Tensorflow2.x Yolov3源码及原理
很久之前接触锅Yolov3的相关内容,最近又重新回过头来看Yolov3的代码,在github上找到相关开源代码,然后加上对原理的理解,学习了一遍。借鉴的Github源码的作者已经对Yolov3进行详细的阐述了,也可以直接看作者的博客,下面有一些图是直接从作者博客拷贝的,有一些是自己做的,下面对源码的理解是介于tensorflow2.0.0的。
Tensorflow1.11 Yolov3 github源码
Tensorflow2.0.0 Yolvo3 gitHub源码
1.前言
目标检测是计算机视觉中一个重要问题,它主要就是将目标的定位和目标分类结合起来,像图1这样,框将目标给标识出来并且打上标签。随着深度学习的在图像上运用越来越广泛,基于深度学习的目标检测算法逐渐成为了主流。基于深度学习目标检测算法有很多,基于分类的有R-CNN,Fast-RCNN,Faster-RCNN,Mask R-CNN等。基于回归的检测Yolvo系列1~4,SSD等。Yolo全称叫You Only Look Once,和RCNN不同,生成候选框和分类回归合成一个步骤,所以R-CNN系列目标检测框架属于two stage算法,而Yolvo是single stage算法.
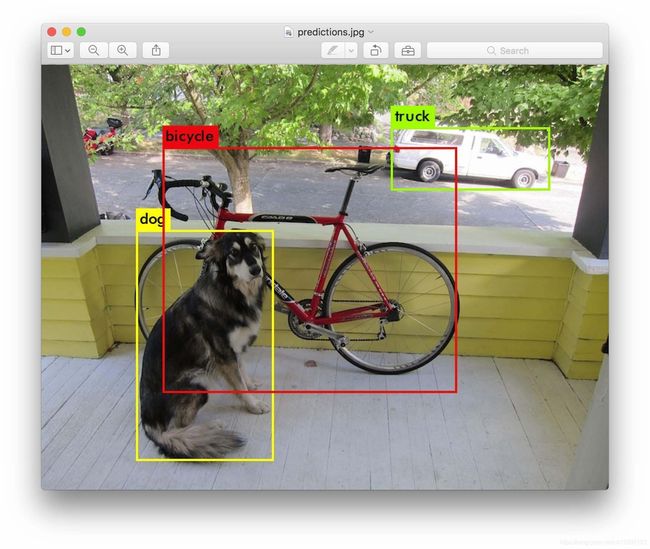
图1
基本思想
说回Yolov3,要检测出目标在图像中哪个位置,就得需要位置信息,也就是bounding box,如图2所示那样需要知道中心点的坐标,框的宽和高。也就是包含4个值:x,y,w,h,(x,y)代表 box 的中心。(w,h)代表 box 的宽和高。那么Yolv3的网络是如何最终得到这些信息的,而且既然它是属于回归检测一种,那么问题来了,他是如何回归的?

图2
YOLO算法中把物体检测问题处理成回归问题,并将图像分为S×S的网格。如果一个目标的中心落入格子,该格子就负责检测该目标,而它的回归思想是指将先验框(anchor box)到真实框(ground truth box)之间是一种回归关系,如图3,三个蓝色框是先验框,黄色的是真实框,红色的框是中心位置,先验框是通过预先选定的一些框,来帮助我们最终得到真实框的,在代码中先验框信息(宽和高)是固定在代码中的,它包含了三个尺寸,对应图中3个蓝框,有的大有的小,横纵比有一些区别。那么蓝色框如何回归到黄色框的,这是Yolov3网络通过训练后会得到一种隐射关系。如图4,Anchor box 到Ground truth box之间可以通过,中心点的坐标的偏移,以及框的宽和高的放大缩小来最终得到真实框,公式如以下:
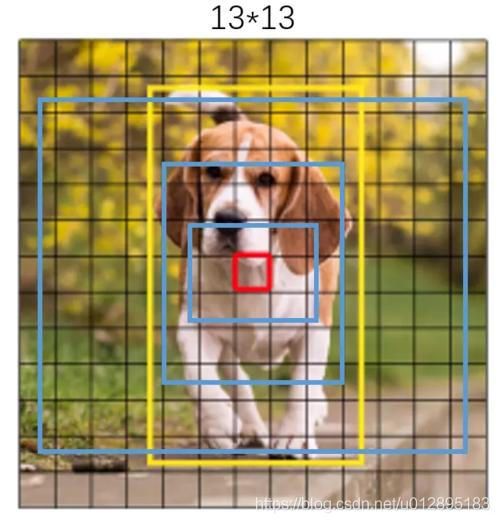
图3
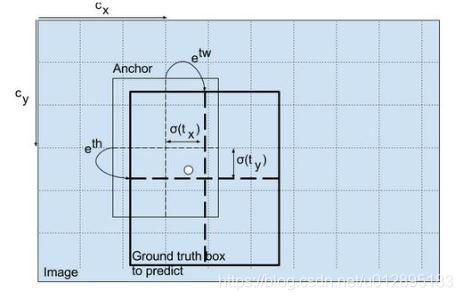
图4
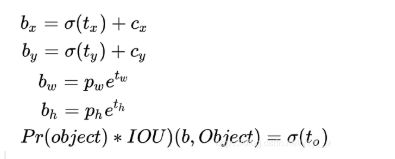
1.cx,cy:是指该点所在网格的左上角距离最左上角相差的格子数。
2.pw,ph:是指先验框的宽和高
3.tx,ty:是指目标中心点相对于该点所在网格左上角的偏移量
4.tw,th:是指预测边框的宽和高
σ:激活函数,用的是sigmoid函数,[0,1]之间概率。
而Yolov3网络学习目标就是这四个参数tx,ty,tw,th。当然了除了框的参数,网络还需要学习在这个框中是否有物体,也就是置信度(confidence)表示预测框中包含物体的概率,其实也是预测框与真实框之间的 iou 值,计算方式如下图5;还有类别的信息,用的是one-hot的表示方式,class probability 表示的是该物体的类别概率,比如有三类,one-hot表示第一类表示就是[1,0,0],第二类[0,1,0],第三类就是[0,0,1]。
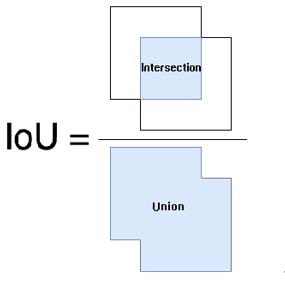
图5
多尺度检测
YOLOv3 对输入图片进行了粗、中和细网格划分,如图5,以便分别实现对大、中和小物体的预测。假如输入图片的尺寸为 416X416, 那么得到粗、中和细网格尺寸分别为 13X13、26X26 和 52X52。这样一算,那就是在长宽尺寸上分别缩放了 32、16 和 8 倍。上面的图是列举粗网格下三个蓝色的先验框,而中网格和细网格代码也分别各有3个先验框,所以总共有9个先验框。

图6
2.Yolov3网络结构

图7
首先Yolov3的骨干网络是Darknet53,其中DBL是Darknetconv2d_BN_Leaky,是yolo_v3的基本组件。就是卷积+BN+Leaky relu,resn是表示残差网络,有res1,res2, … ,res8等等,表示这个res_block里含有多少个res_unit,concat张量拼接。将darknet中间层和后面的某一层的上采样进行拼接。拼接的操作和残差层add的操作是不一样的,拼接会扩充张量的维度,而add只是直接相加不会导致张量维度的改变,具体的Darknet-53的网络如图6。
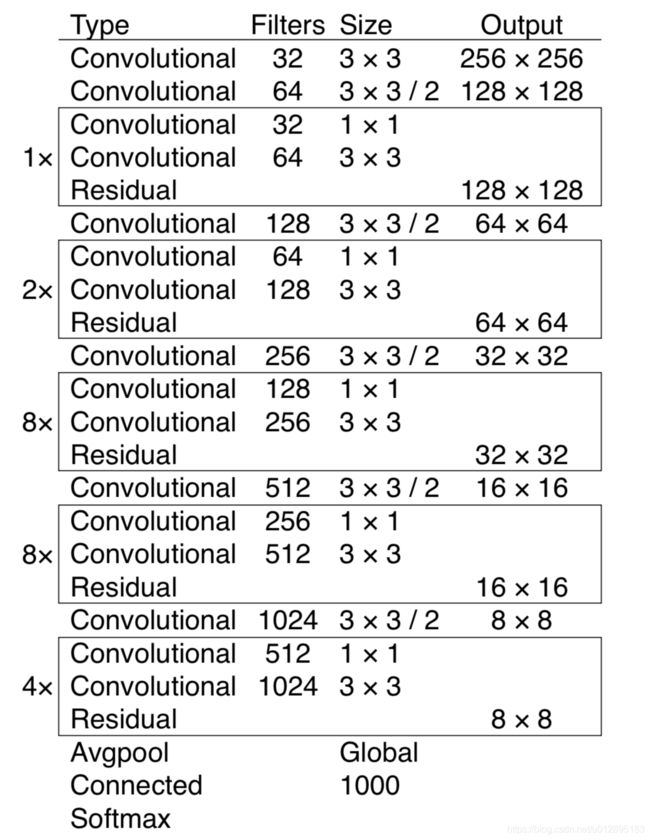
图8
由它的网络结构也可以看出最后输出的是13*13*255,26*26*255, 52*52*255,因为用的coco数据集,有80的类别,写成one-hot也就是有80维,再加上如上面所说的,4个框的参数+1个置信度,网络学习的参数(13,13,(80+5)*3),其他同理可得。
3.源码剖析
针对tensorflow2.x的代码,从train.py开始剖析,程序开始,,数据集是trainset,定义在dataset.py文件中,定义了Dataset类,并实现了迭代器协议,即实现了__iter__和__next__的方法。
主函数
定义了输入tensor是416*416*3的维度,因为tensorflow2.x中keras是一个重要的模块,所以2.X的编程中是推荐使用keras的,作者也是贯彻这一思想。输入tensor维度输入到YOLOv3的网络中,YOLOv3的网络定义在yolov3.py中。
trainset = Dataset('train')
logdir = "./data/log"
steps_per_epoch = len(trainset)
global_steps = tf.Variable(1, trainable=False, dtype=tf.int64)
warmup_steps = cfg.TRAIN.WARMUP_EPOCHS * steps_per_epoch
total_steps = cfg.TRAIN.EPOCHS * steps_per_epoch
input_tensor = tf.keras.layers.Input([416, 416, 3])
conv_tensors = YOLOv3(input_tensor)
output_tensors = []
for i, conv_tensor in enumerate(conv_tensors):
pred_tensor = decode(conv_tensor, i)
output_tensors.append(conv_tensor)
output_tensors.append(pred_tensor)
model = tf.keras.Model(input_tensor, output_tensors)
optimizer = tf.keras.optimizers.Adam()
if os.path.exists(logdir): shutil.rmtree(logdir)
writer = tf.summary.create_file_writer(logdir)主循环开始,进入train_step的函数,会持续从Dataset对象中调用__next__方法循环获取数据。
for epoch in range(cfg.TRAIN.EPOCHS):
for image_data, target in trainset:
train_step(image_data, target)
model.save_weights("./yolov3")
进入train_step, 输入是imgae_data和target,是从dataset.py来的,image_data就是图片的数据,target就是对应不同粗细网格下,3种不同尺度的先验框和真实框在IOU>0.3或者取最大IOU的数据。
借着通过model的__call__函数,输入数据进行训练,这边可以参考keras的API,training标志位可以设置训练和推理不同的行为。下面compute_loss是从yolov3.py来的,最终计算yolov3网络的输出到target数据之间的拟合,具体loss详解在下面。
最后还有收集各种指标以供tensorboard进行观看。
def train_step(image_data, target):
with tf.GradientTape() as tape:
pred_result = model(image_data, training=True)
#pred_result =
giou_loss=conf_loss=prob_loss=0
# optimizing process
for i in range(3):
conv, pred = pred_result[i*2], pred_result[i*2+1]
loss_items = compute_loss(pred, conv, *target[i], i)
giou_loss += loss_items[0]
conf_loss += loss_items[1]
prob_loss += loss_items[2]
total_loss = giou_loss + conf_loss + prob_loss
gradients = tape.gradient(total_loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
tf.print("=> STEP %4d lr: %.6f giou_loss: %4.2f conf_loss: %4.2f "
"prob_loss: %4.2f total_loss: %4.2f" %(global_steps, optimizer.lr.numpy(),
giou_loss, conf_loss,
prob_loss, total_loss))
# update learning rate
global_steps.assign_add(1)
if global_steps < warmup_steps:
lr = global_steps / warmup_steps *cfg.TRAIN.LR_INIT
else:
lr = cfg.TRAIN.LR_END + 0.5 * (cfg.TRAIN.LR_INIT - cfg.TRAIN.LR_END) * (
(1 + tf.cos((global_steps - warmup_steps) / (total_steps - warmup_steps) * np.pi))
)
optimizer.lr.assign(lr.numpy())
# writing summary data
with writer.as_default():
tf.summary.scalar("lr", optimizer.lr, step=global_steps)
tf.summary.scalar("loss/total_loss", total_loss, step=global_steps)
tf.summary.scalar("loss/giou_loss", giou_loss, step=global_steps)
tf.summary.scalar("loss/conf_loss", conf_loss, step=global_steps)
tf.summary.scalar("loss/prob_loss", prob_loss, step=global_steps)
writer.flush()数据集处理
dataset.py有一步对于原始图片做处理的过程,转化成416*416*3的尺度,如图8,图片300*200,通过宽度拉升300*1.387达到,宽度=416,但是高拉升到277,无法达到416,那么剩余不满的像素填充128的值,最后做归一化。
def image_preporcess(image, target_size, gt_boxes=None):
ih, iw = target_size
h, w, _ = image.shape
scale = min(iw/w, ih/h)
nw, nh = int(scale * w), int(scale * h)
image_resized = cv2.resize(image, (nw, nh))
image_paded = np.full(shape=[ih, iw, 3], fill_value=128.0)
dw, dh = (iw - nw) // 2, (ih-nh) // 2
##放置于中间
image_paded[dh:nh+dh, dw:nw+dw, :] = image_resized
image_paded = image_paded / 255.
if gt_boxes is None:
return image_paded
else:
gt_boxes[:, [0, 2]] = gt_boxes[:, [0, 2]] * scale + dw
gt_boxes[:, [1, 3]] = gt_boxes[:, [1, 3]] * scale + dh
return image_paded, gt_boxes

dataset.py还有对正负样本的分配,这边照搬一些作者博客上的东西:
- 如果 Anchor 与 Ground-truth Bounding Boxes 的 IoU > 0.3,标定为正样本;
- 在第 1 种规则下基本能够产生足够多的样本,但是如果它们的 iou 不大于 0.3,那么只能把 iou 最大的那个 Anchor 标记为正样本,这样便能保证每个 Ground-truth 框都至少匹配一个先验框。
按照上述原则,一个 ground-truth 框会同时与多个先验框进行匹配。
for i in range(3): # 针对 3 种网格尺寸
# 设定变量,用于存储每种网格尺寸下 3 个 anchor 框的中心位置和宽高
anchors_xywh = np.zeros((self.anchor_per_scale, 4))
# 将这 3 个 anchor 框都偏移至网格中心
anchors_xywh[:, 0:2] = np.floor(bbox_xywh_scaled[i, 0:2]).astype(np.int32) + 0.5
# 填充这 3 个 anchor 框的宽和高
anchors_xywh[:, 2:4] = self.anchors[i]
# 计算真实框与 3 个 anchor 框之间的 iou 值
iou_scale = self.bbox_iou(bbox_xywh_scaled[i][np.newaxis, :], anchors_xywh)
iou.append(iou_scale)
# 找出 iou 值大于 0.3 的 anchor 框
iou_mask = iou_scale > 0.3
exist_positive = False
if np.any(iou_mask): # 规则 1: 对于那些 iou > 0.3 的 anchor 框,做以下处理
# 根据真实框的坐标信息来计算所属网格左上角的位置
xind, yind = np.floor(bbox_xywh_scaled[i, 0:2]).astype(np.int32)
label[i][yind, xind, iou_mask, :] = 0
# 填充真实框的中心位置和宽高
label[i][yind, xind, iou_mask, 0:4] = bbox_xywh
# 设定置信度为 1.0,表明该网格包含物体
label[i][yind, xind, iou_mask, 4:5] = 1.0
# 设置网格内 anchor 框的类别概率,做平滑处理
label[i][yind, xind, iou_mask, 5:] = smooth_onehot
exist_positive = True
if not exist_positive: # 规则 2: 所有 iou 都不大于0.3, 那么只能选择 iou 最大的
best_anchor_ind = np.argmax(np.array(iou).reshape(-1), axis=-1)YOLOV3网络
包含骨干神经网络darknet53,最终会得到三个分支,这些分支在经过一系列的卷积、上采样以及合并等操作后最终得到了三个尺寸不一的 feature map,形状分别为 [13, 13, 255]、[26, 26, 255] 和 [52, 52, 255]
def YOLOv3(input_layer):
# 输入层进入 Darknet-53 网络后,得到了三个分支
route_1, route_2, conv = backbone.darknet53(input_layer)
# 见上图中的橘黄色模块(DBL),一共需要进行5次卷积操作
conv = common.convolutional(conv, (1, 1, 1024, 512))
conv = common.convolutional(conv, (3, 3, 512, 1024))
conv = common.convolutional(conv, (1, 1, 1024, 512))
conv = common.convolutional(conv, (3, 3, 512, 1024))
conv = common.convolutional(conv, (1, 1, 1024, 512))
conv_lobj_branch = common.convolutional(conv, (3, 3, 512, 1024))
# conv_lbbox 用于预测大尺寸物体,shape = [None, 13, 13, 255]
conv_lbbox = common.convolutional(conv_lobj_branch, (1, 1, 1024, 3*(NUM_CLASS + 5)),
activate=False, bn=False)
conv = common.convolutional(conv, (1, 1, 512, 256))
# 这里的 upsample 使用的是最近邻插值方法,这样的好处在于上采样过程不需要学习,从而减少了网络参数
conv = common.upsample(conv)
conv = tf.concat([conv, route_2], axis=-1)
conv = common.convolutional(conv, (1, 1, 768, 256))
conv = common.convolutional(conv, (3, 3, 256, 512))
conv = common.convolutional(conv, (1, 1, 512, 256))
conv = common.convolutional(conv, (3, 3, 256, 512))
conv = common.convolutional(conv, (1, 1, 512, 256))
conv_mobj_branch = common.convolutional(conv, (3, 3, 256, 512))
# conv_mbbox 用于预测中等尺寸物体,shape = [None, 26, 26, 255]
conv_mbbox = common.convolutional(conv_mobj_branch, (1, 1, 512, 3*(NUM_CLASS + 5)),
activate=False, bn=False)
conv = common.convolutional(conv, (1, 1, 256, 128))
conv = common.upsample(conv)
conv = tf.concat([conv, route_1], axis=-1)
conv = common.convolutional(conv, (1, 1, 384, 128))
conv = common.convolutional(conv, (3, 3, 128, 256))
conv = common.convolutional(conv, (1, 1, 256, 128))
conv = common.convolutional(conv, (3, 3, 128, 256))
conv = common.convolutional(conv, (1, 1, 256, 128))
conv_sobj_branch = common.convolutional(conv, (3, 3, 128, 256))
# conv_sbbox 用于预测小尺寸物体,shape = [None, 52, 52, 255]
conv_sbbox = common.convolutional(conv_sobj_branch, (1, 1, 256, 3*(NUM_CLASS +5)),
activate=False, bn=False)
return [conv_sbbox, conv_mbbox, conv_lbbox]其中convolutional函数定义了一个基础的组件,是只包含了卷积,还是darknet53的卷积+BN+Leaky relu组件,通过两个标志位activate和bn进行选择。
def convolutional(input_layer, filters_shape, downsample=False, activate=True, bn=True):
if downsample:
input_layer = tf.keras.layers.ZeroPadding2D(((1, 0), (1, 0)))(input_layer)
padding = 'valid'
strides = 2
else:
strides = 1
padding = 'same'
conv = tf.keras.layers.Conv2D(filters=filters_shape[-1],
kernel_size = filters_shape[0],
strides=strides, padding=padding, use_bias=not bn,
kernel_regularizer=tf.keras.regularizers.l2(0.0005),
kernel_initializer=tf.random_normal_initializer(stddev=0.01),
bias_initializer=tf.constant_initializer(0.))(input_layer)
if bn: conv = BatchNormalization()(conv)
if activate == True: conv = tf.nn.leaky_relu(conv, alpha=0.1)
return conv损失函数
在 YOLOv3 中,源码的作者是的损失函数包含如下,以下是直接从作者博客中摘取的:(将目标检测任务看作目标区域预测和类别预测的回归问题, 因此它的损失函数也有些与众不同。对于损失函数, Redmon J 在论文中并 没有进行详细的讲解。但通过对 darknet 源代码的解读,可以总结得到 YOLOv3 的损失函数如下):
- 置信度损失,判断预测框有无物体;
- 框回归损失,仅当预测框内包含物体时计算;
- 分类损失,判断预测框内的物体属于哪个类别
置信度的损失:
iou = bbox_iou(pred_xywh[:, :, :, :, np.newaxis, :], bboxes[:, np.newaxis, np.newaxis, np.newaxis, :, :])
# 找出与真实框 iou 值最大的预测框
max_iou = tf.expand_dims(tf.reduce_max(iou, axis=-1), axis=-1)
# 如果最大的 iou 小于阈值,那么认为该预测框不包含物体,则为背景框
respond_bgd = (1.0 - respond_bbox) * tf.cast( max_iou < IOU_LOSS_THRESH, tf.float32 )
conf_focal = tf.pow(respond_bbox - pred_conf, 2)
# 计算置信度的损失(我们希望假如该网格中包含物体,那么网络输出的预测框置信度为 1,无物体时则为 0。
conf_loss = conf_focal * (
respond_bbox * tf.nn.sigmoid_cross_entropy_with_logits(labels=respond_bbox, logits=conv_raw_conf)
+
respond_bgd * tf.nn.sigmoid_cross_entropy_with_logits(labels=respond_bbox, logits=conv_raw_conf)
)分类损失:
这里分类损失采用的是二分类的交叉熵,即把所有类别的分类问题归结为是否属于这个类别,这样就把多分类看做是二分类问题。这样做的好处在于排除了类别的互斥性,特别是解决了因多个类别物体的重叠而出现漏检的问题。

respond_bbox = label[:, :, :, :, 4:5]
prob_loss = respond_bbox * tf.nn.sigmoid_cross_entropy_with_logits(labels=label_prob, logits=conv_raw_prob)框回归损失:
respond_bbox = label[:, :, :, :, 4:5] # 置信度,判断网格内有无物体
...
bbox_loss_scale = 2.0 - 1.0 * label_xywh[:, :, :, :, 2:3] * label_xywh[:, :, :, :, 3:4] / (input_size ** 2)
giou_loss = respond_bbox * bbox_loss_scale * (1 - giou)解码部分
如上面描述的,网络学习到的四个参数tx,ty,tw,th,根据上面基本思想的公式,回归到真实框中。
def decode(conv_output, i=0):
# 这里的 i=0、1 或者 2, 以分别对应三种网格尺度
conv_shape = tf.shape(conv_output)
batch_size = conv_shape[0]
output_size = conv_shape[1]
conv_output = tf.reshape(conv_output, (batch_size, output_size,
output_size, 3, 5 + NUM_CLASS))
conv_raw_dxdy = conv_output[:, :, :, :, 0:2] # 中心位置的偏移量
conv_raw_dwdh = conv_output[:, :, :, :, 2:4] # 预测框长宽的偏移量
conv_raw_conf = conv_output[:, :, :, :, 4:5] # 预测框的置信度
conv_raw_prob = conv_output[:, :, :, :, 5: ] # 预测框的类别概率
# 好了,接下来需要画网格了。其中,output_size 等于 13、26 或者 52
y = tf.tile(tf.range(output_size, dtype=tf.int32)[:, tf.newaxis], [1, output_size])
x = tf.tile(tf.range(output_size, dtype=tf.int32)[tf.newaxis, :], [output_size, 1])
xy_grid = tf.concat([x[:, :, tf.newaxis], y[:, :, tf.newaxis]], axis=-1)
xy_grid = tf.tile(xy_grid[tf.newaxis, :, :, tf.newaxis, :], [batch_size, 1, 1, 3, 1])
xy_grid = tf.cast(xy_grid, tf.float32) # 计算网格左上角的位置
# 根据上图公式计算预测框的中心位置
pred_xy = (tf.sigmoid(conv_raw_dxdy) + xy_grid) * STRIDES[i]
# 根据上图公式计算预测框的长和宽大小
pred_wh = (tf.exp(conv_raw_dwdh) * ANCHORS[i]) * STRIDES[i]
pred_xywh = tf.concat([pred_xy, pred_wh], axis=-1)
pred_conf = tf.sigmoid(conv_raw_conf) # 计算预测框里object的置信度
pred_prob = tf.sigmoid(conv_raw_prob) # 计算预测框里object的类别概率
return tf.concat([pred_xywh, pred_conf, pred_prob], axis=-1)9个先验框
9个先验框是固定写在basline_anchors.txt,1.25,1.625, 2.0,3.75, 4.125,2.875, 1.875,3.8125, 3.875,2.8125, 3.6875,7.4375, 3.625,2.8125, 4.875,6.1875, 11.65625,10.1875,其中配置文件里面写道__C.YOLO.STRIDES = [8, 16, 32],416根据这三个步幅,依次得到细网格,中网格,粗网格。
[1.25,1.625], [2.0,3.75], [4.125,2.875] 是对应小框,细网格
[1.875,3.8125], [3.875,2.8125], [3.6875,7.4375]是对应中框,中网格
[3.625,2.8125], [4.875,6.1875], [11.65625,10.1875]是对应大框,大网格
NMS处理
也是摘抄作者博客,非极大值抑制(Non-Maximum Suppression,NMS),顾名思义就是抑制不是极大值的元素,说白了就是去除掉那些重叠率较高并且 score 评分较低的边界框。 NMS 的算法非常简单,迭代流程如下:
- 流程1: 判断边界框的数目是否大于0,如果不是则结束迭代;
- 流程2: 按照 socre 排序选出评分最大的边界框 A 并取出;
- 流程3: 计算这个边界框 A 与剩下所有边界框的 iou 并剔除那些 iou 值高于阈值的边界框,重复上述步骤;
# 流程1: 判断边界框的数目是否大于0
while len(cls_bboxes) > 0:
# 流程2: 按照 socre 排序选出评分最大的边界框 A
max_ind = np.argmax(cls_bboxes[:, 4])
# 将边界框 A 取出并剔除
best_bbox = cls_bboxes[max_ind]
best_bboxes.append(best_bbox)
cls_bboxes = np.concatenate([cls_bboxes[: max_ind], cls_bboxes[max_ind + 1:]])
# 流程3: 计算这个边界框 A 与剩下所有边界框的 iou 并剔除那些 iou 值高于阈值的边界框
iou = bboxes_iou(best_bbox[np.newaxis, :4], cls_bboxes[:, :4])
weight = np.ones((len(iou),), dtype=np.float32)
iou_mask = iou > iou_threshold
weight[iou_mask] = 0.0
cls_bboxes[:, 4] = cls_bboxes[:, 4] * weight
score_mask = cls_bboxes[:, 4] > 0.
cls_bboxes = cls_bboxes[score_mask]参考文章:
https://yunyang1994.gitee.io/2018/12/28/YOLOv3/