机器学习西瓜书泛读笔记(一)
原文转自:周志华《机器学习》读书笔记(一)
本书前几章讲的都是基本术语,最硬核的数学部分很少,所以比较简单。
机器学习的主要内容,是从数据产生模型,再由模型做出相应的判断和预测。
比如已经知道某房屋所在街区的其他房屋的价格,通过给这些面积,价格等各异的其他房屋的数据进行分析,产生模型,利用此模型来预测本房屋的市场价格。
一. 基本术语
对一批西瓜,我们能够观察了解到色泽、根蒂、敲声等特征。比如现在得到的数据如下所示:
(色泽=青绿;根蒂=蜷缩;敲声=浊响)
(色泽=墨绿;根蒂=稍蜷;敲声=沉闷)
(色泽=浅白;根蒂=硬挺;敲声=清脆)对于这样的一组数据,我们有如下概念:
数据集:这组数据的集合
示例/样本:数据集中,每条记录都是关于一个事件or一个对象(这里是一个西瓜)的描述,因此这里的每条记录都被称为“示例or样本”
属性:反应事件or对象在某方面的属性or性质的事项,就是属性。这个例子中,色泽、根蒂、敲声,三者都是“属性”
属性值:属性上的取值,即为“属性值”,这个例子里,“青绿”、“乌黑”等都是属性值
属性空间/样本空间/输入空间:属性张成的空间。大白话而言,就是,一个属性,就是一根坐标轴,就是一个维度。在这个例子中,由于每个西瓜都有色泽、根蒂、敲声这三个属性。因此对每个西瓜而言,它都可以在这个三维的属性空间里,找到自己的位置。
特征向量:由于空间中的每个点,对应一个坐标向量。相应的,一个示例,也被称作一个“特征向量”
维数:对于某一个属性空间而言,维数其实就是属性的数量。该例中,维数为3维,但是如果我们再加入纹理、触感两个性质,维数就成5维了,这十分显然。
标记:关于示例的结果的信息。比如
(色泽=青绿;根蒂=蜷缩;敲声=浊响)
这个示例,我们根本没法知道这是“好瓜”or“坏瓜”。这种时候,我们可以加上示例结果的信息
(色泽=青绿;根蒂=蜷缩;敲声=浊响),好瓜)
在这里,"好瓜"就是这个示例的标记
标记空间、输出空间——所有标记的集合。
样例:一个示例拥有了标记,我们就称它为“样例”
学习/训练:从数据里学得模型的过程
训练样本/训练示例:训练过程当中的每个样本
训练集:训练样本组成的集合
测试:用模型进行预测的过程
测试样本/预测示例:被预测的样本
监督学习:训练数据有标记信息
无监督学习:训练数据无标记信息
二. 假设空间——从“归纳”与“演绎”说起
归纳,是从特殊到一般的“泛化”过程。
演绎,是从一般到特殊的“特化”的过程。
显然,机器学习,是从训练集的有限的数据中,得出“泛化”的模型,得到最后的假设,即结果。因此,进行学习的过程,实质也就是从“所有假设组成的空间中”(这就是假设空间定义)进行搜索,搜索目标是找到与训练集得以匹配的假设。
好瓜→(色泽=*)^(根蒂=*)^(敲声=*)(*表示通配符,此处意为可能会取任何属性值)上面这行,即为选西瓜例子中的假设空间。
虽然目标为获得与训练集一致的假设即可,但实际情况中,由于假设空间特别大,往往会有多条假设都能满足条件。
一般的,我们把这些满足条件的假设组成的集合称为“版本空间”。
三. 归纳偏好
实际情况中,由于版本空间的问题,导致与它们对应的样本面临新样本的时候,输出结果可能千差万别。
因此,我们的学习算法,必须要有一定的“偏好”。
一般的,机器学习算法在学习过程中,对某种类型假设的偏好,称为“归纳偏好”or“偏好”
例如,如果算法喜欢更泛化的模型,它可能会选择:
好瓜→(色泽=*)^(根蒂=蜷缩)^(敲声与此同时,如果算法喜欢更特殊的模型,它可能会选择:
好瓜→(色泽=*)^(根蒂=蜷缩)^(敲声=沉闷)这里需要强调一点在于,上述两种算法,未必有高低之分。因为训练集和测试集的数据是不一样的。我们是不能确定,泛化性能好一些的表现更好,还是泛化性能差一些的表现更好的。因此,我们接下来要论述NFL定理。
NFL定理,No Free Lunch定理。具体含义指: 针对某一域的所有问题,所有算法的期望性能是相同的
对于“二分类问题”而言,有如下式子
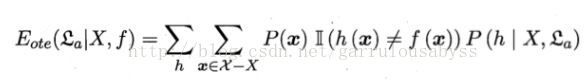 (1.1)
(1.1)
其中:
(1)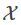
代表“样本空间”,
 为“假设空间”,这两者都是离散的。
为“假设空间”,这两者都是离散的。
(2)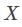 为“训练数据”,故
为“训练数据”,故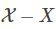 的意义是“训练集外”。这是因为算法性能,是通过衡量训练集外误差得到的,即 off-training error(ote)
的意义是“训练集外”。这是因为算法性能,是通过衡量训练集外误差得到的,即 off-training error(ote)
(3) 表示当使用算法
表示当使用算法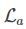 时,基于训练集
时,基于训练集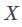 ,产生假设
,产生假设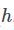
的概率。
我们可以设"我们希望学习的真实函数”是f。这里我们假设其均匀分布(请注意这里这个假设!后面会提及!)则对于某确定的算法,对所有可能的f的误差进行求和。(1.1)式变为:
 (1.2)
(1.2)
然后因为乘法交换律,显然的(1.2)变为:
 (1.3)
(1.3)
上面从左往右依次有三项。
考虑一下,最后一项,其实类似于一个期望,而由于f是一个均匀分布的。对所有的f之和,这项实质是,总的样本空间大小的一半。
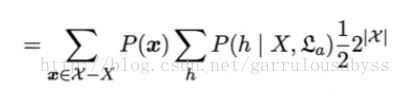 (1.4)
(1.4)
对(1.4)而言,中间这项,由于是对训练集训练出的所有可能的h进行求和。显然这个概率一定为零(其实就是全概率公式。如果有点想不明白,就联想,对于骰子摇到6个面的概率之和,显然为1)
因此(1.4)变为:
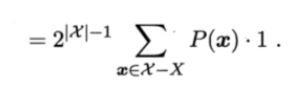 (1.5)
(1.5)
注意上式中,与你具体采用何种算法是无关的!
回顾一下我们最初给出的结论。NFL定理指: 针对某一域的所有问题,所有算法的期望性能是相同的。
细心阅读的读者,应该还记得我在前面强调过,在推导公式的时候,我们假设,我们希望学习的真实函数是“均匀分布”的。然而事实是,在实际情况中。所有问题出现的机会并不是相同,或者说,这些问题并不是同等重要的。
也因此,NFL定理最大的意义,其实在于告诉我们,脱离具体问题,空泛的谈论,哪一种学习算法更好,是没有意义的。
(第一章完)