知识蒸馏、模型剪枝与量化
1. 知识蒸馏
1.1 知识蒸馏简介
知识蒸馏是一种模型压缩常见方法,用于模型压缩指的是在teacher-student框架中,将复杂、学习能力强的网络学到的特征表示“知识”蒸馏出来,传递给参数量小、学习能力弱的网络。蒸馏可以提供student在one-shot label上学不到的soft label信息,这些里面包含了类别间信息,以及student小网络学不到而teacher网络可以学到的特征表示‘知识’,所以一般可以提高student网络的精度。
Hinton在NIPS2014提出了知识蒸馏(Knowledge Distillation)的概念,旨在把一个大模型或者多个模型集学到的知识迁移到另一个轻量级单模型上,方便部署。简单的说就是用新的小模型去学习大模型的预测结果。好模型的目标不是拟合训练数据,而是学习如何泛化到新的数据。所以蒸馏的目标是让student学习到teacher的泛化能力,理论上得到的结果会比单纯拟合训练数据的student要好。另外,对于分类任务,如果soft targets的熵比hard targets高,那显然student会学习到更多的信息。
1.2 典型蒸馏方法
蒸馏时的softmax比之前的softmax多了一个参数T(temperature),T越大产生的概率分布越平滑。

有三种蒸馏的目标函数:
- 使用soft targets:在蒸馏时teacher使用新的softmax产生soft targets;student使用新的softmax在transfer set上学习,和teacher使用相同的T;
- 同时使用soft和hard targets:student的目标函数是hard target和soft target目标函数的加权平均,使用hard target时T=1,soft target时T和teacher的一样。Hinton的经验是给hard target的权重小一点;
- 直接用logits的MSE。
1.3 知识蒸馏方法分类
(1) 模型蒸馏
模型集成是效果提升的一个很直观的方法,但是普通的集成方法往往需要多个模型,消耗的计算资源会比较多,这时可通过蒸馏方法来缓解这个问题。集成模型通常有较好的泛化能力,而蒸馏就是把复杂的集成模型的能力迁移到小模型中的一种方法。
(2) 数据蒸馏
什么是数据蒸馏呢?简单来说,模型不集成了,只要一个模型就可以,我变换数据然后就能得到相应的结果,把这些结果集成起来扔给学生模型去学习。
数据蒸馏有四个步骤:
- 在有标签的数据集上训练一个模型;
- 将无监督的数据通过多种数据变化后输入模型;
- 结果集成,得到伪标签;
- 使用有监督数据和有伪标签的无监督数据重新训练模型。
(3) 任务蒸馏
任务蒸馏的思想就是使用预训练的模型作为teacher,训练任务模型。在任务蒸馏时,首先有两类数据集——A和B,A是无监督数据集,B是有监督数据集。在A中训练任务模型,损失函数是交叉熵,用于计算预训练模型与student模型的输出差异。然后在B的训练集中微调student模型。
这种teacher-student的蒸馏框架比起在更大的监督数据集上的预训练依然有差距,但是这个是可以接受的,至少提供了一种无监督的更好的任务模型初始化方法。
1.4 最新蒸馏方法与应用调研
(1) FitNets : Hints for Thin Deep Nets
为什么要训练成更thin更deep的网络?a) thin:wide网络的计算参数巨大,变thin能够很好的压缩模型,但不影响模型效果;b) deeper:对于一个相似的函数,越深的层对于特征模拟的效果更好;并且从以往很多的论文、比赛中都能看出,深网络在训练结果上的优越性。此外,引入L2 正则化来计算中间层损失,size不一致的还会加回归层。
(2) Paraphrasing Complex Network: Network Compression via Factor Transfer
该文提出了一种对教师网络进行知识转移的新方法,由两个神经网络模块完成的,即解释器和翻译器。解释器以无监督的方式对教师网络进行训练,位于学生网络中的翻译器则用于模仿教师网络解释器信息。这两个辅助装置实际上是谋求构造两个网络的共享特征空间。
(3) Deep Mutual Learning
该文提出一种深度相互学习策略,在训练的过程中学生网络和教师网络可以相互合作学习,而不是单方向的学生从教师那里学习。实验表明各种网络架构都能够从相互学习策略中受益,并且在CIFAR-100和行人重识别数据集Market-1501这两个数据集上取得令人瞩目的结果,令人惊讶的是,相互学习并不需要先前强大的教师网络,只需要一组学生网络即可有效的训练,并且结果要强于有教师指导的网络。

(4) Zero-Shot Detection via Vision and Language Knowledge Distillation
Zero-shot learning,用见过的图片特征去判断没见过的图片的类别。


图(a)是Mask R-CNN框架,N proposals送入head得到N region embeddings,然后送入分类器进行分类。图(b)是ViLD的框架,其中Text Embeddings是通过Pre-trained Text Encoder产生的,将M个需要进行蒸馏的proposals同时送入左边分支和右边分支,左边分支的M个proposals经过归一化得到M region embeddings和右边分支产生的M image embeddings进行蒸馏(为了保证ViLD的region embeddings和CLIP的image embeddings映射空间一致),其他由Mask R-CNN产生的N个region embeddings按照IoU给标签,其中没有匹配标签的标记为background,并且给background增加了一个可学习的own embedding。

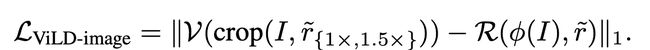
(5)General Instance Distillation for Object Detection
知识蒸馏已被证明是模型压缩的有效解决方案。这种方法可以使轻量级的学生模型获得从繁琐的教师模型中提取的知识。但是,以前的蒸馏检测方法对于不同的检测框架具有较弱的泛化性,并且严重依赖ground truth(GT),而忽略了实例之间的宝贵关系信息。我们提出了一种新的基于鉴别性实例的检测任务的蒸馏方法,该方法不考虑GT区分出的积极或消极,这称为通用实例蒸馏(GID)。

方法特点:(a) 能够将实例间的关系用于蒸馏。(b) 避免人工设定正负区域比例去选择相关区域去做蒸馏,采用了自动选择teacher和student网络中监督实例的策略。(c) 能够在各种检测任务上取得鲁棒的泛化结果,主要原因是没有使用特定检测任务或重要任务特征。
蒸馏方法组成:(a)特征层蒸馏(特征表示FPN的欧式距离);(b)结合关联信息的目标蒸馏(目标特征间欧式距离); (c)通用目标信息蒸馏(类别和embedding多任务)。
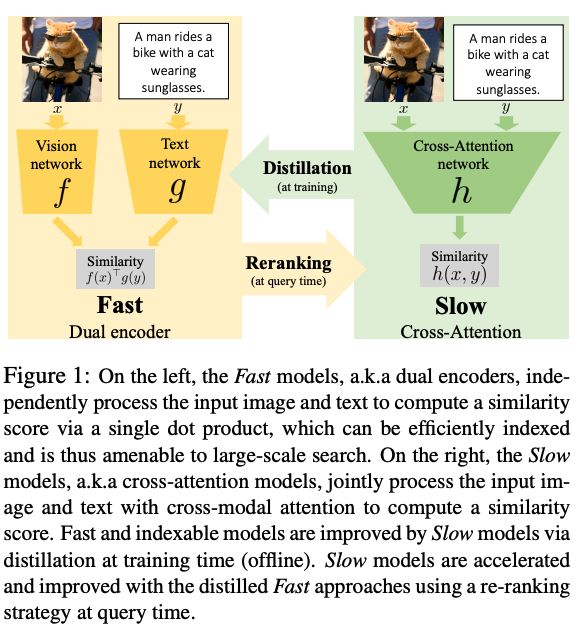
(6)Thinking Fast and Slow: Efficient Text-to-Visual Retrieval with Transformers
分别对文本和视觉进行编码,并映射到联合嵌入空间,这对于使用最近邻搜索的数十亿图像是有效的。使用交叉注意机制的视觉文本Transformer在联合嵌入的准确性上有相当大的提高,但速度较慢,通常不适用于大规模检索的实践。 这项工作结合了两者优势:首先,在 Transformer 模型基础上采用了新的细粒度交叉注意力架构,从而显着改善了检索准确性,同时保持可扩展性。其次,在训练上使用蒸馏优化文本与视觉编码精度,检索中使用交叉模型进行重新排序。
(8)Multi-Scale Aligned Distillation for Low-Resolution Detection
在实例级检测任务(例如,对象检测)中,降低输入分辨率是提高运行时效率的一个简单选项。但是,此选项传统上会严重损害检测性能。本文侧重于通过从高分辨率或多分辨率模型中提取知识来提高低分辨率模型的性能。我们首先确定将知识蒸馏 (KD) 应用于对不同输入分辨率起作用的教师和学生网络的挑战。为了解决这个问题,我们探索了通过改变特征金字塔位置来在不同输入分辨率的模型之间空间对齐特征图的想法,并引入对齐的多尺度训练来训练一个多尺度教师,该教师可以将其知识提炼成一个低分辨率的学生。此外,我们提出了交叉特征级融合,以动态融合教师的多分辨率特征,以更好地指导学生。
(9)Distilling Knowledge via Knowledge Review
研究不同蒸馏方法连接因子的影响,并提出交叉路径的连接因子。(整理中。。。)
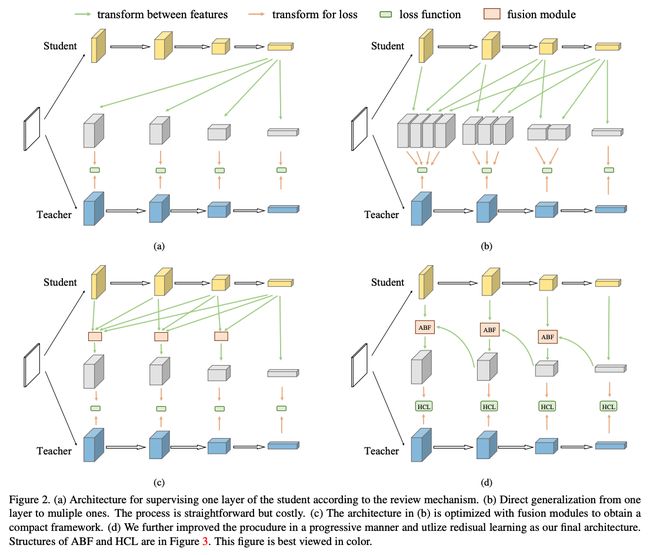
2. 模型剪枝
2.1模型剪枝简介
模型剪枝,或称权值剪枝,是增加模型权值稀疏性(张量中零值元素的数量)的方法。稀疏性是一种度量张量中有多少元素相对于张量大小是精确的零的方法。如果张量的“大多数”元素为零,则张量被认为是稀疏的,可通过l0-范数来测量张量中有多少个零元素:
![]()
模型剪枝一般包括三个步骤:
- 确定模型中那些参数是重要的;
- 应用二元准则将模型权重矩阵中相对“不重要”的权值剔除,即将其值置零;
- 重新训练稀疏网络,对模型进行微调。修剪和重新训练可重复执行,以进一步降低模型复杂性。
为什么需要模型剪枝?
- 更小。神经网络模型的稀疏表示可以通过利用非零张量元索引来压缩。压缩格式是面向特定于硬件和软件的,并且最佳格式可能因张量而异。计算硬件需要支持压缩格式,表示压缩才有意义。压缩表示决策可能与算法交互,例如使用分片进行内存访问。稠密计算使用稠密运算符,因此压缩后的数据最终需要解压缩为其完整、密集的大小,这时所能做的就是将压缩表示尽可能接近计算引擎。另一方面,稀疏计算对不需要解压的稀疏表示进行操作,在硬件中实现这一点并不简单,通常意味着矢量计算引擎的利用率较低。因此,还可以利用了特定的硬件特性,例如对于向量化计算引擎,可以移除整个零权重向量并跳过其计算。
- 更快。神经网络的许多层都是带宽受限的,这意味着执行延迟由可用带宽决定。实质上,硬件花费更多的时间将数据接近计算引擎,而不是实际执行计算。全连接层、RNNs和LSTMs是带宽控制操作的一些例子。减少这些层所需的带宽,将立即加快速度。一些剪枝算法从网络中剪枝整个内核、过滤器甚至层,而不会对最终精度产生不利影响。根据硬件实现,可以利用这些方法跳过计算,从而减少延迟和功耗。
- 更节能。由于与片上存储器(如SRAM或缓存)相比,访问片外存储器(如DDR)付出的能量要高出两个数量级,因此许多硬件设计采用多层缓存层次结构。在这些片上缓存中拟合网络的参数和激活可以在所需带宽、总推理延迟和离线方面产生很大的差异,从而降低功耗。当然,如果使用稀疏或压缩表示,那么将降低数据吞吐量,从而降低能耗。
2.2 模型剪枝方法分类
深度学习模型因其稀疏性或过拟合倾向,可以被裁剪为结构精简的网络模型。根据剪枝内容的粒度,可分为非结构性剪枝与结构性剪枝。
非结构剪枝通常是连接级、细粒度的剪枝方法,直接修剪单个元素,精度相对较高,但依赖于特定算法库或硬件平台的支持。
结构剪枝一般针对通道或网络层,是一种粗粒度的剪枝方法,精度相对较低,但剪枝策略更为有效,不需要特定算法库或硬件平台的支持,能够直接在成熟深度学习框架上运行。
模型剪枝涉及问题主要有:
- 剪枝的粒度变化——剪多深?
- 剪枝方法——怎么剪?
- 如何衡量权值的重要性?
- 如何选取去除权值的数量或比例?
- 什么时候剪?
- 在去除不重要的权值之后,如何保持网络性能?
- 重训练后又会产生新的不重要权值,如何解决?
为了解决这些问题,现有模型剪枝工作包括幅度剪枝(Magnitude Pruning)、结构化剪枝(Structured Pruning)、模型瘦身(Network Thinning)、敏感性分析与剪枝(Sensitivity Analysis and Pruning)、模型修剪(Network Trimming)、自动调度(Automated Scheduling)、层剪枝(Level Pruning)、混合剪枝(Hybrid Pruning)、激活统计(Activation Statistics)和网络诊断(Network Surgery)等。这里就敏感度分析和这些方法中常用的正则化方法做进一步介绍。
(1)敏感性分析
通过剪枝引入稀疏性的难点在于确定每一层的张量使用的阈值或稀疏程度。敏感性分析是一种试图帮助我们根据张量对剪枝的敏感性对其进行排序的方法。其思想是设置特定层的剪枝级别(百分比),然后剪枝一次,对测试数据集运行评估并记录准确度得分。该方法对所有参数化层都这样做,并且对每一层都检查几个稀疏级别。敏感性分析需将模型性能训练到最高精度,因为这里的目标是理解训练模型的性能相对于特定权重张量的修剪。可利用单个元素的l1范数进行元素修剪灵敏度分析;利用滤波器的平均l1范数进行滤波器修剪灵敏度分析。如下图所示,为了了解每一层的敏感性,这里独立地剪除每一层,并在验证集上评估得到的剪除网络的准确性。根据每个层对修剪的敏感度,经验地确定要修剪的过滤器的数量。对于深度网络,可观察到同一阶段的层(具有相同的特征映射大小)对修剪具有相似的敏感性。为了避免引入层元参数,可对同一阶段的所有层使用相同的修剪率。对于对修剪敏感的层,可修剪这些层的少数权值,或者完全跳过修剪。
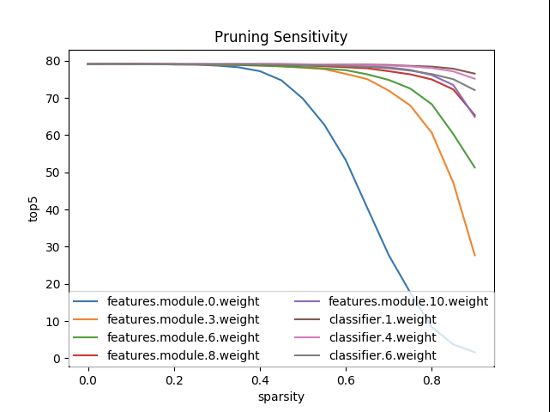
在Alexnet中,卷积层对剪枝更敏感,其灵敏度下降很深;而完全连接层不那么敏感,这很好,因为这类层包含了模型中的大部分参数。
(2)正则化
如何剪枝需要一个标准来选择所要剪枝的内容。最常见的修剪标准是每个元素的绝对值,即将元素的绝对值与某个阈值进行比较,如果低于阈值,则将元素设置为零。这种方法的思想是,l1-范数较小的权重对最终结果的贡献很小,因此它们不太重要,可以剔除。另外,可使用l2正则化来限制模型的容量;而结合l1和l2正则化可对模型进行结构性剪枝。一般来说,我们可以这样写:
![]()
其中W是网络中所有权重元素的集合, ![]() 为W的正则化因子,
为W的正则化因子, ![]() 是总训练损失,
是总训练损失, ![]() 是数据损失,称为正则化强度的标量,它平衡了数据误差和正则化误差。
是数据损失,称为正则化强度的标量,它平衡了数据误差和正则化误差。
正则化也可以用来诱导稀疏性。在模型剪枝中,一旦网络到达给定的稀疏约束的局部极小值,放宽约束使网络有更多的自由来逃离鞍点,并到达更高精度的局部最小值。为了诱导元素的稀疏性,可以使用l1范数,其定义如下:
![]()
l1范数正则化将一些参数元素设置为零,因此在简化模型的同时限制了模型的容量。这有时被称为特征选择,为我们提供了修剪的另一种解释。
此外,群正则化惩罚整组参数元素,而不是单个元素。因此,整个组要么是稀疏的(即所有组元素的值都为零),要么不是,其损失函数形式如下:
![]()
其中 ![]() 称为群Lasso正则化子,求元素结构(即群)的振幅之和。把g组中的所有权重元素表示为
称为群Lasso正则化子,求元素结构(即群)的振幅之和。把g组中的所有权重元素表示为 ![]() ,群正则化项可定义为:
,群正则化项可定义为:
![]()
群稀疏性表现出规律性(即其形状是规则的),有利于提高推理速度。
2.3 典型模型剪枝方法分析
(1) 1993-NIPS-Second Order Derivatives for Network Pruning: Optimal Brain Surgeon
该方法利用二阶泰勒展开选择参数进行剪枝,将剪枝看作正则项来改善训练和泛化能力。该方法是一种细粒度剪枝,优点是保留了模型精度,缺点是非结构化剪枝,对局部进行调整,依赖于专门的运行库和硬件设备。
(2) Exploring the Regularity of Sparse Structure in Convolutional Neural Networks
该论文探索完整的修剪粒度范围,并评估模型的正则化和精度之间的权衡;证明粗粒修剪能够达到与细粒修剪相似甚至更好的压缩率,即使它获得的稀疏性较小;展示粗粒度稀疏能够以结构化的方式跳过计算并减少内存引用,这导致更高效的硬件加速器实现。
(3) Driven Sparse Structure Selection for Deep Neural Networks
该文章引入Gate控制分支,数据驱动,动态剪枝,端到端,为CNN模型训练和剪枝提出了一个统一的框架。通过在某些CNN结构上引入缩放因子和相应的稀疏正则化,将其定义为联合稀疏正则化优化问题。其局限性在于只能应用于宽网络结构。
(4) Learning both weights and connections for efficient neural network
该文章设定了取舍权值的阈值,非结构化,属于细粒度剪枝。论文设定了绝对值正则项,优点是简单直接,缺点是基于小权值对网络贡献小,与网络输出没有直接关系的假设,可能会严重破坏网络。
(5) Automated Pruning for Deep Neural Network Compression
该文章解决了传统方法需要在多个待测试阈值上重复迭代和权重阈值在所有层共享导致难以寻找合适阈值的问题,采用权重与阈值联合优化,设定特定层阈值,省略多次迭代过程。
(6) Learning Efficient Convolutional Networks through Network Slimming
该方法是通道层次的剪枝方法,采用一种新的重要程度衡量方法,利用批归一化中的缩放因子γ 作为重要性因子,即γ越小,所对应的通道越不重要,就可以裁剪,于是在目标方程中增加一个关于γ的l1正则项。
(7) Pruning convolutional neural networks for resource efficient transfer learning
该方法是通道级别的剪枝,其剪枝准则为:选择一个通道集合中的子集,将子集计算对应的损失与原集合对应的损失差异作为衡量通道重要性的准则。该方法根据相关性剪枝进行迭代删除重要度最低的通道,并进行微调。
(8) Designing Energy-Efficient Convolutional Neural Networks Using Energy-Aware Pruning
该方法根据能量消耗进行剪枝,采用了一种能量估计方法,即通过实际的电池消耗(来自于计算与存储),建立数据稀疏与带宽减小与电池消耗的模型;通过节能意识指导剪枝,即从能量消耗最多的层开始剪枝,基于最小化输出误差来剪枝;对CNNs的能量消耗进行分析。
(9) Adaptive Neural Networks for Efficient Inference
该方法不改变网络结构,只针对单个样本的推断过程精简网络。采用了两种策略:一是提前终止来跳过某些层;二是网络选择。
(10) Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding
该论文针对以上问题都提出了相应的解决方案。在ImageNet数据集上,该方法对AlexNet的内存占用减少35倍(从240MB到6.9MB)同时不损失准确率,对于VGG-16减少49倍的内存占用(从552MB到11.3MB)同样不损失准确率。可以说是非常牛了。当然,图中也说明了该压缩是剪枝、量化和哈夫曼编码共同作用的结果。不过光剪枝也就达到了十倍的压缩率了,已经相当可观。
3. 模型量化
3.1 模型量化简介
模型量化是指减少模型中表示权值的比特数的过程。在讨论数值格式时,有两个主要属性:第一个是动态范围,指可表示数字的范围;第二个是在动态范围内可以表示多少个值,这决定了格式的精度/分辨率(两个数字之间的距离)。对于所有整数格式,动态范围是[-2n-1, 2n-1-1],其中n是位数,可表示值的数目是2n。所以8位整数(INT8)的范围是[-128, 127],4位整数(INT4)的范围是[-8, 7]。32位浮点数(FP32)的动态范围是±3.4×1038,大约有4.2×109值可以表示。
目前用于研究和部署的深度学习模型的主要数值格式是FP32或FP16,而对减少带宽和计算要求的渴望驱使人们研究使用较低精度的数值格式。实践证明,权重和激活可以使用INT8表示时不会导致严重的精度损失。使用更低的比特宽度,如4/2/1比特,是一个当前比较活跃的研究领域。量化带来的更明显好处是显著减少了带宽和存储。例如,与FP32相比,使用INT8进行权重和激活会减少4倍的总带宽。
模型量化时,需要考虑如何避免溢出。例如,卷积层和完全连接层涉及将中间结果存储在累加器中。由于整数格式的动态范围有限,如果我们对权重和激活使用相同的位宽度,对于累加器,我们可能会很快溢出。因此,累加器通常以更高的比特宽度实现。两个n位整数相乘的结果至多是一个2n位数。在卷积层中,这种乘法是ck2次累积,其中c是输入通道的数目,k是核宽度(假设为平方核)。因此,为避免溢出,累加器应为2n+M位宽,其中M至少为log2(ck2)。在许多情况下,使用32位累加器;对于INT4和更低版本,可能使用少于32位的累加器。
3.2 模型量化方法分类
当前,模型量化方法主要包括二值化网络、三值化网、INT4量化、INT8量化以及FP16量化等等。FP16量化比较简单,能够在损失少量精度的情况下大大提高模型推理速度,被集成到各种模型开发和优化工具库中。为了保持量化后模型的性能,常用的量化策略包括:替换激活函数、修改网络结构、迭代量化、混合权重和激活精度以及训练时量化等等。
具体地,这里重点介绍下INT8量化以及更为积极的量化方法。
(1)保守量化——INT8
在许多情况下,我们希望在不重新训练模型的前提下,只是通过压缩权重或量化权重和激活输出来缩减模型大小,从而加快预测速度。“训练后量化”就是这种使用简单,而且在有限的数据条件下就可以完成量化的技术。不同的量化方案包括“只对权重量化”和“对权重和激活输出都量化”。一个简单的量化方法是将权重的精度从浮点型减低为8位整型。由于只有权重进行量化,所以无需验证数据集就可以实现。一个简单的命令行工具就可以将权重从FP32转换为INT8。如果只是想为了方便传输和存储而减小模型大小,而不考虑在预测时浮点型计算的性能开销的话,这种量化方法是很有用的。在权重和激活输出都需要量化时,通常需要标定数据并计算激活输出的动态范围,实际应用中一般使用几十个到数百个小批量数据来估算激活输出的动态范围。
在INT8量化时,需要使用比例因子将张量的动态范围调整为整数格式的动态范围,这个比例因子可以按每一层每一个张量逐一计算。最简单的方法是将浮点张量的最小/最大值映射到整数格式的最小/最大值。对于权重和偏差来说,这很容易,因为一旦训练完成,它们就会被设定;对于激活层,最小/最大浮点值可以在推断过程中“在线”或“离线”获得。“离线”意味着在部署模型之前收集激活统计信息,无论是在训练期间还是重新训练的FP32模型,可通过收集统计数据来计算缩放因子,并在模型部署后固定。这种方法有在运行时遇到未在范围内观察值的风险,这些值将被截断,这可能会导致精度降低。“在线”意味着可以在运行时动态计算每个张量的最小/最大值。这种方法无法进行剪裁,且在运行时计算最小值/最大值所需要额外增加计算资源。另外,可通过优化比例因子范围来微调模型。最常见的方法是每层使用一个比例因子,但也可以计算每个通道的比例因子。另外,对INT8的训练后量化在有些情况下并不能很好地保持准确性,例如,MobileNet模型对训练后量化的效果不好,这可能是因为该模型结构比较紧凑[12],这时可通过训练时量化或量化后重新训练来提高精度。
(2)积极量化——二值
将FP32模型量化为INT4或更低通常会导致严重的精度降低,因而需要进行重新训练来获得合理的准确性,并通过训练来确定量化方案,以此提高量化后模型的精度。
二值化神经网络,在浮点型神经网络的基础上将其权重和激活函数值进行二值化(+1,-1存储,只需1bit)得到的神经网络。这种量化方案可用于嵌入式或移动场景(例如手机端、可穿戴设备、自动驾驶汽车等),这些场景都没有GPU且计算能力和存储容量相对较弱且限制较大,具有研究的价值和意义。其优点在于:
- 训练效果上,有的时候二值网络的训练效果甚至会超越全精度网络,因为二值化过程给神经网络的权重和激活值带来了噪声,像dropout一样,反而是一种正则化,可以部分避免网络的过拟合。
- 存储空间上,通过将权重矩阵二值化,一个权重值只占用一个比特,相比于单精度浮点型权重矩阵,网络模型的内存消耗理论上能减少32倍,因此在模型压缩上具有很大的优势。
- 运算速度上,权重值和激活函数值进行二值化之后,原来32位浮点型数的乘加运算,可以通过一次异或运算和一次位统计运算解决,在模型加速上具有很大的潜力。
3.3 典型模型量化方法分析
(1) XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks
该文介绍一种简单、高效、准确的网络来近似卷积神经网络。该方法旨在使用二元运算找到卷积的最佳近似值。本文提出了两个量化方法:具有二元权重的网络BWN和XNOR。 在二元权重网络中,所有权重值都用二值近似。与全精度权重的网络相比,二元权重网络约压缩了32倍。另外,当权重值和输入都用二值近似时,卷积可以仅通过加法和减法来计算,从而加快运算速度(大约提高2倍)。 更进一步, XNOR网络对卷积层和全连接层的权重以及网络的输入都进行二值化。 二值化的权重和二值化的输入可以有效地实现卷积运算。如果卷积运算的所有操作数都是二值(1和-1)的,那么可以通过XNOR(异或非门)和位计数操作来估计卷积。XNOR-Net可以精确地近似CNN,同时在CPU中提高58倍计算速度。这意味着,XNOR-Nets可以在内存小和无GPU的设备中实现实时前向计算。XNOR-Net通过同时对权重W和输入I做二值化操作,达到既减少模型存储空间,又加速模型的目的,当然准确率影响也比较明显。
(2) Performance Guaranteed Network Acceleration via High-Order Residual Quantization
该文是对 XNOR-Net的改进,将网络层的输入进行高阶二值量化,从而实现高精度的二值网络计算。XNOR-Networks 也是对每个CNN网络层的权值和输入进行二值化,于是整个CNN计算都是二值化的,这样计算速度快,占内存小。XNOR的输入可看作一阶二值化,将其替换为高阶二值化,可由下式表示:

(3) Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference
该文主要侧重将推断中的浮点数运算量化为整数运算(Integer-Arithmetic-Only),最终将权重和激活函数量化为8-bit,只有一小部分参数(bias)为32-bit整数。另外,该文提出一种新的量化框架,在训练过程中引入伪量化的操作,用于模拟量化过程带来的误差,这一框架在mobilenet等本身比较精简的网络上效果不错。论文主要创新点:
- 该方法与传统的一致非对称量化不同,这里是将最小值对应的量化值(zero-point)也做了量化。这样做的原因是为了推断时候做整数乘法累加运算(但偏差会稍微大一些,损失一点精度)。这里,同一层采用相同的量化参数。
- 该方法将浮点数矩阵乘法替换成整数运算和移位运算的合成。
- 提出在前向计算的时候进行模拟量化的方法,而保持后向传播不变,仍按照浮点型存储数据。在前向计算时,在推断时需要量化的地方,插入伪量化操作。这里需要注意的是,权重是在与输入进行卷积前进行量化,如果有BN层,需要将BN层的参数在量化前合并到权重中。这种量化方案能够克服通道间权值差距过大和外点的干扰。