西瓜书 周志华 机器学习第一章 绪论
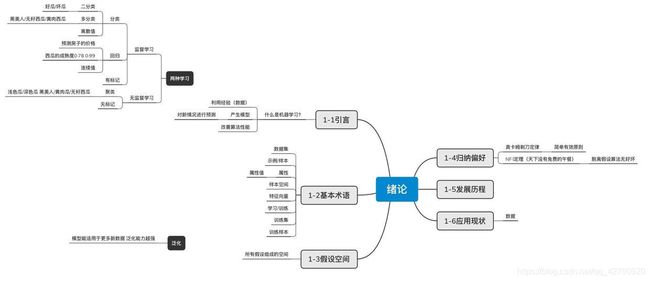
1.什么是机器学习?
人区别于机器,更多是基于经验累积起来的个体。比如今天我起床看见天空有点儿灰暗,没有太阳,那我就可以初步预判今天应该是会下雨。走在路上发现,风越吹越大,蜻蜓也在低飞,天越来越黑,这时你知道要下雨了,而且根据以往十几年来的经验判断,这雨还不小,我得赶紧找个地方躲起来。
人呢 遇到事多了,就积累了经验,从而下次有新的情况时,能用经验做出判断和决策。机器学习,与以往的你编程让机器做什么它就做什么不同,它就是让机器像人一样有‘思维’ 。
对于机器来说,经验通常以数据的形式存在,有了很多数据之后就可以建立起数据模型。数据模型在下次的新情况中,就能帮助你给你做出决策和判断(预测)。
机器学习的主要研究内容呢,就是在计算机上从数据中产生模型的算法,即学习算法。机器学习的过程,也是个不断优化算法的过程。通过大量的数据,使得预测结果一步步接近数据的真实值。
机器学习就先得有数据,那就先来看一些关于数据的术语吧
2.机器学习的基本术语
现在路边有一卡车西瓜,你要挑个好的带回家,你也不会挑你找卖瓜的小哥卖个萌让他给你挑。他挑了个色泽青绿、根蒂卷曲、敲声浊响的西瓜,带回家果然是个好瓜。
数据集:样本的集合 就是这一卡车西瓜
示例:((色泽=青绿;根蒂=卷曲;敲声=浊响),好瓜) 这就是个示例 卡车里挑出来的一个好瓜
属性:色泽 根蒂 敲声
属性值 :每个属性有属性值 色泽的属性值就是青绿啊乌黑啊 根蒂的属性值就是卷曲啊直的啊 等等
特征向量 :把色泽/根蒂/敲声分别设为x/y/z 每个属性的属性值会对应在各自的坐标轴上找到自己的对应位置 比如(1,2,3) 是((色泽=青绿;根蒂=卷曲;敲声=浊响),好瓜) 这组数据的位置
属性空间 :这堆特征向量加起来生成一个三维空间 每个特征向量可以在属性空间找到自己的点
好的,现在你想天天吃西瓜,于是你也想卖瓜,那你要学挑好瓜嘛。然后现在我就去西瓜园里学挑西瓜了,从数据中学得模型的过程叫做学习或训练。
训练集:这次在西瓜园里的你挑过的所有西瓜 机器训练的数据的集合
训练样本:西瓜园里挑过的每一个西瓜 机器训练的数据个体
假设:挑了那么多西瓜后 得出的好瓜的某种规律
真相/真实:好瓜它自带的规律
学习的过程就是让假设越来越逼近真相啦!
标记/标签:((色泽=青绿;根蒂=卷曲;敲声=浊响),好瓜)
样例:带有标记的样本 有个瓜被你写上这是个好瓜 就能拿来做样例
3.监督学习和无监督学习
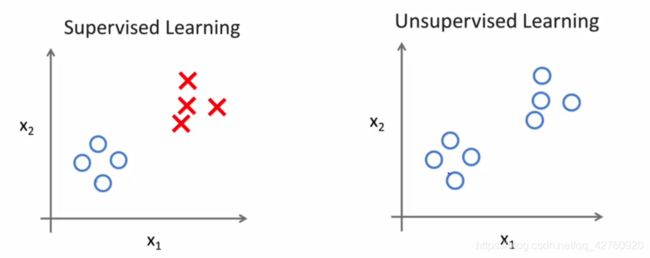
(1) 监督学习 (分类与回归)
监督学习是指监给机器一定的数据集,数据集里每个元素都有相应的正确标签,让机器学习这些数据集,来训练出可以达到预期相应的正确标签的模型。也就是说给定机器学习的目标,告诉它这些数据你要怎么分怎么处理,以后的数据让自己去学习着处理,就监督了它学习嘛。
分类:离散值 可分二分类和多分类
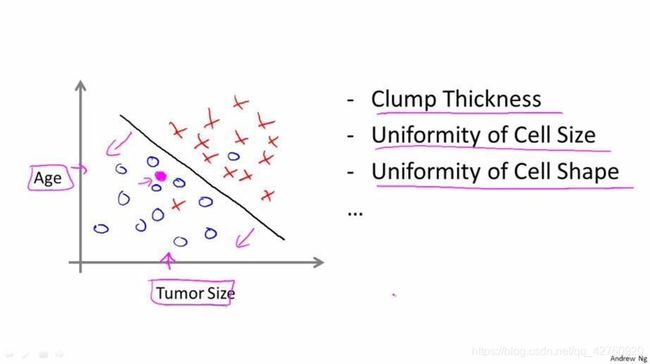
二分类:通常是一组对立两面的数据
好瓜 坏瓜/是恶性肿瘤 是良性肿瘤
患者年龄和肿瘤大小
多分类:两个以上的分类
黑美人/无籽西瓜/黄肉西瓜 根据得肿瘤年龄和年龄大小分类

西瓜成熟度0.77 0.99/房子的价格20万 30万
(2) 无监督学习(聚类)
不同于监督学习,无监督学习的数据没有告诉学习算法“正确答案”,就是一个普通的数据集,无监督学习算法可以把这些数据集分成不同的簇(聚类算法)。就是说丢堆数据给机器,我也不教机器分,你自己看着数据的共同特征去分成不同的类,自己学着去吧,就是无监督学习。
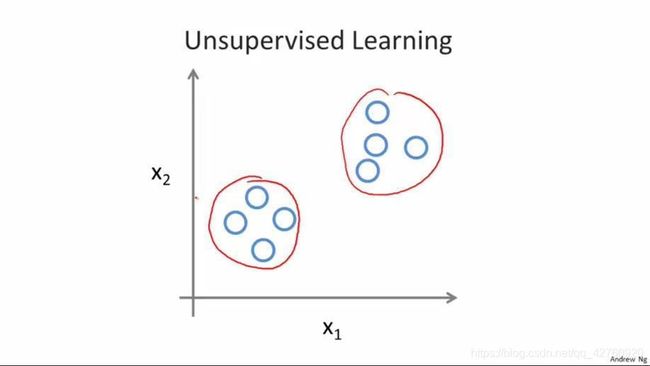
比如对西瓜做聚类,即将训练集的西瓜分为若干组,每组成为一个簇。这些自动形成的簇,可能对应着一些潜在的划分, 如‘本地瓜’‘外地瓜’ ,‘浅色瓜’‘深色瓜’ ,这样的学习过程能更好的了解数据内在规律,这个过程中数据一般是不拥有标签信息的。
(3)泛化
如果用某个数据集的样本训练出的一个模型(假设函数),能够适用于新的样本数据,就说这个模型具有泛化能力。模型能适用于越多的新数据,则说明其泛化能力越强。
4.假设空间
假设空间是指所有可能假设组成的空间,也可以说是所有在表达形式上符合任务要求的假设函数的集合。
打个比方,现在要判断一个人是男孩还是女孩。分别有属性值:喉结(有喉结/没喉结)头发(光头/长头发/短头发)皮肤(白皙水嫩/乌黑粗糙)这3个属性和括号内的各属性值,然后又不排除有第三种性别的说法(男人、女人、女博士)纯属调侃哈哈这种极端的情况,那它的假设空间就有233+1=19这么大。反正呢,就是得把各种情况考虑进去。
5 归纳偏好
奥卡姆剃定律:如果关于同一个问题有许多解决方法,每一种都能作出同样准确的预言,那么应该挑选其中使用假定最少的。尽管越复杂的方法通常能做出越好的预言,但是在不考虑预言能力(即结果大致相同)的情况下,假设越少越好。
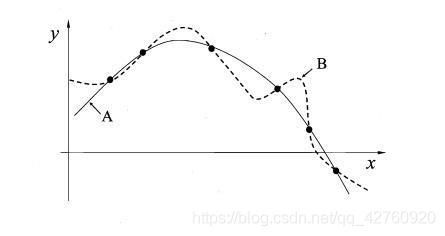
康康A曲线就很简洁大气,用一个抛物线函数就能表达出来 ,而B就看起来复杂很多,我和奥卡姆剃都觉得A很不错哈哈哈。
NFL定理:“没有免费的午餐(No Free Lunch theorem, NFL)”:无论学习算法“聪明”与否,他们的期望值相同。一个重要前提:所有问题出现的机会相同,但实际情况更多是不相同。
这里我来分享一个我在一个浙大人工智能老师的讲课那里看来的关于讲这个定理的小故事,感觉挺好玩的。
有这样一个农夫养了一只鸡,每次要喂这只鸡吃饭呢,就把吃的放草丛里面,他就摇铃铛赶着鸡去草丛里。这样过去两个多星期,鸡就知道嘛,这个铃铛声一出来,就是要开饭了 ,它就自己往草丛里冲。直到后来两年后这只鸡越养越肥,在一个风和日丽的早上,农夫一摇铃铛,鸡往草丛里冲,进然后它就被杀了吃了。
这个故事告诉我们的是要减肥吗?当然不是。就是呢,我们机器学习,用算法很多时候,都是希望它预测出拟合于鸡每天冲出去有饭吃的情况。就跟我们每天早上醒来太阳会从东边升起一样,大大大多时候都是这样的。但是呢,事实上像鸡突然有一天就被吃了的可能性也是存在的。
天下没有免费的午餐这个定理的意思就是说,鸡有得吃和鸡被吃两种可能性都是等同的,那它的算法的假设情况都应该是等同概率发生的,那这样整那么多算法都一样嘛,那算法就没优劣之分。但是呢,在我们的实际情况中,更多还是偏向于听到铃铛声鸡有得吃,就像我们觉得,明天太阳照常东边升起一样。所以呢,我觉得算法是相对的优劣,根据自己的偏好去选择算法,解决不同的问题,才有优劣这一说法。
后面的关于发展史和应用我就不叨叨了,毕竟我记人名的能力真的是… 看应用这一块,我觉得感触最深就是数据这个词,数据真的是这个信息时代的名片。很多时候人与人之间智商真没多大差别,之所以会被拉开差距,还是因为数据和信息。有的人特别的优秀,什么领域都能多多少少贯通,也是它们在信息的处理整合和吸收外来数据信息方面有自己的一套方法和敏锐的洞察能力。一个好的算法是这样的,人也是一样的。在觉得有点迷茫的时候,或许可以试一下把接触到的那么多的信息做个取舍再整合,得出一套自己的规划模型,可能会活得有方向些。这是我最近接触AI,读这本西瓜书看了和一些有关AI的视频后的感受。
: