【机器学习入门】(4) 决策树算法理论:算法原理、信息熵、信息增益、预剪枝、后剪枝、算法选择
各位同学好,今天我向大家介绍一下python机器学习中的决策树算法的基本原理。内容主要有:
(1) 概念理解;(2) 信息熵;(3) 信息增益;(4) 算法选择;(5) 预剪枝和后剪枝。
python决策树算法案例实战在下一篇文章中介绍。那我们开始吧。
【机器学习】(5) 决策树算法实战:sklearn实现决策树,实例应用(沉船幸存者预测)附python完整代码及数据集
1. 决策树概念
通过不断的划分条件来进行分类,决策树最关键的是找出那些对结果影响最大的条件,放到前面。
我举个列子来帮助大家理解,我现在给我女儿介绍了一个相亲对象,她根据下面这张决策树图来进行选择。比如年龄是女儿择偶更看中的,那就该把年龄这个因素放在最前面,这样可以节省查找次数。收入高的话就去见,中等的话还要考虑工作怎么样。
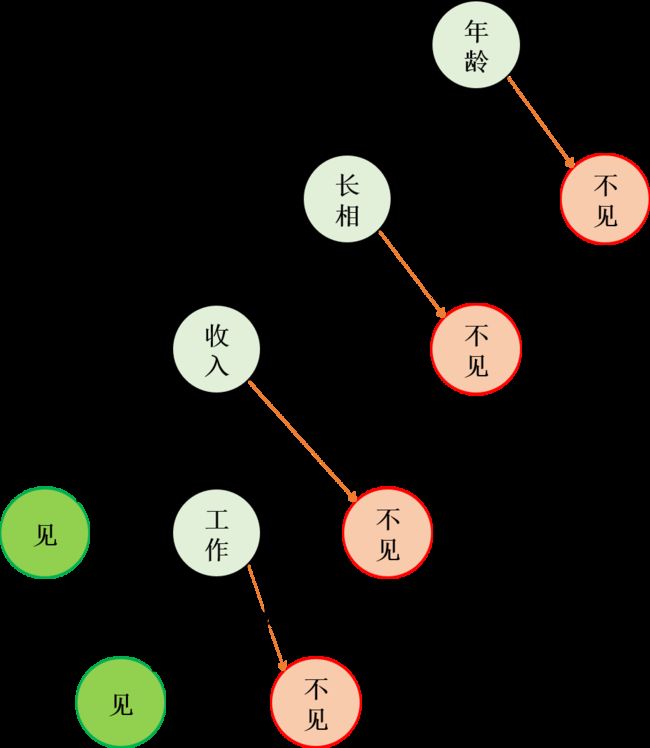
决策树通过历史数据,找出数据集中对结果影响最大的特征,再找第二个影响最大的特征。若新来一个数,只要根据我们已经建立起的决策树进行归类即可。
2. 决策树的信息熵
用来表示随机数据不确定性的度量,信息熵越大,表示这组数据越不稳定,而信息熵越小,则数据越稳定、越接近、越类似。
信息熵公式: 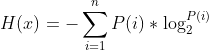
H(x)表示信息熵,P(F1,F2,…) 表示数据在整个数据集中出现的概率。
我举个例子帮助大家理解:
A = [1,1,1,1,1,1,1,1,2,2] #1出现了8次,2出现了2次
B = [1,2,3,4,5,6,7,8,9,10]
此时计算A、B的信息熵:
![]()
![]()
B的信息熵比A大得多,因此数据A更加稳定,若将A和B放到决策树中考虑信息熵,A熵更小更稳定,放到最前面判断。
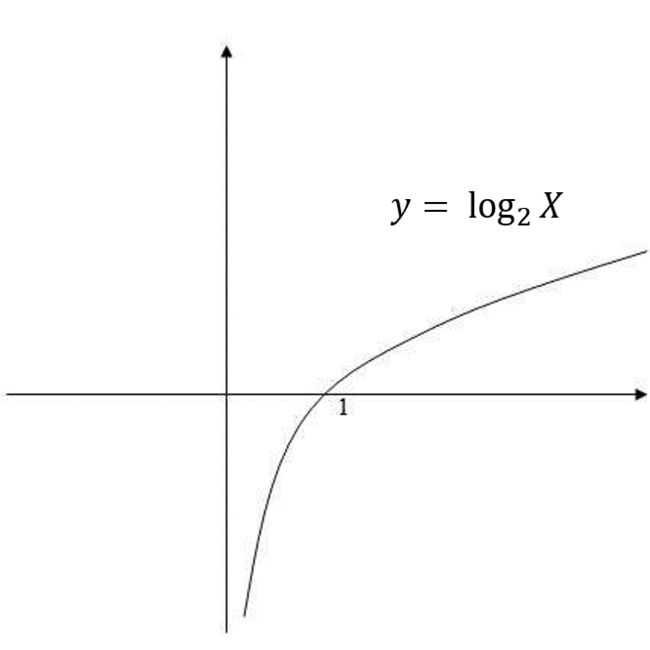
我们看一下 ![]() 曲线再来理解一下信息熵公式。首先,公式中的P(i)永远是在0-1之间的,因此
曲线再来理解一下信息熵公式。首先,公式中的P(i)永远是在0-1之间的,因此 ![]() 是一个负数,因此在整个式子前面填一个负号,使结果H(x)为正。P(i)概率越大,log越小,信息熵越小,P(i)概率越小,信息熵越大,越不稳定。
是一个负数,因此在整个式子前面填一个负号,使结果H(x)为正。P(i)概率越大,log越小,信息熵越小,P(i)概率越小,信息熵越大,越不稳定。
3. 信息增益
表示特征x使得值y的不确定性减小的程度。信息增益越大,表示对不确定性的减少就越多,越能更清晰地分类。
特征A对训练集D的信息增益记作 ![]() ,定义为:集合D的信息熵H(D)与特征A给定条件下D的经验条件熵
,定义为:集合D的信息熵H(D)与特征A给定条件下D的经验条件熵 ![]() 之差。
之差。
特征A对事件D的信息增益: 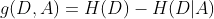
A条件下D的信息熵记作H(D|A),A特征中可能有N种值(A1,A2,..)
特征A条件下D的信息熵: 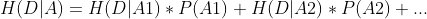
下面我用一个例子(贷款案例的信息增益)来帮助大家理解:

数据集中,有年龄、工作、房子、信誉等4个特征来判断是否应该给这个用户贷款。在决策树中,将哪个特性放在最前面判断,哪个特性放到最后面,需要通过计算信息增益来决定。
首先计算年龄对能否贷款的信息增益
A = 年龄,A1 = 青年,A2 = 中年,A3 = 老年,D = 贷款
年龄对贷款的信息增益为:
在能否贷款的这个集合中,有9个人能贷款,6个人不能贷款,计算其信息熵
贷款的信息熵:
在年龄这个特征下,15个人中有5个青年,5个中年,5个老年
在年龄特征下贷款的信息熵:
![]()
以青年为例,15个人中有5个青年,其中3个能贷款,2个不能贷款
![]()
![]()
![]()
年龄对贷款的信息增益是:
H(贷款|年龄) = ![]()
同理,是否有工作的信息增益为0.32;是否有房的信息增益为0.42;信贷情况的信息增益为0.363。建立决策树时根据信息增益从大到小排序,先考虑有没有房,再考虑信贷情况,再考虑有没有工作,最后考虑年龄。
4. 决策树算法选择
4.1 ID3
方法介绍:采用信息增益来进行决策树的创建,尽管效果不错,但是他会选择分支更多的属性,会导致过拟合,一般不采用此方法。
如果有一组特征都是相互独立的,如B=[1,2,3,4,5,6,7,8,9,10],
计算信息增益: ![]()
![]()
A1代表数字1,出现概率为1/10,在1的条件下出现数字1的概率为1/1
![]()
因此 ![]()
该方法会导致分支多的属性的信息增益很大,导致决策树不准确,比如上个贷款案例中,如果将第一列ID,即1-15这几个序列数,当作特征去计算,得到的信息增益会特别大,在建立决策树时,把序列这一列放到决策树最前面,然而实际上,序列这一列是对结果没有丝毫影响的。
4.2 C4.5
由于ID3方法会导致过度拟合,因此我们通过对分支过多的情况进行惩罚,引入信息增益比gr。
信息增益比 = 某特征的信息增益 / 某特征的信息熵
![]()
如果某特征分类特别多,会导致信息熵非常大,从而信息增益会变得非常大,对它进行惩罚,进行有效抑制。
4.3 CART
C4.5方法尽管能较好地构建决策树算法,但在计算时需要不断求对数log,对算法的效率有一定影响。在CART算法中采用基尼系数(Gini)来进行分类,Gini系数是一种与信息熵类似的做特征选择的方式。基尼系数越大说明数据越复杂越混乱,越小说明越平均越集中。
基尼系数通常用于描述一个国家财富分配情况,超过0.4说明贫富差距很大,0.3左右说明财富分配水平均匀。
基尼系数公式: 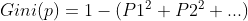
![]() 代表某一个特征中每一个值出现的概率
代表某一个特征中每一个值出现的概率
上个例子中的年龄的基尼系数是:Gini(年龄) = 1 – (5/15)^2 - (5/15)^2 - (5/15)^2
在建立决策树时,基尼系数越小的,就把它放在最前面。
5. 预剪枝和后剪枝
树的层级和叶子节点不能过于复杂,如果过于复杂,会导致过拟合现象(过拟合:训练时得分很高,测试时得分很低)。预剪枝和后剪枝都是为了防止决策树太复杂的手段
5.1 预剪枝
在决策树的建立过程中不断调节来达到最优,可以调节的条件有:
(1)树的深度:在决策树建立过程中,发现深度超过指定的值,那么就不再分了。
(2)叶子节点个数:在决策树建立过程中,发现叶子节点个数超过指定的值,那么就不再分了。
(3)叶子节点样本数:如果某个叶子结点的个数已经低于指定的值,那么就不再分了。
(4)信息增益量或Gini系数:计算信息增益量或Gini系数,如果小于指定的值,那就不再分了。
优点:预剪枝可以有效降低过拟合现象,在决策树建立过程中进行调节,因此显著减少了训练时间和测试时间;预剪枝效率比后剪枝高。
缺点:预剪枝是通过限制一些建树的条件来实现的,这种方式容易导致欠拟合现象:模型训练的不够好。
5.2 后剪枝
在决策树建立完成之后再进行的,根据以下公式:
C = gini(或信息增益)*sample(样本数) + a*叶子节点个数
C表示损失,C越大,损失越多。通过剪枝前后的损失对比,选择损失小的值,考虑是否剪枝。
a是自己调节的,a越大,叶子节点个数越多,损失越大。因此a值越大,偏向于叶子节点少的,a越小,偏向于叶子节点多的。
优点:通常比预剪枝保留更多的分支,因此欠拟合风险比预剪枝要小。
缺点:但因为后剪枝是再数建立完成之后再自底向上对所有非叶子节点进行注意考察,因此训练时间开销比预剪枝要大。