, W/2, 4*C]
x = x.view(B, -1, 4 * C) # [B, H/2*W/2, 4*C]
x = self.norm(x)
x = self.reduction(x) # [B, H/2*W/2, 4*C] -> [B, H/2*W/2, 2*C]
return x
Swim Transformer Block
1、(shifted)Window Multi-head self-Attention (W-MSA)
Multi-head Self-Attent: 在特征图中对每个像素求q,k,v, 将每个像素求得的q,与特征图中所有像素的key做匹配,然后进行后面softmax,v的操作。每个像素都会和整个特征图的所有像素进行信息的交互。
Window Multi-head self-Attention: 首先对特征图分为一个个窗口,对每个窗口的内部做multi-head self-attention操作。
Shifted Window Multi-head self-Attention:向右和向下移动. 向下取整(M/2), 向下取整(M/2)。M为窗口大小。例如:feature_map = 9, window_size = 3, 则特征图第一行移动到最下面,最左边第一列,移动到最右边。在移动后的特征图中,使用window_size进行分割成一个个小窗口。在窗口内进行W-MSA/SW-MSA计算.
计算SW-MSA需要先创建mask模板,
if self.shift_size > 0.:
# SW-MSA 从上往下 从左往右
# 上面的shift size移动到下面 左边移动右边
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
else:
# W-MSA
shifted_x = x
attn_mask = None
# 指定window大小,重新划分window
def window_partition(x, window_size: int):
# 将feature map(image mask) 按照 window_size的大小 划分成一个个没有重叠的window
B, H, W, C = x.shape
# [B, H//M, W//M, M, C] M: window_size
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
# permute: [B, H//M, M, W//M, M, C] -> [B, H//M, W//M, M, M, C]
# contiguous(): 变为内存连续的数据
# view: [B, H//M, W//M, M, M, C] -> [B * window_num, MH, MW, C] 第一个M为窗口H, 第二个M为窗口W
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
# 将window还原成一个feature map
def window_reverse(windows, window_size: int, H: int, W:int):
# 将窗口还原成一个feature map. H,W 代表分割之前的H,W
# windows: [B * window_num , MH, MW, C]
B = int(windows.shape[0] / (H * W / window_size / window_size))
# view: [B * window_num , MH, MW, C] -> [B, H//M, W//M, M, M, C]
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
# permute: [B, H//M, W//M, M, M, C] -> [B, H//M, M, W//M, M, C]
# view: [B, H//M, M, W//M, M, C] -> [B, H, W, C]
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x

def create_mask(self, x, H, W):
# 保证H、W可以被window size整除 ceil 向上取整
H_padding = int(np.ceil(H / self.window_size)) * self.window_size
W_padding = int(np.ceil(W / self.window_size)) * self.window_size
# 和feature map一样的通道排列顺序
img_mask = torch.zeros((1, H_padding, W_padding, 1), device=x.device) # [B, H, W, C]
# slice 切片 切出每个窗口中分别具有相似元素的位置。如上图例子。feature map=9*9, window_size=3*3
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.window_size),
slice(-self.window_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
# 将mask划分成一个个窗口
# [B * window_num , MH, MW, C]
mask_windows = window_partition(img_mask, self.window_size)
# 将每一个窗口内的元素展平
# [B * window_num * C, MH*MW]
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
# [B * window_num * C, 1, MH*MW] - [B * window_num * C, MH*MW, 1] 广播机制 -> [B * window_num * C, MH*MW, MH*MW]
# mask_windows.unsqueeze(1) 将每个窗口的行向量复制MH*MW次
# mask_windows.unsqueeze(2) 将每个窗口的行向量中每个元素 复制MH*MW次
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
# 同一区域为0 不同区域为非0数。 得到当前窗口中对应某一个像素 所采用的attention mask。
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.)).masked_fill(attn_mask == 0, float(0.0))
return attn_mask
#
class WindowAttention(nn.Module):
# 实现W-MSA SW-MSA
def __init__(self, dim, window_size, num_heads, qkv_bias=True, attn_drop=0., proj_drop=0.):
super(WindowAttention, self).__init__()
self.dim = dim
self.window_size = window_size
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim ** -0.5 # 根号d
self.relative_positive_bias_table = nn.Parameter(
# 长度为[(2*Mh-1) * (2*Mw-1), num_heads]
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)
)
# 生成relative_position_index
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # [2, Mh, Mw]
# 第一行为feature map中每一个像素对应的行标(x)
# 第二行为feature map中每一个像素对应的列标(y)
coords_flatten = torch.flatten(coords, 1) # [2, Mh*Mw] 绝对位置索引
# [2, Mh*Mw, 1] - [2, 1, Mh*Mw]
# [2, Mh*Mw, Mh*Mw] 得到相对位置索引的矩阵。 以每一个像素作为参考点 - 当前feature map/window当中所有的像素点绝对位置索引 = 得到相对位置索引的矩阵
# broadcast coords_flatten[:, :, None] 按w维度 每一行的元素复制
# coords_flatten[:, None, :] 按h维度 每一行元素整体复制
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :]
# permute: 将窗口中按每个像素求得的相对位置索引 组成矩阵
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # [Mh, Mw, 2]
# 二元索引->一元索引
relative_coords[:, :, 0] += self.window_size[0] - 1
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # [Mh*Mw, Mh*Mw]
# 放到模型缓存中
self.register_buffer('relative_position_index', relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
nn.init.trunc_normal_(self.relative_positive_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask: Optional[torch.Tensor] = None):
# [batch_size * num_windows, Mh*Mw, total_embed_dim]
B_, N, C = x.shape
# qkv: -> [batch_size * num_windows, Mh*Mw, 3 * total_embed_dim]
# reshape: -> [batch_size * num_windows, Mh*Mw, 3, num_heads, embed_dim_per_head]
# permute: -> [3, batch_size * num_windows, num_heads, Mh*Mw, embed_dim_per_head]
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
# [batch_size * num_windows, num_heads, Mh*Mw, embed_dim_per_head]
q, k, v = qkv.unbind(0)
q = q * self.scale
# transpose: -> [batch_size * num_windows, num_heads,embed_dim_per_head, Mh*Mw]
# @: multiply: -> [batch_size * num_windows, num_heads, Mh*Mw, Mh*Mw]
attn = (q @ k.transpose(-2, -1))
# self.relative_positive_bias_table.view: -> [Mh*Mw*Mh*Mw, num_head] -> [Mh*Mw, Mh*Mw, num_head]
relative_position_bias = self.relative_positive_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1)
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # [num_head, Mh*Mw, Mh*Mw]
# [batch_size * num_windows, num_heads, Mh * Mw, Mh * Mw]
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
# mask: [num_windows, Mh*Mw, Mh*Mw]
num_window = mask.shape[0]
# view: [batch_size, num_windows, num_heads, Mh * Mw, Mh * Mw]
# mask: [1, num_windows, 1, Mh*Mw, Mh*Mw]
attn = attn.view(B_ // num_window, num_window, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
# [batch_size*num_windows, num_heads, Mh * Mw, Mh * Mw]
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
# @: [batch_size*num_windows, num_heads, Mh * Mw, embed_dim_per_head]
# transpose: [batch_size*num_windows, Mh * Mw, num_heads, embed_dim_per_head]
# reshape: [num_windows, Mh * Mw, num_heads*embed_dim_per_head]
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
2、MLP
和传统自注意力机制使用的MLP结构相同。
class MLP(nn.Module):
def __init__(self, in_features, hidden_features=None, act=nn.GELU, drop=0.):
super(MLP, self).__init__()
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act()
self.fc2 = nn.Linear(hidden_features, in_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
3、Swim Transformer Block整体结构
class SwimTransformerBlock(nn.Module):
def __init__(self, dim, num_heads, window_size=7, shift_size=0., mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0., drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super(SwimTransformerBlock, self).__init__()
self.dim = dim
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim=dim, window_size=(self.window_size, self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=drop
)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = (int(dim * mlp_ratio))
self.mlp = MLP(in_features=dim, hidden_features=mlp_hidden_dim, act=act_layer, drop=drop)
def forward(self, x, attn_mask):
H, W = self.H, self.W # feature map H W
B, L, C = x.shape # L = H * W
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
x_r = (self.window_size - W % self.window_size) % self.window_size
x_d = (self.window_size - H % self.window_size) % self.window_size
x = F.pad(x, (0, 0, 0, x_r, 0, x_d))
_, Hp, Wp, _ = x.shape # Hp Wp代表padding后的H W
if self.shift_size > 0.:
# SW-MSA 从上往下 从左往右
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2)) # 上面的shift size移动到下面 左边移动右边
else:
# W-MSA
shifted_x = x
attn_mask = None
# 特征图切成小窗口
x_windows = window_partition(shifted_x, self.window_size) # [B * window_num, MH, MW, C]
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # [B * window_num, MH*MW, C]
# W-MSA SW-MSA
attn_windows = self.attn(x_windows, mask=attn_mask)
# 小窗口合并成特征图
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C) # [B * window_num, MH, MW, C]
shifted_x = window_reverse(attn_windows, self.window_size, Hp, Wp) # [B, H, W, C]
# SW-MSA后还原数据 从下往上 从右往左
if self.shift_size > 0:
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = shifted_x
# 移除padding
if x_r > 0 or x_d > 0:
x = x[:, :H, :W, :].contiguous()
x = x.view(B, H * W, C)
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
构建模型的stage(Swim Transformer Block + Patch Merging)
class BasicLayer(nn.Module):
# 每个stage的实现
def __init__(self, dim, depth, num_heads, window_size, mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0., drop_path=0., norm_layer=nn.LayerNorm, downsample=None):
super(BasicLayer, self).__init__()
self.dim = dim
self.depth = depth
self.window_size = window_size
self.shift_size = window_size // 2 # 窗口大小/2 向下取整 窗口向右向下移动的步长
self.blocks = nn.ModuleList([
SwimTransformerBlock(
dim=dim, num_heads=num_heads, window_size=window_size, shift_size=0 if (i % 2 == 0) else self.shift_size,
mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, drop=drop, attn_drop=attn_drop, drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer) for i in range(depth)
])
if downsample is not None:
self.downsample = downsample(dim=dim, norm_layer=norm_layer)
else:
self.downsample = None
mask_windows = window_partition(img_mask, self.window_size) # [B * window_num , MH, MW, C]
mask_windows = mask_windows.view(-1, self.window_size * self.window_size) # [B * window_num * C, MH*MW]
# [B * window_num * C, 1, MH*MW] - [B * window_num * C, MH*MW, 1] 广播机制 -> [B * window_num * C, MH*MW, MH*MW]
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.)).masked_fill(attn_mask == 0, float(0.0))
return attn_mask
def forward(self, x, H, W):
attn_mask = self.create_mask(x, H, W) # [B * window_num * C, MH*MW, MH*MW]
for blk in self.blocks:
blk.H, blk.W = H, W
x = blk(x, attn_mask)
if self.downsample is not None:
x = self.downsample(x, H, W)
H, W = (H + 1) // 2, (W + 1) // 2
return x, H, W
Swim Transform做分类的最终构建
class SwimTransformer(nn.Module):
def __init__(self, downsapmle_size=4, in_channels=3, num_classes=1000, embed_dim=96, depths=(2, 2, 6, 2), num_heads=(3, 6, 12, 24), window_size=7, mlp_ratio=4.,
qkv_bias=True, drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1, norm_layer=nn.LayerNorm, patch_norm=True, **kwargs):
super(SwimTransformer, self).__init__()
self.num_classes = num_classes
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.patch_norm = patch_norm
# stage4 输出的特征矩阵的Channel
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
self.mlp_ratio = mlp_ratio
self.patch_embed = patchEmbed(patch_size=downsapmle_size, in_channels=in_channels, embed_dim=embed_dim, norm_layer=norm_layer if self.patch_norm else None)
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
layers = BasicLayer(dim=int(embed_dim * 2 ** i_layer),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])], norm_layer=norm_layer, downsample=patchmerging if (i_layer < self.num_layers - 1) else None)
self.layers.append(layers)
# classification
self.norm = norm_layer(self.num_features)
self.avgpool = nn.AdaptiveAvgPool1d(1)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
def _init_weights(self, m):
if isinstance(m, nn.Linear):
nn.init.trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward(self, x):
# [B, L, C]
x, H, W = self.patch_embed(x)
x = self.pos_drop(x)
for layer in self.layers:
x, H, W = layer(x, H, W)
x = self.norm(x)# [B, L, C]
x = self.avgpool(x.transpose(1, 2)) # [B, C, 1]
x = torch.flatten(x, 1)
x = self.head(x)
return x
网络结构整体代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from timm.models.layers import DropPath
from typing import Optional
class patchEmbed(nn.Module):
# 将图片分割成不重叠的小patch 尺寸下采样尺寸为patch size的大小
def __init__(self, patch_size=4, in_channels=3, embed_dim=96, norm_layer=None):
super(patchEmbed, self).__init__()
patch_size = (patch_size, patch_size)
self.patch_size = patch_size
self.in_channels = in_channels
self.embed_dim = embed_dim
self.proj = nn.Conv2d(in_channels, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
_, _, H, W = x.shape
# padding 如果输入image的H, W不是patch size的整数倍,进行padding
pad_input = (H % self.patch_size[0] != 0) or (W % self.patch_size[1] != 0)
if pad_input:
# 图像的W方向的右侧padding H方向的下方padding
# Pad (w_left, w_right, h_top, h_bottle, c_front, c_back) (左边填充数, 右边填充数, 上边填充数, 下边填充数, 前边填充数,后边填充数)
x = F.pad(x, (0, self.patch_size[1] - W % self.patch_size[1],
0, self.patch_size[0] - H % self.patch_size[0],
0, 0))
# down-sample 下采样率为patch size的大小
x = self.proj(x)
_, _, H, W = x.shape
# flatten [B, C, H, W] -> [B, C, HW]
# transpose [B, C, HW] -> [B, HW, C]
x = x.flatten(2).transpose(1, 2)
x = self.norm(x)
return x, H, W
class patchmerging(nn.Module):
# down-sample
def __init__(self, dim, norm_layer=nn.LayerNorm):
super(patchmerging, self).__init__()
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x, H, W):
# x: [B, HW, C]
B, L, C = x.shape
x = x.view(B, H, W, C)
# padding 如果H,W不是2的整数倍,进行填充
pad_input = (H % 2 == 1) or (W % 2 == 1)
if pad_input:
x = F.pad(x, (0, W % 2, 0, H % 2, 0, 0))
# [B, H, W, C]
x0 = x[:, 0::2, 0::2, :] # [B, H/2, W/2, C] 左上
x1 = x[:, 1::2, 0::2, :] # [B, H/2, W/2, C] 左下
x2 = x[:, 0::2, 1::2, :] # [B, H/2, W/2, C] 右上
x3 = x[:, 1::2, 1::2, :] # [B, H/2, W/2, C] 右下
x = torch.cat([x0, x1, x2, x3], -1) # [B, H/2, W/2, 4*C]
x = x.view(B, -1, 4 * C) # [B, H/2*W/2, 4*C]
x = self.norm(x)
x = self.reduction(x) # [B, H/2*W/2, 4*C] -> [B, H/2*W/2, 2*C]
return x
class MLP(nn.Module):
def __init__(self, in_features, hidden_features=None, act=nn.GELU, drop=0.):
super(MLP, self).__init__()
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act()
self.fc2 = nn.Linear(hidden_features, in_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class WindowAttention(nn.Module):
# 实现W-MSA SW-MSA
def __init__(self, dim, window_size, num_heads, qkv_bias=True, attn_drop=0., proj_drop=0.):
super(WindowAttention, self).__init__()
self.dim = dim
self.window_size = window_size
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim ** -0.5 # 根号d
self.relative_positive_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads) # 长度为[(2*Mh-1) * (2*Mw-1), num_heads]
)
# 生成relative_position_index
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # [2, Mh, Mw]
coords_flatten = torch.flatten(coords, 1) # [2, Mh*Mw] 绝对位置索引
# [2, Mh*Mw, 1] - [2, 1, Mh*Mw]
# [2, Mh*Mw, Mh*Mw] 得到相对位置索引 以每一个像素作为参考点 - 当前feature map/window当中所有的像素点绝对位置索引 = 得到相对位置索引的矩阵
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :]
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # [Mh, Mw, 2]
# 二元索引->一元索引
relative_coords[:, :, 0] += self.window_size[0] - 1
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # [Mh*Mw, Mh*Mw]
self.register_buffer('relative_position_index', relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
nn.init.trunc_normal_(self.relative_positive_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask: Optional[torch.Tensor] = None):
# [batch_size * num_windows, Mh*Mw, total_embed_dim]
B_, N, C = x.shape
# qkv: -> [batch_size * num_windows, Mh*Mw, 3 * total_embed_dim]
# reshape: -> [batch_size * num_windows, Mh*Mw, 3, num_heads, embed_dim_per_head]
# permute: -> [3, batch_size * num_windows, num_heads, Mh*Mw, embed_dim_per_head]
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
# [batch_size * num_windows, num_heads, Mh*Mw, embed_dim_per_head]
q, k, v = qkv.unbind(0)
q = q * self.scale
# transpose: -> [batch_size * num_windows, num_heads,embed_dim_per_head, Mh*Mw]
# @: multiply: -> [batch_size * num_windows, num_heads, Mh*Mw, Mh*Mw]
attn = (q @ k.transpose(-2, -1))
# self.relative_positive_bias_table.view: -> [Mh*Mw*Mh*Mw, num_head] -> [Mh*Mw, Mh*Mw, num_head]
relative_position_bias = self.relative_positive_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1)
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # [num_head, Mh*Mw, Mh*Mw]
# [batch_size * num_windows, num_heads, Mh * Mw, Mh * Mw]
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
# mask: [num_windows, Mh*Mw, Mh*Mw]
num_window = mask.shape[0]
# view: [batch_size, num_windows, num_heads, Mh * Mw, Mh * Mw]
# mask: [1, num_windows, 1, Mh*Mw, Mh*Mw]
attn = attn.view(B_ // num_window, num_window, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
# [batch_size*num_windows, num_heads, Mh * Mw, Mh * Mw]
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
# @: [batch_size*num_windows, num_heads, Mh * Mw, embed_dim_per_head]
# transpose: [batch_size*num_windows, Mh * Mw, num_heads, embed_dim_per_head]
# reshape: [num_windows, Mh * Mw, num_heads*embed_dim_per_head]
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class SwimTransformerBlock(nn.Module):
def __init__(self, dim, num_heads, window_size=7, shift_size=0., mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0., drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super(SwimTransformerBlock, self).__init__()
self.dim = dim
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim=dim, window_size=(self.window_size, self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=drop
)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = (int(dim * mlp_ratio))
self.mlp = MLP(in_features=dim, hidden_features=mlp_hidden_dim, act=act_layer, drop=drop)
def forward(self, x, attn_mask):
H, W = self.H, self.W # feature map H W
B, L, C = x.shape # L = H * W
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
x_r = (self.window_size - W % self.window_size) % self.window_size
x_d = (self.window_size - H % self.window_size) % self.window_size
x = F.pad(x, (0, 0, 0, x_r, 0, x_d))
_, Hp, Wp, _ = x.shape # Hp Wp代表padding后的H W
if self.shift_size > 0.:
# SW-MSA 从上往下 从左往右
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2)) # 上面的shift size移动到下面 左边移动右边
else:
# W-MSA
shifted_x = x
attn_mask = None
# 特征图切成小窗口
x_windows = window_partition(shifted_x, self.window_size) # [B * window_num, MH, MW, C]
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # [B * window_num, MH*MW, C]
# W-MSA SW-MSA
attn_windows = self.attn(x_windows, mask=attn_mask)
# 小窗口合并成特征图
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C) # [B * window_num, MH, MW, C]
shifted_x = window_reverse(attn_windows, self.window_size, Hp, Wp) # [B, H, W, C]
# SW-MSA后还原数据 从下往上 从右往左
if self.shift_size > 0:
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = shifted_x
# 移除padding
if x_r > 0 or x_d > 0:
x = x[:, :H, :W, :].contiguous()
x = x.view(B, H * W, C)
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
def window_partition(x, window_size: int):
# 将feature map(image mask) 按照 window_size的大小 划分成一个个没有重叠的window
B, H, W, C = x.shape
# [B, H//M, W//M, M, C] M: window_size
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
# permute: [B, H//M, M, W//M, M, C] -> [B, H//M, W//M, M, M, C]
# contiguous(): 变为内存连续的数据
# view: [B, H//M, W//M, M, M, C] -> [B * window_num, MH, MW, C] 第一个M为窗口H, 第二个M为窗口W
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
def window_reverse(windows, window_size: int, H: int, W:int):
# 将窗口还原成一个feature map. H,W 代表分割之前的H,W
# windows: [B * window_num , MH, MW, C]
B = int(windows.shape[0] / (H * W / window_size / window_size))
# view: [B * window_num , MH, MW, C] -> [B, H//M, W//M, M, M, C]
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
# permute: [B, H//M, W//M, M, M, C] -> [B, H//M, M, W//M, M, C]
# view: [B, H//M, M, W//M, M, C] -> [B, H, W, C]
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
class BasicLayer(nn.Module):
# 每个stage的实现
def __init__(self, dim, depth, num_heads, window_size, mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0., drop_path=0., norm_layer=nn.LayerNorm, downsample=None):
super(BasicLayer, self).__init__()
self.dim = dim
self.depth = depth
self.window_size = window_size
self.shift_size = window_size // 2 # 窗口大小/2 向下取整 窗口向右向下移动的步长
self.blocks = nn.ModuleList([
SwimTransformerBlock(
dim=dim, num_heads=num_heads, window_size=window_size, shift_size=0 if (i % 2 == 0) else self.shift_size,
mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, drop=drop, attn_drop=attn_drop, drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer) for i in range(depth)
])
if downsample is not None:
self.downsample = downsample(dim=dim, norm_layer=norm_layer)
else:
self.downsample = None
def create_mask(self, x, H, W):
# 保证H、W可以被window size整除 ceil 向上取整
H_padding = int(np.ceil(H / self.window_size)) * self.window_size
W_padding = int(np.ceil(W / self.window_size)) * self.window_size
# 和feature map一样的通道排列顺序
img_mask = torch.zeros((1, H_padding, W_padding, 1), device=x.device) # [B, H, W, C]
# slice 切片 切出每个窗口中分别具有相似元素的位置。
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.window_size),
slice(-self.window_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # [B * window_num , MH, MW, C]
mask_windows = mask_windows.view(-1, self.window_size * self.window_size) # [B * window_num * C, MH*MW]
# [B * window_num * C, 1, MH*MW] - [B * window_num * C, MH*MW, 1] 广播机制 -> [B * window_num * C, MH*MW, MH*MW]
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.)).masked_fill(attn_mask == 0, float(0.0))
return attn_mask
def forward(self, x, H, W):
attn_mask = self.create_mask(x, H, W) # [B * window_num * C, MH*MW, MH*MW]
for blk in self.blocks:
blk.H, blk.W = H, W
x = blk(x, attn_mask)
if self.downsample is not None:
x = self.downsample(x, H, W)
H, W = (H + 1) // 2, (W + 1) // 2
return x, H, W
class SwimTransformer(nn.Module):
def __init__(self, downsapmle_size=4, in_channels=3, num_classes=1000, embed_dim=96, depths=(2, 2, 6, 2), num_heads=(3, 6, 12, 24), window_size=7, mlp_ratio=4.,
qkv_bias=True, drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1, norm_layer=nn.LayerNorm, patch_norm=True, **kwargs):
super(SwimTransformer, self).__init__()
self.num_classes = num_classes
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.patch_norm = patch_norm
# stage4 输出的特征矩阵的Channel
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
self.mlp_ratio = mlp_ratio
self.patch_embed = patchEmbed(patch_size=downsapmle_size, in_channels=in_channels, embed_dim=embed_dim, norm_layer=norm_layer if self.patch_norm else None)
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
layers = BasicLayer(dim=int(embed_dim * 2 ** i_layer),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])], norm_layer=norm_layer, downsample=patchmerging if (i_layer < self.num_layers - 1) else None)
self.layers.append(layers)
# classification
self.norm = norm_layer(self.num_features)
self.avgpool = nn.AdaptiveAvgPool1d(1)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
def _init_weights(self, m):
if isinstance(m, nn.Linear):
nn.init.trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward(self, x):
# [B, L, C]
x, H, W = self.patch_embed(x)
x = self.pos_drop(x)
for layer in self.layers:
x, H, W = layer(x, H, W)
x = self.norm(x)# [B, L, C]
x = self.avgpool(x.transpose(1, 2)) # [B, C, 1]
x = torch.flatten(x, 1)
x = self.head(x)
return x
if __name__ == '__main__':
x = torch.randn(1, 3, 224, 224)
model = SwimTransformer()
out = model(x)
print(out.shape)