Numpy: ndarray的索引
前言
在我第一次接触到ndarray这一数据结构时,其索引的使用与Python列表的相似而其结果的差异让我很困惑,我想这也是很多新手会遇到的问题。所以弄懂ndarray的索引是十分重要的。
PS: 这篇文章是我写的numpy知识总结的一部分,完整知识总结入口在这篇文章,在这篇文章里我搭建了numpy的基础知识框架,非常适合入门。
1. 基础索引与切片
与Python内键列表索引相似所引起的疑惑或不适在一维情况和二维情况均存在,将其分开说明。
1) 一维情况
在一维情况下,ndarray索引的使用语法与Python列表完全相同,不同之处在于其对数据复制的处理。
在Python列表中,索引创建的切片是对列表内容创建了一份副本,在切片上的任何修改对原列表没有影响。
在ndarray数组中,索引创建的切片是原数组的视图,对切片的修改同时会反映在原数组上;如果创建切片的副本,要显式的使用ndarray.copy()函数。
为什么会有这种差别?
这种差别与numpy处理的数据类型以及其对效率的要求相关。numpy数组往往都是很大的,如果创建一个切片就做一次复制,这对内存来说是一个灾难,并且处理速度会毫无疑问的大打折扣。
【例1】ndarray一维索引与Python列表索引差别展示
In [239]: arr = np.arange(5)
In [240]: arr
Out[240]: array([0, 1, 2, 3, 4])
In [241]: arr1 = arr[3:]
In [242]: arr1
Out[242]: array([3, 4])
#修改切片arr1的值
In [243]: arr1[0] = 2
In [244]: arr1
Out[244]: array([2, 4])
#原数组值被改变
In [245]: arr
Out[245]: array([0, 1, 2, 2, 4])
【例2】ndarray.copy()函数使用示例
In [245]: arr
Out[245]: array([0, 1, 2, 2, 4])
In [246]: arr2 = arr[3:].copy()
In [247]: arr2
Out[247]: array([2, 4])
#修改副本的值
In [248]: arr2[0] = 11
#副本值被改变
In [249]: arr2
Out[249]: array([11, 4])
#原数组值不变
In [250]: arr
Out[250]: array([0, 1, 2, 2, 4])
2) 二维情况
我们知道,利用列表的列表可以产生二维的ndarray数组,列表中的每一个子列表相当于数组的一行。在数据进行索引时,与Python列表的列表有相同也有不同。
相同点:
- 使用单个整数索引时,返回的均是一个子列表(数组,原数组的一行);(【例1】)对于更高维的数组,通过这个方法可以实现降维;
- 可以使用嵌套索引取得元素值。(【例2】)
不同点:
- ndarray通过传入多个索引值可以实现不同数据区域选取,Python列表的索引值只能是整数,无法做类似的选取。(【例3】)
【例1】相同点1: 单个索引值取出一行
In [252]: num_list = [[1,2,3],[4,5,6],[7,8,9]]
In [253]: num_list[0]
Out[253]: [1, 2, 3]
In [255]: arr = np.array(num_list)
In [256]: arr[0]
Out[256]: array([1, 2, 3])
【例2】相同点2:迭代索引取出元素值
In [259]: num_list
Out[259]: [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
In [260]: arr
Out[260]:
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
In [261]: num_list[0][0]
Out[261]: 1
In [262]: arr[0][0]
Out[262]: 1
【例3】不同点:ndarray二维数组索引
In [260]: arr
Out[260]:
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
In [262]: arr[0][0]
Out[262]: 1
#ndarray的特有索引方式
In [263]: arr[0,0]
Out[263]: 1
In [265]: arr[1:,:]
Out[265]:
array([[4, 5, 6],
[7, 8, 9]])
更多示例:
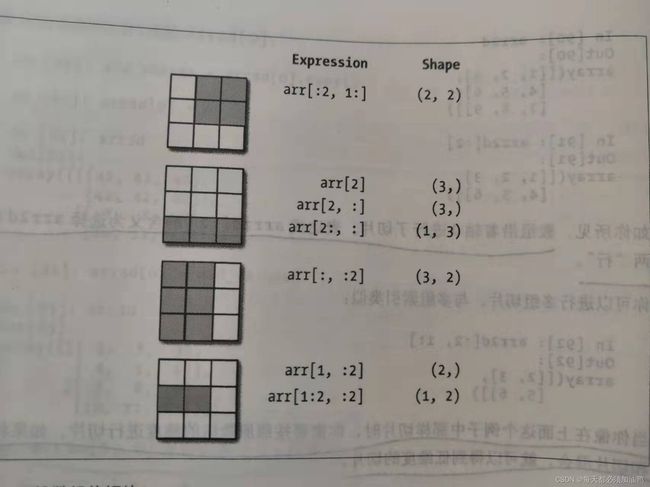
2. 布尔索引
在索引ndarray数组时,可以传入布尔值数组作为索引,可以使用布尔值索引以及其他索引混合进行切片。
通过对普通的ndarray数组使用布尔表达式可以产生一个布尔值数组(逐元素操作)。
numpy中的逻辑符号
在numpy中常用的逻辑符号都可以使用,比较特殊的有三个:~(取反)、&(与)、|(或)。注意,在numpy中与和或的判断不是用Python关键字and和or。
注意:
- 布尔索引创建的是视图,而不是副本。
- 在使用布尔索引的时候一定要小心,要保证作为索引的布尔值数组的大小合适,当大小不合适时,系统并不会报错,所以使用要尤其小心。
【例1】布尔索引使用举例
In [274]: arr1
Out[274]: array([0, 1, 2, 3, 4, 5, 6])
#产生布尔值数组
In [275]: arr1 == 1
Out[275]: array([False, True, False, False, False, False, False])
In [276]: data = np.random.randn(7,4)
In [277]: data
Out[277]:
array([[-1.10593508, -1.65451545, -2.3634686 , 1.13534535],
[-1.01701414, 0.63736181, -0.85990661, 1.77260763],
[-1.11036305, 0.18121427, 0.56434487, -0.56651023],
[ 0.7299756 , 0.37299379, 0.53381091, -0.0919733 ],
[ 1.91382039, 0.33079713, 1.14194252, -1.12959516],
[-0.85005238, 0.96082 , -0.21741818, 0.15851488],
[ 0.87341823, -0.11138337, -1.03803876, -1.00947983]])
#布尔索引应用
In [278]: data[arr1 == 1]
Out[278]: array([[-1.01701414, 0.63736181, -0.85990661, 1.77260763]])
In [279]: data[arr1 == 1,0]
Out[279]: array([-1.01701414])
3. 神奇索引
神奇索引是指使用整数列表进行数据索引。将想要选择的列或行的索引放入一个列表,然后将列表作为索引,能够选择想要的行或列,并且数据选择结果的顺序会跟列表中索引的顺序保持一致。
在使用神奇索引的时候,通常有三种用法:选择部分行或列、选择部分元素、选择一个数据区域。
1) 选择部分行或列
In [299]: arr = np.empty((4,4))
In [300]: for i in range(4):
...: arr[i] = i
...:
In [301]: arr
Out[301]:
array([[0., 0., 0., 0.],
[1., 1., 1., 1.],
[2., 2., 2., 2.],
[3., 3., 3., 3.]])
#行选择
In [302]: arr[[3,0,1]]
Out[302]:
array([[3., 3., 3., 3.],
[0., 0., 0., 0.],
[1., 1., 1., 1.]])
In [303]: for i in range(4):
...: arr[i] = [0,1,2,3]
...:
In [304]: arr
Out[304]:
array([[0., 1., 2., 3.],
[0., 1., 2., 3.],
[0., 1., 2., 3.],
[0., 1., 2., 3.]])
#列选择
In [305]: arr[:,[3,1]]
Out[305]:
array([[3., 1.],
[3., 1.],
[3., 1.],
[3., 1.]])
2) 选择部分元素
对于二维数组,当同时传入两个列表作为索引的时候,是在已有矩阵中选择部分元素,得到的结果必然是一行一列。
In [310]: arr = np.random.randn(4,4)
In [311]: arr
Out[311]:
array([[-1.05825656, 0.65628408, -0.06249159, -1.73865429],
[ 0.103163 , -0.62166685, 0.27571804, -1.09067489],
[-0.60998525, 0.30641238, 1.69182613, -0.74795374],
[-0.58079722, -0.11075397, 2.04202875, 0.44752069]])
In [312]: arr[[1,2,3],[3,0,2]]
Out[312]: array([-1.09067489, -0.60998525, 2.04202875])
3) 选择一个数据区域
在b这个部分讲到的选择一行一列用到比较少,反而选择数据区域用处较多,此时需要使用迭代索引。
#所用数组与b中相同,仔细比较两个语法区别
In [313]: arr[[1,2,3]][:,[3,0,2]]
Out[313]:
array([[-1.09067489, 0.103163 , 0.27571804],
[-0.74795374, -0.60998525, 1.69182613],
[ 0.44752069, -0.58079722, 2.04202875]])