前馈神经网络(多层感知机)基础
前馈神经网络(多层感知机)基础
- 1. 神经网络介绍
-
- 1.1 神经网络的生物学背景
- 1.2 人工神经元与感知机
- 1.3 常用激活函数
-
- 1.3.1 线性函数(Linear Function)
- 1.3.2 斜面函数(Ramp Function)
- 1.3.3 阈值函数(Threshold Function)
- 1.3.4 sigmoid函数
- 1.3.5 双曲正切函数(tanh函数)
- 1.3.6 ReLU (Rectified Linear Regression,整流线性单元)
- 2. 单层感知机(单层神经网络,线性回归)
-
- 2.1 单层感知机模型
- 2.2 感知机的几何解释
- 2.3 单层感知机 与 线性分类任务
- 2.4 单层感知机的缺陷
- 3. 多层感知机(前馈神经网络)
- 4. 反向传播
1. 神经网络介绍
神经网络的定义:人工神经网络(Artificial Neural Networks,简写为ANNs)也简称为神经网络(NNs)或称作连接模型(Connection Model),它是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。这种网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的。
1.1 神经网络的生物学背景
-
神经细胞的工作机制
神经元理论(neurons theory):神经细胞之间是相互独立的,通过某种形式传递信号。 -
神经元学说
(1) 神经网络由许多独立的神经细胞个体(“神经元”),通过神经元之间的接触点联接而成;
(2) 所有神经元都具有不对称的极性结构:一边有一枝很长的“轴突”纤维状突起,另一边有许多“树突”。树突(dendrites) 是接收其他神经元输入信息的结构,而 轴突(axon) 则是神经元将信息传向远方的输出结构;
(3) 基于神经组织的发育、退化和再生的结构变化,卡哈尔 还首先提出了神经联接的可塑性概念;
(4) 树突接收信息,触发区整合电位,产生神经冲动,末端的突触为输出区,从而向下一个神经元传递。人脑神经系统包含近860亿个神经元,每个神经元有千个突触(synapse)。
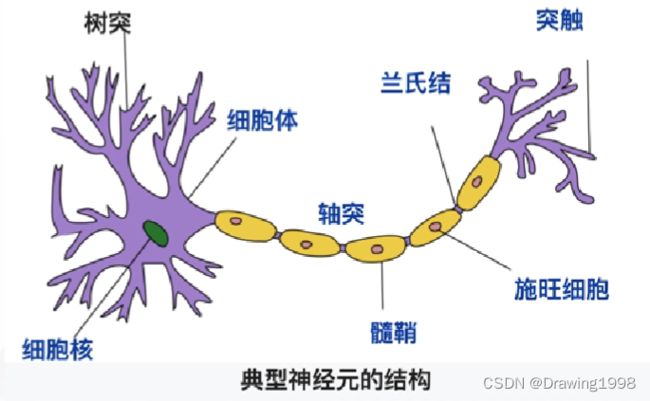
- 生物神经网络的假定特点:
(1) 每个神经元都是一个 多输入单输出 的信息处理单元;
(2) 神经元输入 分 兴奋性输入 和 抑制性输入 两种类型;
(3) 神经元具有 空间整合特性 和 阈值特性;
(4) 神经元输入与输出间有固定的 时滞,主要取决于突触延搁
1.2 人工神经元与感知机
1943年心理学家 W.S.McCulloch 和 数理逻辑学家 W.Pitts 提出 按照生物神经元的结构和工作原理构造出来的抽象和简化模型—— M-P模型。此类模型通常将神经元形式化为一个「激活函数复合上输入信号加权和」的形式。
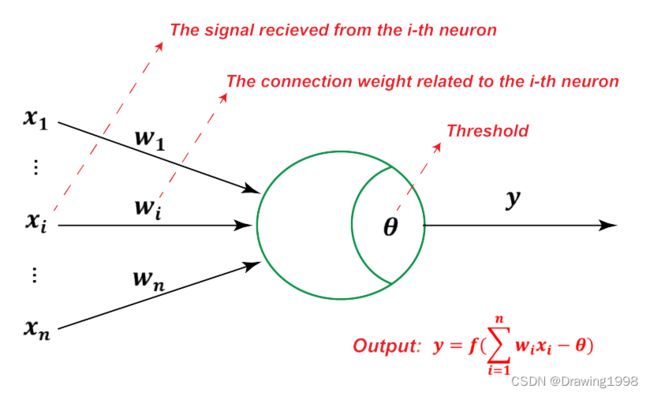
M-P 模型接收到来自 n n n 个其他神经元传递过来的输入信号 x i x_i xi,这些输入信号通过带权重的连接 w i w_i wi 进行传递,神经元接收到的总输入值 将与 神经元的阈值 θ \theta θ 进行比较,然后通过激活函数 f f f 处理以产生神经元的输出。即:
f ( ∑ i = 1 n w i x i − θ ) f(\sum^n _{i=1} w_i x_i - \theta ) f(i=1∑nwixi−θ)其中, x i x_i xi 表示来自其他神经元的信号, w i w_i wi 表示对应的连接权重, θ \theta θ 表示神经元的阈值, f f f 表示通常连续可微的激活函数(Activation Function)(或称 转移函数(Transfer Function))。
- 神经元激活与否取决于阈值水平 θ \theta θ,即只有当其输入总和超过阈值 θ \theta θ 时,神经元才被激活而发放脉冲,否则神经元不会发生输出信号。
- 当神经元被激活时,称该神经元处于激活状态或兴奋状态,反之称神经元处于抑制状态。
1.3 常用激活函数
1.3.1 线性函数(Linear Function)
f ( x ) = k x + c f(x) = kx + c f(x)=kx+c
1.3.2 斜面函数(Ramp Function)
f ( x ) = { T , x > c k x , ∣ x ∣ ⩽ c − T , x < − c f(x) = \begin{cases} T,\,\, x>c\\ kx,\,\, |x|\leqslant c \\ -T,\,\, x < -c \end{cases} f(x)=⎩ ⎨ ⎧T,x>ckx,∣x∣⩽c−T,x<−c
1.3.3 阈值函数(Threshold Function)
f ( x ) = { 1 , x ⩾ c 0 , x < c f(x) = \begin{cases} 1,\,\, x \geqslant c\\ 0,\,\, x < c \end{cases} f(x)={1,x⩾c0,x<c
1.3.4 sigmoid函数
Sigmoid函数 是一个在生物学中常见的S型函数,也称为S型生长曲线。在信息科学中,由于其单增以及反函数单增等性质,Sigmoid函数常被用作神经网络的激活函数,将变量映射到0,1之间。
sigmoid函数 也叫 Logistic函数,用于隐层神经元输出,取值范围为(0,1)(0表示“抑制”,1表示“兴奋”),它可以将一个实数映射到(0,1)的区间,可以用来做二分类。在特征相差比较复杂或是相差不是特别大时效果比较好。Sigmoid作为激活函数有以下优缺点:
- 优点:平滑、易于求导。
- 缺点:激活函数计算量大,反向传播求误差梯度时,求导涉及除法;反向传播时,很容易就会出现梯度消失的情况,从而无法完成深层网络的训练。
Sigmoid 函数定义:
S ( x ) = 1 1 + e − x S(x) = \frac{1}{1 + e^{-x}} S(x)=1+e−x1
对 x x x 进行求导:
S ′ ( x ) = e − x ( 1 + e − x ) 2 = S ( x ) ( 1 − S ( x ) ) S'(x) = \frac{e^{-x}}{(1 + e^{-x})^2} = S(x)(1 - S(x)) S′(x)=(1+e−x)2e−x=S(x)(1−S(x))
Sigmoid函数的图形:

1.3.5 双曲正切函数(tanh函数)
t a n h ( x ) = e x − e − x e x + e − x tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} tanh(x)=ex+e−xex−e−x函数图像为:
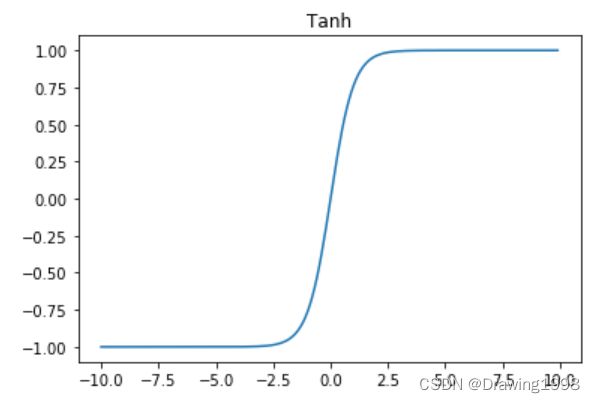
sigmoid函数 和 tanh函数 是研究早期被广泛使用的2种激活函数。两者都为S 型饱和函数。 当 sigmoid 函数 输入的值趋于正无穷或负无穷时,梯度会趋近零,从而发生梯度弥散现象。sigmoid函数 的输出恒为正值,不是以零为中心的,这会导致权值更新时只能朝一个方向更新,从而影响收敛速度。tanh 激活函数是 sigmoid 函数的改进版,是以零为中心的对称函数,收敛速度快,不容易出现 loss 值晃动,但是无法解决梯度弥散的问题。2个函数的计算量都是指数级的,计算相对复杂。softsign 函数是 tanh 函数的改进版,为 S 型饱和函数,以零为中心,值域为(−1,1)。
为什么 LR 模型要使用 sigmoid 函数,背后的数学原理是什么?
1.3.6 ReLU (Rectified Linear Regression,整流线性单元)
在现代神经网络中,默认的推荐是使用 由激活函数 g ( z ) = m a x { 0 , z } g(z) = max \{ 0, z \} g(z)=max{0,z} 定义的 整流线性单元 (Rectified Linear Regression) 或者称为 ReLU。
通常意义下,线性整流函数指代数学中的斜坡函数,即 f ( x ) = m a x { 0 , x } f(x) = max \{ 0, x \} f(x)=max{0,x} 。
而在神经网络中,线性整流作为神经元的激活函数,定义了该神经元在线性变换 w T x + b w^Tx + b wTx+b 之后的非线性输出结果。换言之,对于进入神经元的来自上一层神经网络的输入向量 x x x ,使用线性整流激活函数的神经元会输出 m a x ( 0 , w T x + b ) max(0, w^Tx + b) max(0,wTx+b) 。
2. 单层感知机(单层神经网络,线性回归)
2.1 单层感知机模型
1957年,Frank Rosenblatt 结合 M-P模型 和 Hebb学习规则 发明了 感知机(perceptron),两层神经网络,结构与MP模型类似,一般视为最简单的人工神经网络。
感知机 与 MP模型 的区别:输入不是离散的 0/1,激活函数不一定是 阈值函数。
感知机模型的组织结构如下:
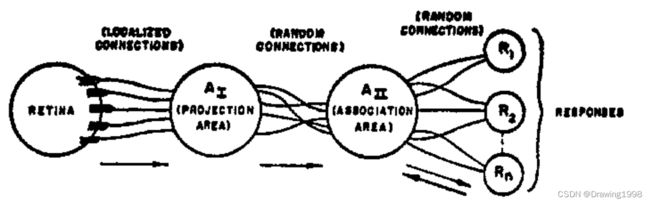
对应的简化图为:

后经进一步的发展、变形,成为现在常用的经典形式,由于只有一层,又被称为 单层感知机。如下:
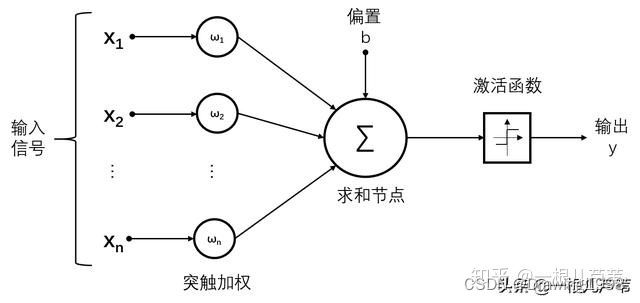
和M-P模型相比,感知机引入了偏置b。用公式表示为:
f ( x ) = s i g n ( w x + b ) f(x) = sign(wx + b) f(x)=sign(wx+b)其中, s i g n ( x ) sign(x) sign(x) 为激活函数:
s i g n ( x ) = { + 1 , x ⩾ 0 − 1 , x < 0 sign(x) = \begin{cases} +1,\,\, x \geqslant 0\\ -1,\,\, x < 0 \end{cases} sign(x)={+1,x⩾0−1,x<0分别对应“激活” 和 “抑制” 两种状态。
2.2 感知机的几何解释
由于 w x + b = 0 wx + b = 0 wx+b=0 相当于 n n n 维空间中的一个超平面, w w w 为超平面的法向量, b b b 为超平面的截距, x x x 为空间中的点。
- 当 x x x 位于超平面的正侧时, w x + b > 0 wx + b > 0 wx+b>0 ,感知机被激活;
- 当 x x x 位于超平面的负侧时, w x + b < 0 wx + b < 0 wx+b<0 ,感知机被抑制。
所以,从几何的角度来看,感知机就是 n n n 维空间中的一个超平面,它将特征空间分成两部分。

2.3 单层感知机 与 线性分类任务
由于感知机具有的这种分离超平面的特性,常用来对数据进行分类。
首先给定一组训练数据,然后通过训练数据确定模型的参数ω、b,最后用学到的模型预测新数据的类别。
假定给定的训练数据为: T = ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) T = (x_1, y_1), (x_2, y_2), ... , (x_N, y_N) T=(x1,y1),(x2,y2),...,(xN,yN) ,其中, x i ∈ X = R n , y ∈ { + 1 , − 1 } , i = 1 , 2 , . . . , N x_i \in X = R^n, y \in \{ +1, -1 \}, i = 1,2,...,N xi∈X=Rn,y∈{+1,−1},i=1,2,...,N
学习的目标就是找一个能将训练数据中正负实例都分开的超平面。
求解方法:参数初始化 + 梯度下降法更新
求得的解并不是数学意义上的解析解,而是工程意义上的最优解(不是唯一的,只要得到一个比较好的结果就可以)。
2.4 单层感知机的缺陷
Minsky 在1969年出版 《感知器》书中证明了 Perceptron 无法解决异或问题。
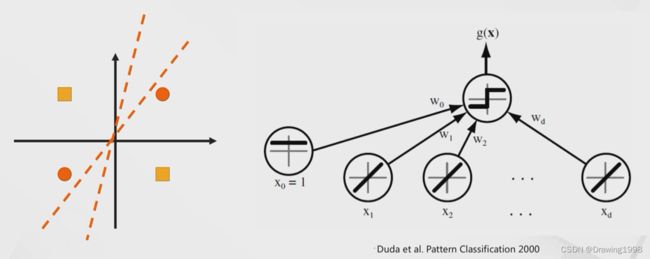
3. 多层感知机(前馈神经网络)
Multi Layer Perception, MLP:在单层神经网络基础上引入一个或多个隐藏层,使网络有多个网络层,被称为 多层感知机,或 前馈神经网络。
从理论上说,多层网络可以模拟任何复杂的函数。

从上图可以看到,多层感知机层与层之间是全连接的。多层感知机最底层是输入层,中间是隐藏层,最后是输出层。
MLP没有限定隐藏层的数量,对于输出层神经元的个数也没有限制,所以我们可以根据各自的需求选择合适的隐藏层层数。
多层感知机的表达能力:解决了异或问题 (XOR)。

为什么要使用激活函数?
- 不使用激活函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合。
- 使用激活函数,能够给神经元引入非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以利用到更多的非线性模型中。
激活函数需要具备以下几点性质:
- 连续并可导(允许少数点上不可导)的非线性函数。可导的激活函数可以直接利用数值优化的方法来学习网络参数。
- 激活函数及其导函数要尽可能的简单,有利于提高网络计算效率。
- 激活函数的导函数的值域要在一个合适的区间内,不能太大也不能太小,否则会影响训练的效率和稳定性。
4. 反向传播
前面介绍了前馈神经网络,那么问题来了:神经网络该如何进行优化呢?
1986年,Rummelhart 和 McClelland 改进反向传播算法(back propagation, BP) 用于优化神经网络,因此神经网络也常被称为 BP神经网络。
- 前向传播 (forward propagation) 通过训练数据和权重参数计算输出结果;
- 反向传播(back propagation) 通过导数链式法则计算损失函数对各参数的梯度,并根据梯度进行参数的更新。

注:反向传播仅指损失函数对参数的梯度通过网络反向流动的过程,但现在也常被理解成神经网络整个的训练方法,由误差传播、参数更新两个环节循环迭代组成。
参考:
[1] 天池课程:深度学习原理与实践
[2] 《深度学习》(花书)
[3] 神经网络学习 之 M-P模型
[4] 神经网络的基础是MP模型?南大周志华组提出新型神经元模型FT
[5] The perceptron: a probabilistic model for information storage and organization in the brain
[6] 机器学习-单层感知机
[7] 多层感知机(MLP)简介
[8] 机器学习基础篇(十二)——多层感知机
[9] 深度学习 | 反向传播详解