【KBQA综述-0】Complex Knowledge Base Question Answering: A Survey
Complex Knowledge Base Question Answering: A Survey(2021年10月)
前言
这是一篇对于复杂问题KBQA领域的详细综述,其工作主要集中在以下方面:
- 文章总结了当前复杂问题知识库问答领域所面临的一些难题,以及针对这些难题现存的思路和解决方法;
- 针对上一问题中提出的思路和方法分门别类,对于当前复杂问题KBQA领域的研究方向进行了梳理,并且对各研究方向上所用的主要算法、模型、表现进行了总结;
- 对在复杂问题KBQA中常用的知识库和数据集进行了介绍。
当前复杂问题知识库问答面临的问题
- 当前基于语义解析方法的解析器很难覆盖多样且复杂的问题,如把含多跳推理、约束关系和数字操作的问题。
- 复杂问题中更多的关系和主语使得在解析的过程中,对潜在逻辑形式的搜索空间大大增加。通常在解析的过程中,对于不同的实体会有枚举所有SPO的操作,这样也就很容易理解搜索空间的增大了。
- 无论对于基于语义解析的方法还是基于信息检索的方法,问题理解都是一个先导步骤。当问题变得复杂之后,模型就需要更加强大的自然语言理解能力和生成能力。
- 由于人工标记问题路径(从主体实体到答案实体的路径)的代价十分高昂,所以这一类的数据也就很稀少,这为模型的训练带来了问题,造成模型的训练通常在一个弱监督信号的条件下进行。
具体来说,复杂问题的知识问答分为两类:基于语义解析的知识库问答,基于信息检索的知识库问答。基于语义解析的知识库问答在拿到问题之后通过对问句的语义进行分析,构建出形式化的查询,通常是SPARQL语句,然后去知识库中查找答案。基于信息检索的知识库问答,在拿到问句之后根据问句中的实体在知识库中找出相应的子图,然后构建出主题实体到答案的路径,进而求解出答案。这篇文章对于两种方法具体化的分为了几个功能模块,并对每个功能模块面对的挑战进行了介绍。
论文章节内容:
- 介绍
- 背景知识,包含任务制定、基础知识等
- 可用的数据集以及这些数据集是如何构建的
- 介绍两种针对复杂知识问答的主流方法
- 针对两种主流方法,指出他们各自面对的典型挑战以及相应的解决方法
- 讨论了几个最近的研究趋势
- 总结本文的贡献
文章目录
- 一、知识库问答基础知识
-
- 1. 知识库介绍
- 2. 知识库问答任务的公式化定义
- 3. 传统方法
- 4. KBQA系统评估指标
- 二、常用数据集
- 三、基于语义解析的复杂问题知识库问答
- 四、基于语义解析的复杂问题知识库问答面对的问题和解决方法
-
- 1. 概括
- 2.复杂语句的语义和句法理解
-
- 1)基于Seq2seq
- 2)基于树结构或者图结构的逻辑形式候选排序
- 3)解决状态转换构建候选查询图方法忽视问题语义结构的问题
- 3. 解析复杂问题
- 4. 在大搜索空间中落地
- 5.在弱监督信号中训练
- 6. 用到的模型和实现方法
- 五、当前一些新的研究方向
一、知识库问答基础知识
1. 知识库介绍
常用的大规模知识库有:Freebase [1], DBPedia [2], Wikidata [3] and YAGO [4]
- 知识库中的知识通常是三元组的格式
- 为了支持结构化查询,大规模开放知识库都是用RDF描述的,而SPARQL是常用来检索操作知识库的查询语言
- 不同的知识库有不同的构建目的、多变的配置、不同的模式设计。例如,Freebase由社区成员从很多资源收集而来,包括Wikipedia;YAGO将Wikipedia和WordNet作为知识源,涵盖了更加一般的概念的分类;WikiData是一个多语言知识库,它整合了多知识库资源,覆盖率和质量都很高。
对于知识库更加详细的对比可以看这里。
2. 知识库问答任务的公式化定义
-
知识库的公式化表达
G = { < e , r , e ′ > ∣ e , e ′ ∈ ε , r ∈ R } \mathcal{G} = \{
其中, < e , r , e ′ >
-
问答任务的公式化定义
问题: q = { w 1 , w 2 , ⋯ , w m } q = \{w_1,w_2, \cdots, w_m\} q={w1,w2,⋯,wm},其中 w i w_i wi是问句中第 i i i个单词的token。
预测答案: A ~ q \tilde{\mathcal{A}}_q A~q, 真实答案: A q {\mathcal{A}}_q Aq
用于训练模型的数据集: D = { ( q , A q ) } \mathcal{D}=\{(q,{\mathcal{A}}_q)\} D={(q,Aq)}当前的研究假设 A q {\mathcal{A}}_q Aq提取自知识库的实体集 ε \varepsilon ε。这里要注意,对于简单问句,其答案实体往往和主题实体是直接相连的,其真是答案 A q {\mathcal{A}}_q Aq 真包含于实体集 ε \varepsilon ε。然而,对于复杂问句,其答案实体往往有多个而且离主题实体有好几跳的距离,甚至其答案是这些实体的聚合。
3. 传统方法
如下图所示是对简单问题的知识库问答框架,通常分为两步。
第一步是寻找问句中的主题实体,目的在于将一个问题和知识库中有关联的实体连接起来。在这个过程中,命名实体识别、消歧和链接都是在这一步完成。这一步通常用一些现成的实体链接工具,如:S-MART [24], DBpedia Spotlight [25], and AIDA [26]. 这里有实体链接工具的介绍。
第二步是用问题 q q q作为一个答案预测模型的输入,用这个模型来预测答案 A ~ q \tilde{\mathcal{A}}_q A~q。
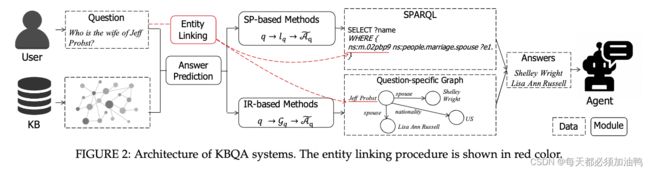
论文中还讲了其他的方法,这里不一一赘述,详细可看论文。
值得一提的是,简单问题的知识库问答基本已经解决,这篇文章讲述了简单问题知识库问答的情况,而且附有源码,我个人认为是了解简单问答的一个很好的资料。相信对简单问答有了一些了解之后,对复杂问答的理解也会有帮助。
4. KBQA系统评估指标
总的说,对于一个KBQA系统的评估,可以从三方面进行:可靠性、健壮性、系统和用户的交互。
-
可靠性
评估指标有四个:准确率、召回率、F1值、Hits@1准确率: P r e c i s i o n = ∣ A q ∩ A q ~ ∣ ∣ A q ∣ ~ Precision = \frac{|\mathcal{A}_q \cap \tilde{\mathcal{A}_q}|}{|\tilde{\mathcal{A}_q|}} Precision=∣Aq∣~∣Aq∩Aq~∣
召回率: R e c a l l = ∣ A q ∩ A q ~ ∣ ∣ A q ∣ Recall = \frac{|\mathcal{A}_q \cap \tilde{\mathcal{A}_q}|}{|\mathcal{A}_q|} Recall=∣Aq∣∣Aq∩Aq~∣
F1 值 : F 1 = 2 ∗ P r e c i s i o n ∗ R e c a l l P r e c i s i o n + R e c a l l F_1 = \frac{2*Precision*Recall}{Precision + Recall} F1=Precision+Recall2∗Precision∗Recall
Hits@1:

这里的Hits@1是Hits@n中的n取1时的指标,而Hits@n是知识图谱嵌入中的常用指标,在知识图谱嵌入中n通常取3或者10。Hits@1有时会用在KBQA任务中。
Hits@n,主要用于三元组链接预测,假设有一个三元组的正例,目前已知三元组的主题实体,然后对这个三元组进行预测。进行了1次预测,这一次预测得到了m(n
假设有两个正例
Jack born_in Italy Jack friend_with Thomas进行了两次预测
s p o score rank Jack born_in Ireland 0.789 1 Jack born_in Italy 0.753 2 * Jack born_in Germany 0.695 3 Jack born_in China 0.456 4 Jack born_in Thomas 0.234 5 s p o score rank Jack friend_with Thomas 0.901 1 * Jack friend_with China 0.345 2 Jack friend_with Italy 0.293 3 Jack friend_with Ireland 0.201 4 Jack friend_with Germany 0.156 5其中后面带星的是正例。则:
Hits@3= 2/2 = 1.0 Hits@1= 1/2 = 0.5 -
健壮性
当前的很多KBQA数据集都是基于模板产生而缺乏多样性;
训练数据的规模因为人工标注的高代价而受到限制;
现在是数据爆炸的时代,训练数据集不可能覆盖所有的范围。因此,提高模型的健壮性一直是一个重要的话题,如何使得模型可以覆盖不包含在训练集内的模式元素和领域是一个重要的研究方向。
-
系统和用户的交互
一个好的问答系统应该跟用户有良好的交互,当前离线的试验评估受到比较大的重视,然而和用户的交互这一方面收到了忽略。事实确实如此,此处不多余赘述、
二、常用数据集
此部分对复杂问题知识库问答中常用的数据集进行介绍分析。
原文中的章节对各个数据集的来源以及构建时的特殊性进行了详细的介绍,感兴趣可以去阅读原文。如果作为使用者,文中的TABLE 1已经足够:

其中LF\CO\NL\NU的含义如下:
LF:数据集是否提供类似SPARQL的逻辑形式(Logic Forms)
CO:数据集中是否含有包含约束(Constraints)的问题
NL:数据集的生成过程中是否雇佣人工对问题进行同意改写(NL, Natural Language)
NU:数据集中是否包含需要数字操作(Numerical operations)的问题,数字操作例如比较、排序等
三、基于语义解析的复杂问题知识库问答
在文章中是对基于语义解析的知识库问答和基于信息检索的知识库问答两种主要思路都进行了介绍,这里只看基于语义解析的方法,对基于信息检索的方法感兴趣可以去看原文。
总的来说,基于语义分析的方法执行的是一个 p a r s e − t h e n − e x c u t e parse-then-excute parse−then−excute 的流程,基于信息检索的方法执行的是一个 r e t r i e v e − a n d − r a n k retrieve-and-rank retrieve−and−rank 的流程。
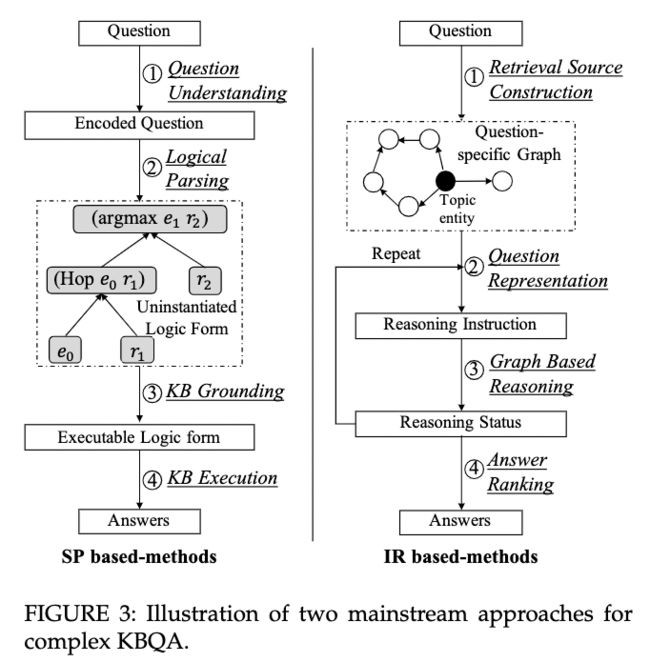
此处只讨论语义解析的知识库问答流程。
第一步:完整的理解问题中的语义信息,这一步经常使用LSTM,GRU,当前使用BERT也很多,最终得到的是包含语义信息的编码后的问题
q ~ = Q u e s t i o n _ U n d e r s t a n d i n g ( q ) \tilde{q} = Question\_Understanding(q) q~=Question_Understanding(q)
第二步:将第一步得到的编码后的问题作为输入,生成逻辑形式,提取问题中的逻辑结构信息。这一步可以通过序列生成或者对候选打分获得。实践中经常采用Seq2seq模型和基于特征的打分模型。(逻辑形式到底是什么样的形式?)
l q ˉ = Logical_Parsing ( q ~ ) \bar{l_q}=\text{Logical\_Parsing}(\tilde{q}) lqˉ=Logical_Parsing(q~)
第三步:将第二步得到的逻辑形式,针对具体的知识库进行实例化,生成可以在知识库中执行的查询 l q l_q lq,这个 l q l_q lq可以转化为SPARQL形式。值得一提的是, l q l_q lq中必然包含 e q e_q eq,这里的 e q e_q eq是通过实体链接得到的。在很多模型中,是将第二步和第三步结合在一起的。(实体链接在哪一步执行?)
l q = KB_Grounding ( l q ˉ , G ) l_q = \text{KB\_Grounding}(\bar{l_q},\mathcal{G}) lq=KB_Grounding(lqˉ,G)
第四步:执行第三步得到的形式化查询得到预测答案
A q ~ = KB_Execution ( l q ) \tilde{\mathcal{A_q} } = \text{KB\_Execution}(l_q) Aq~=KB_Execution(lq)
注意:
- 虽然没有特别说明,但是实体链接是在第一步中进行的,通过实体链接和关系检测找到实体和关系,从而根据找到的关系构建第二步的逻辑结构;
- 第三步的实例化是用实体链接中找到的实体;
- 在实践中,第二步的逻辑结构可以通过人工制定模板或者构建查询树等形式,例如对一跳问题提供一个逻辑形式,对两跳问题提供另一种逻辑形式;
- 当前复杂问题知识库问答的研究大多集中于第二步,努力提高第二步的效果,对于第二步来说,提升模型语义解析能力和设计更好的逻辑形式是提升性能的关键方法;
- 第一步的语义提取和实体链接等技术当前已经较为成熟。
四、基于语义解析的复杂问题知识库问答面对的问题和解决方法
1. 概括
前面已经将基于语义分析的知识库问答流程大致分为了四个阶段:Question understanding, Logical parsing, KB grounding, KB execution。不同的部分都面临相对的问题,概括的将有以下几个方面:
- 当问题的语义和句法更加复杂之后,问题理解(Question Understanding) 变得更加困难。
- 复杂问题更加多样化,逻辑解析(Logical parsing)很难覆盖全面。同时,复杂问题中更多的实体和关系使得搜索空间大大增加,从而降低分析的效率。
- 手动标注数据的成本太高,所以导致基于语义解析的方法缺乏良好的训练数据,只能在弱监督信号的条件下训练。
论文接着从四个方面对当前的研究情况进行总结,概括如下表,接下来我将详细说明。

2.复杂语句的语义和句法理解
作为SP-based的第一步,问题理解模块讲非结构化的转化为编码的问题,这对下游的分析有很大的作用,而复杂问题相对于简单问题更加难以提取其语义。
1)基于Seq2seq
- 为了更好的理解复杂自然语言问题,很多现存的方法依靠句法解析,例如基于依存性的【13】、【64】、【68】和AMR【72】,这样使得问题的成分与逻辑形式元素有更好的匹配。
- 为了减少对于复杂问题句法分析的不正确性,【73】利用基于骨架的分析法来获得复杂问题的主干部分,这样的一个主干包含一个具有几个待扩展分支的简单问句。例如,句子“What movie that Miley Cyrus acted in had a director named Tom Vaughan?”的主干是"What movie had a director?",原句子中的定语从句则是分支。在这样一个骨架结构中,只有简单问题将被进一步解析,这样更有可能得到准确的解析结果。
2)基于树结构或者图结构的逻辑形式候选排序
- 【74】提出了一个新颖的打分模型,在这个模型中利用查询图结构和注意力权重明确的比较谓词和自然语言问题。具体来说,文中提出了一个细粒度的槽匹配机制,这个机制用于在核心推理链上对问题和每一个谓词进行跳宽度的语义匹配。
- 相较于捕捉问题和一个简单关系链之间的语义关联,【75】聚焦于查询的结构特征并以查询问题匹配的方式执行KBQA。他们用了一个结构感知编码器来为一个查询中的实体或关系上下文建模,从而提升查询和问题的匹配度。相似的,【77】使用了两个Tree-LSTMs[94]来分别为问题的依存关系树、候选查询的树结构进行建模,并且利用二者之间的结构相似性做综合排名。
3)解决状态转换构建候选查询图方法忽视问题语义结构的问题
传统方法采取状态转换策略来生成候选查询图。这种策略忽视了问题本身的结构性,这样讲导致一大批不合格的查询进入候选集。
- 为了过滤这些不合格的查询,【76】提出了预测问题的查询结构并以此限制候选查询生成的方法。具体来说,他们设计了一系列的操作来生成对一些类型的占位符,这些类型包括:数字操作,谓词,实体。在这之后,他们借助知识库将这些未实例化的逻辑形式落地,从而产生可执行的逻辑形式。通过这样的两阶段操作,含有非匹配结构的非法逻辑形式会被高效的过滤出去。
论文列表:
3. 解析复杂问题
为了生成一个可执行的逻辑形式,传统方法第一步利用现存的解析器讲一个问题转换为CCG派生,这个CCG派生可以通过在知识库中寻找相应的关系和实体与其谓词和论据相匹配,进而生成具体的SPARQL查询。
然而,由于这些方法存在本体错误匹配的问题,只能被当做复杂问题问答中的次优先级方法。因此,利用知识库的的结构来进行精准的解析就是必须的,这种精准的解析表现出来的是和知识库的事实高度一致。为了适应复杂问题的组合型,研究者提出了不同的逻辑表达形式作为解析的目标。
-
由于在前面的步骤已经得到了主题实体,【78】从主题实体出发,设计了三种查询模版作为解析的目标。如下图所示,前两种模板返回跟主题实体‘Titanic’相距一跳或者两跳距离的实体。第三种模版返回跟主题实体的距离在两跳以上以及被其他实体限制的实体。这种方法虽然可以成功解析几种类型的复杂问题,但是它受到覆盖面有限这一缺陷的约束。【79】与此论文类似,他集中精力设计可以处理时态问题的模板。

-
【36】提出了将查询图作为表达解析的目标。一个查询图是一种图形式的逻辑形式,它和知识库模式相匹配,并且可以转化为一个可执行的SPARQL。查询图包含试题,变量和函数,他们分布对应问题中提到的固定实体,要查询的变量、聚合操作。就像图5所示,从主题实体出发的推断链首先被确定,然后约束实体和聚合操作被附加到路径链上,从而使得可以适应更加复杂的问题。不同于与定义的模板,查询图不受跳数以及约束数量的限制。这一方法在复杂问题知识问答任务中展现了强大的表达能力,但这一方法的缺陷是尚不能处理长尾类型的复杂问题。
-
基于对长尾问题的更多观察,【64】尝试通过增加句法提示来增加查询图的结构复杂性,进而可以提升查询图的公式,【12】尝试应用更多的聚合操作,例如合并、共指消解等来适应复杂问题。
-
Tips
CCG(combinatory categorial grammars,组合范畴文法),CCG的作用是提供一个从自然语言的语法到语义的转化,能够作为将自然语言转换为数据库查询结构的工具。具体内容较多,在ReadPaper的相关知识中有介绍的PPT,后面需要再仔细学习。共指消解:将现实世界中同一实体的不同描述合并到一起。
论文列表:
4. 在大搜索空间中落地
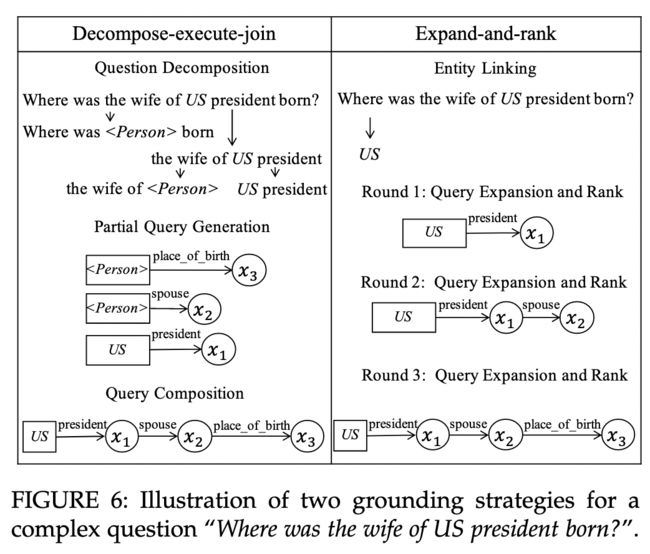
为了得到可执行的逻辑形式,知识库链接模块利用知识库将可能的逻辑形式实例化。知识库中的一个实体常常关联到成百上千个实体,在这样的情况下进行知识库链接和搜索的时间代价以及计算复杂度都是极高的。相比于在一步之中枚举逻辑形式,研究者们尝试在多步中生成复杂查询。
- 【80】提出先将复杂问题分为几个简单问题,将这些简单问题解析为简单逻辑形式。然后将这些简单逻辑形式进行拼接或者组合从而得到最终的逻辑形式。这种 decompose-execute-join 的方式有效的缩减了搜索空间。【81】类似的提出通过利用扩展的指针网络([55])来识别通过连接或合成获得的最终答案,从而减少了人工注释。
除了采用分解复杂问题从而得到子问题的方法,有很多学者采用了 expand-and rank 的方法来缩小搜索空间,通过一种以迭代方法扩展逻辑形式的方法。具体来说,第一个迭代中找出与主题实体只有一条距离的实体作为候选实体,然后通过比较问题和逻辑形式的语义相似性来给这些候选实体打分,然后得分较高的一部分实体将继续扩展,而低分的将被舍弃。接下来,得高分的逻辑形式将会被继续扩展,这样就能够得到更加复杂的查询图。每当找到最佳的查询图,这一过程就会停止。
-
【47】首先使用逐条贪婪搜索扩展最可能查询图。
-
【82】提出了一种增量式序列匹配模块,可以迭代地解析问题,而不需要在每个搜索步骤中重新访问生成的查询图。
-
【83】不同于以上提出的线性方法,这样的线性方法只有在多条关系上效率较高。在这篇论文中在每个迭代中定义了三个动作:扩展、连接、聚合,其分别对应多条推理、约束关系和数值运算。
论文列表:

5.在弱监督信号中训练
- 【63】,【86】为了解决训练数据的有限性和不充分性,基于强化学习的优化被用来最大化期望奖励。
使用强化学的方式,在基于语义解析的方法中只能在完全解析后的逻辑形式执行之后得到反馈,这会导致严重稀疏的正奖励和虚假推理问题。为了解决这些问题,一些研究工作采用了句法分析评价的整形策略。
- 【84】通过附加反馈,当预测的答案和事实是同一类型时,给模型奖励。除了来自最终预测的奖励,再语义分析过程中的即时奖励也可能会帮助解决这一问题。
- 【86】将查询图生成问题转为一个层次化决策问题,并且提出来一个基于选择的层次框架来为低层次的agent提供奖励。在决策过程中的选择时,高等级的agent在中间步骤为低等级的agent设定目标。同时,为了检测低等级的agent的中间状态是否达到了高等级agent的目标,他们评估所给的问题和生成的三元组的语义相似度。
- 【63】为了加速和稳定训练过程,这篇文章提出通过迭代最大似然训练过程来保持pseudo-gold program。训练的过程包含两部分,第一步,利用BEAM搜索机制来查找 pseudo-gold programs,第二步,在历史上发现的最好的program的监督下优化模型。【87】提出了一个相似的想法,通过将个生成的逻辑形式和缓存中存储的得到最高经历的逻辑形式进行对比来评估生成的逻辑形式。为了在开发和探索之间取得平衡,他们提出了接近奖励和新奇奖励来鼓励记住过去的高奖励逻辑形式并产生新的逻辑形式,通过这样一种两种方式来分别减轻虚假推理。将这种奖励与终端奖励相结合,模型可以再学习阶段获得密集的反馈。
论文列表:


6. 用到的模型和实现方法

五、当前一些新的研究方向
- 自学习的KBQA
- 更加强健的KBQA系统(能应对数据集分布之外分别的问题)
- 更加广泛的知识库
- 对话式的KBQA