【KBQA-2】 Learning To Retrieve Prompts for In-Context Learning
前言
本文是对文章 Learning To Retrieve Prompts for In-Context Learning (NAACL, 2022) 的阅读笔记,论文代码:链接。
文章目录
- 1. in-context learning
- 2. 本文工作
- 3. 模型训练和推理
-
-
- 1)如何产生标记数据
- 2)如何给候选集合打分
- 3)训练打分模型
- 4) 训练推断模型
-
- 4. 实验
-
-
- 1)数据集
- 2)评价指标
- 3)基线和标准做法
- 4)模型测试的两种模式
- 5)实验结果分析
-
- LM - as - a - service
- LM - as - a - proxy
-
- 5. 总结
- 6. 相关知识
1. in-context learning
(此介绍中部分是转载)
in-context learning 是2020年下半年兴起的一个概念。以下是incontext learning的逻辑图。
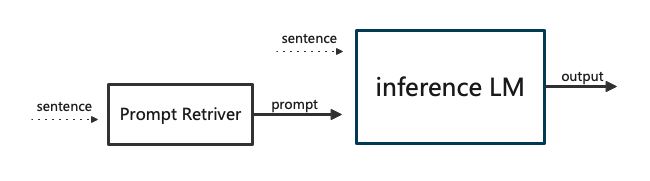
in-context learning 是一种新的训练模式。在进行测试的时候,将提示(通常是几个与输入相似的example)与输入句子一起输入,然后得到输出。
之前的模型学习到的是一个类似函数的映射,给定输入x,得到输出 y=f(x)。而 in-context learning 学到的不是一个单纯的映射函数,而是要掌握给出答案的 “能力”。也就是,这个模型,通过提示,知道了答案应该是什么样的。
in-context使得模型有着天然的泛化能力和实际部署的潜质,在很多领域,通过合理的构建prompt和选取example,in-context的水平已经接近于比他自己小但是本身不小的模型的能力了(比如说你在GPT3 175B上做in-context learning的性能基本和T5-large 770M全数据训练finetune持平)。追平这件事可以说是大模型落地的福音。
得到的 prompt 将会和测试句子拼接,作为测试句子的前缀输入。如果得到的 prompt 良好,那么通过推断模型的解码就应该得到目标输出。
效果很大程度上取决于 prompt 的质量。
In-context learning is a recent paradigm in natural language understanding, where a large pre-trained language model (LM) observes a test instance and a few training examples as its input, and directly decodes the output without any update to its parameters.
An attractive property of in-context learning is that it provides a single model for multiple language understanding tasks.
2. 本文工作
在过去的工作中,对于 prompt 的选取往往基于相似度,无论是直接通过相似度计算选取,或者训练专门的提取器来提取,都是依据相似度。
本文中不依靠相似度,而是利用一个语言模型来给提示打分,本文认为利用语言模型给提示打分是优于之前的相似度的。
3. 模型训练和推理
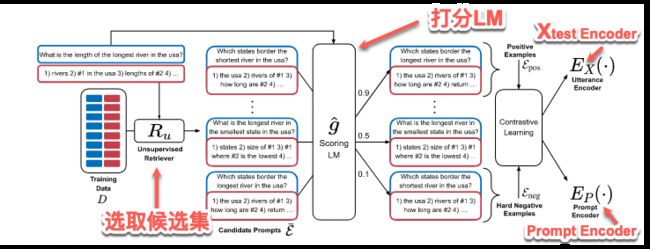
1)如何产生标记数据
在训练集中针对每一个训练数据有哪些最适合作为其 prompt 的方法,代价太高。本文针对每一个训练用例,先从测试集中选出一个候选集,然后在候选集中选取 positive examples 和 negative examples,标记之后用于对比学习。
为了选择一个好的候选集,使用无监督的提取器。
| 提取器 | 来源 | 介绍 |
|---|---|---|
| BM25 | Robertson and Zaragoza, 2009 | a sparse retriever that relies on surface text similarity |
| SBERT | Reimers and Gurevych, 2019 | based on dense sentence encoding |
For both, we experimented with passing the retriever the training pair (x, y) or the target sequence y only, and found that using y leads to slightly higher performance.
对于这两种方法,我们都尝试只给检索器传递训练对(x, y)或目标序列y,发现使用y会导致略高的性能。
2)如何给候选集合打分
针对训练集中的每一个数据对(x,y),对于其选出的候选集合 ϵ ˉ = { e ˉ 1 , e ˉ 2 , … , e ˉ L } \bar{\epsilon} = \{\bar{e}_1, \bar{e}_2, \dots, \bar{e}_L\} ϵˉ={eˉ1,eˉ2,…,eˉL},对集合中的每一个候选都利用打分模型进行打分,打分模型如下:![]()
对于候选集中的所有实例,与对应的训练数据(x,y)相似度越高得分越高。最终取候选集中的 top-k 作为 positive examples ,其中的 bottom-k 作为 negative examples 。
3)训练打分模型
训练过程类似DPR (Karpukhin et al., 2020)
得到的输出
- E x ( . ) E_x(.) Ex(.): input encoder, receives the sequence of input tokens
- E p ( . ) E_p(.) Ep(.): prompt encoder, receives a candidate prompt, namely, a concatenation of the tokens in an input-output pair
所有的encoder 都是使用 BERT-base 初始化,所有的输出向量都是以 CLS token 的形式给出。
一个训练实例的表示 ![]()
其中,batch size 是 B。 x i x_i xi 是测试, e i + e_i^+ ei+是从 x i x_i xi 对应的 正例集 ϵ p o s \epsilon_{pos} ϵpos 中抽样得到,其余 2 B − 1 2B-1 2B−1 个均是 x i x_i xi 的负例,在这些负例中,有一个从 x i x_i xi 对应的 负例集 ϵ n e g \epsilon_{neg} ϵneg 中抽样得到,其余 2 B − 2 2B-2 2B−2 个中,有 B − 1 B-1 B−1 个是同一 batch 的其他实例的正例,有 B − 1 B-1 B−1 个是同一 batch 的其他实例的负例。(是每个实例各取一个,还是总共取 B − 1 B-1 B−1 个?)
定义一个 input 与一个 input-output pair 的相似度为![]()
进而使用对比学习的目标函数:

4) 训练推断模型
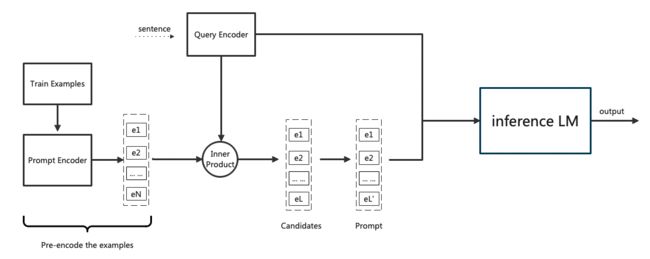
在训练了输入编码器和提示编码器之后,我们使用FAISS对整个训练样本集进行了EP(·)编码。
Faiss是Facebook AI团队开源的针对聚类和相似性搜索库,为稠密向量提供高效相似度搜索和聚类,支持十亿级别向量的搜索,是目前最为成熟的近似近邻搜索库。
测试的时候,将 x t e s t x_{test} xtest 编码为 E X ( x t e s t ) E_X(x_{test}) EX(xtest),然后从训练数据集中选取 L 个最相似的训练数据,然后将这些编码后的训练数据按照其与编码后的测试数据的内积值的大小顺序排列。构成的提示集 P = ( e 1 , … , e L ) \mathcal{P} = (e_1, \dots, e_L) P=(e1,…,eL)
L的大小如何确定?
∑ i = 1 L ′ ∣ e i ∣ + ∣ x t e s t ∣ + ∣ y ′ ∣ ≤ C \sum_{i=1}^{L^{\prime}}|e_i| + |x_{test}| + |y^{\prime}| \le C ∑i=1L′∣ei∣+∣xtest∣+∣y′∣≤C 且 L ′ ≤ L L^{\prime} \le L L′≤L
其中, C C C是 inference model 可以接受的最大 token 数, ∣ y ′ ∣ |y^{\prime}| ∣y′∣是期望输出的最大长度。在满足以上条件的情况下,取最大的 L ′ L^{\prime} L′ 。
最终,以 greedy decoding 的方式输出为 g ( [ e L ′ ; e L ′ − 1 ; … ; e 1 ; x t e s t ] ) g([e_{L^{\prime}}; e_{L^{\prime}-1};\dots;e_1;x_{test}]) g([eL′;eL′−1;…;e1;xtest])
prompt 是作为 x t e s t x_{test} xtest 的前缀的,也就是说,在它的前缀中,单词的排列方式是按照概率从大到小来的。
greedy decoding,每次选择概率值最大的对应的单词。
4. 实验
模型的两大优势情况:
- 当打分模型比推断模型小时,这种小体量的打分模型非常的高效轻量
- 当打分模型和推断模型是同一个模型时,即使两个模型相同,此方法也是适用的,当我们无法得到模型参数的时候,这个模型的优势就体现的更加明显。
1)数据集
模型将针对三个 Seq2seq 任务进行测试:
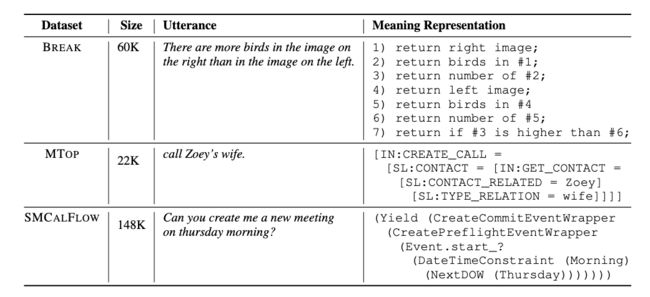
- B R E A K B_{REAK} BREAK: 将复杂的自然语言问题映射到基于语言的意义表示的数据集,其中问题被分解为原子步骤的有序列表。
- M T O P MT_{OP} MTOP: 语义分析数据集,专注于面向任务的对话,其中命令映射到11个域的复杂嵌套查询。
- S M C A L F L O W SMC_{AL}F_{LOW} SMCALFLOW: 一个面向任务的大型英语数据集,涵盖日历、天气、地点和人员等任务。语义表示是一个数据流程序,它包括API调用、函数组合和复杂的约束。
2)评价指标
EM: Exact Match, 评估推断语言模型的输出和参考输出是否相同。
NEM: Normalized Exact Match, 通过一个基于规则的程序将预测结果和目标结果归一化,然后在归一化后的结果上计算正确字符串匹配。
LF-EM(logical form - exact match): 评估两个含义表达式是否在语义上等价。
3)基线和标准做法
无监督模型
| 基线模型 | 描述 |
|---|---|
| RANDOM | 随机从训练集中抽样出 prompt |
| SBERT | 利用 paraphrase-mpnet-base-v2 来编码测试语料,并且从训练集中抽取跟测试语料最相似的例子作为 prompt |
| BM25 | 经典的 sparse retrieval 方法,是 TF-IDF 的拓展,用其抽取 prompt |
| BRUTE FORCE | 从训练集中随机抽取 200 个训练实例 (x,y) 作为候选集,然后比较 x 与 x t e s t x_{test} xtest 的相似度,选择相似度高的作为 prompt |
有监督模型
有监督基线测试通用的模版:
- 用BM25抽候选集,候选集大小为 L=50。
- 使用一些打分函数选出正例集和负例集,正例和负例集的大小均为5。
- 不同的有监督方法不同在于其自身的打分函数。
| 基线模型 | 描述 |
|---|---|
| DR-BM25 | 使用BM25本身的打分函数来打分,训练的分类器是 dense retriever(向量检索) |
| CASE-BASED REASONING(CBR) | 采用 F1 值弱标记数据,F1 值根据输出 y i y_i yi 和 y j y_j yj 中的 token 集合计算 |
| EFFICIENT PROMPT RETRIEVAL | 本文的模型,使用 R u ( ( x , y ) , D ) \mathcal{R}_u((x,y),\mathcal{D}) Ru((x,y),D) 抽取候选集, 使用 GPT-NEO 打分 |
标准模型
| 基线模型 | 描述 |
|---|---|
| BM25-ORACLE | 在测试的时候,不依据输入向量和训练集实例向量内积来排序,直接用 BM25 以目标输出为参数寻找最相似的实例组成prompt |
| LM-ORACLE | 在测试的时候,对待每个测试实例就像训练实例一样,利用BM25抽取候选集,然后使用 Scoring LM 打分,最终得到prompt |
4)模型测试的两种模式
(a) LM - as - a - service (scoring LM 和 inference LM 相同)
scoring LM 和 inference LM 都是 GPT-NEO,在BREAK, MTOP, SMACALFLOW 的全部数据上评估。
(b) LM - as - a - proxy (scoring LM 小于 inference LM)
从 GPT-3 和 CODEX 中随机抽取 1000 个实例,在这个子集上进行评估。
模型 ( C = 2048 C = 2048 C=2048)
| scoring LM | inference LM |
|---|---|
| GPT-NEO | GPT-NEO |
| GPT-NEO | GPT-J |
| GPT-NEO | GPT-3 |
| GPT-NEO | CODEX |
5)实验结果分析
LM - as - a - service
Table 2
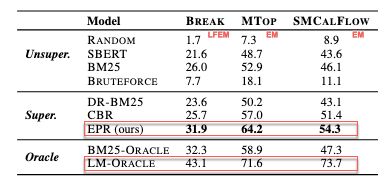
- 每一列来看,EPR都是最好的
- BM25 超过 SBERT 说明利用BM25 来提取候选集比用 SBERT 好。
- 随机抽取效果很差
- BruteForce 表现很差可能是因为随机抽取 200 候选覆盖面太窄,信息太少
- EPR 的效果和 BM25-ORACLE 不相上下,甚至更好,说明了这种用语言模型打分的形式比用文本表面的相似度要更好。
- LM-ORACLE 的效果比 EPR 好,说明打分语言模型提供的监督很强,依照此监督信号训练出的更好的提取器可以提升表现。
- Table 3 佐证了table 2 的结论
Table 4
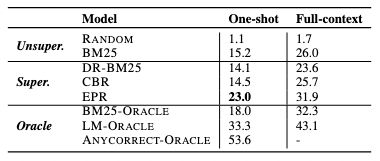
one-shot setup 测试:prompt 只取得分最高的那个例子
ANYCORRECT-ORACLE:测试 BM25提供的所有候选,是否在其提示下得到了正确的输出。
- 通过实验发现,得到了很好的效果,EPR 比 CBR 高了 8.5%,比BM25-ORACLE 也高了5%。
- ANYCORRECT-ORACLE 的得分高于 50%,说明 BM25 提供的候选质量很高。同时,它的得分比 LM - ORACLE 高很多,说明通过更好的 scoring model,可以提升整体表现。
LM - as - a - proxy
scoring LM 是GPT-NEO,inference LM 是一个更大的 LM。
Table 5

相较于其他模型,EPR基本都有一定提升
同时使用 GPT-J 作为打分LM和推理LM,31.5 -> 33.6,对CODEX来说 29.5 -> 29.3。因此,用更小的 LM(GPT-NEO)效率更高。
使用不同的模型作为 推理LM 时,表现有所不同,这是因为预训练模型的差异。
Table 6
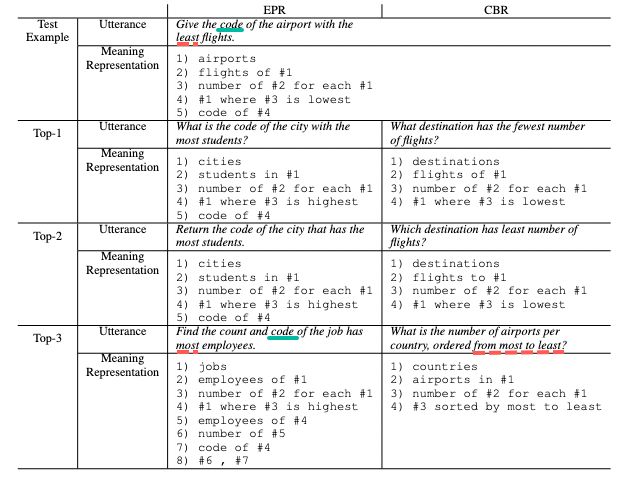
主要观察第三个例子,CBR 提取的没有出现 code,且没有体现出最多或者最少。
Figure 3

对利用 EPR 模型从 BREAK 数据集中学到的 embeddings 进行可视化展示。
t-SNE 是一种非线性降维算法,非常适用于高维数据降维到 2 维或者 3 维,进行可视化。在实际应用中,t-SNE很少用于降维,主要用于可视化
OPTICS算法也是一种基于密度的聚类算法
对聚类的研究表明,EPR既能捕捉词汇相似性,又能捕捉结构相似性。
Table 7

研究输出的结果究竟是直接复制了 prompt 中的输出,还是说组合了 prompt 中不同例子的输出。
定义了两种复制
- exact copying:产生的输出完全匹配 prompt 中的一个实例的输出。
- abstract copying:输出的结构是否和 prompt 中的某个实例的结构相同。对目标输出以及 prompt 中实例的逻辑形式,将其出现的实体和函数参数用 [masked] 标志替换。在替换之后,如果目标输出在 prompt 的实例中出现,那么就产生了复制。
- 在 MTOP 和 SMACL 数据集上,Abstract copying 达到了80%以上,而且,出现了 copy 现象的部分准确率大大高于未出现 copy 现象的部分。可随机举例。
- 同时值得关注的是,对于没有出现copy现象的部分,其准确率也难以忽视,这说明输出生成了新的结构。
Figure 4
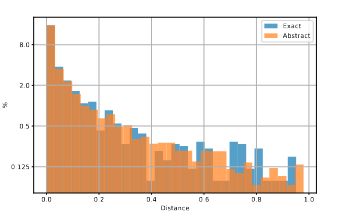
求证,当出现复制情况的时候,容易被复制的是高得分的实例,还是说是全局性的。
为了得到此数据,将出现复制情况的实例对应的 prompt 中的实例定义一个举例,按照得分从高到底排列,然后除以提示的数量,就得到了一个归一化的距离,通过实验发现,距离越近,也就是得分越高的实例被复制的概率越高。
5. 总结

6. 相关知识
dense retriever & sparse retriever
CLS编码介绍