移动端网络的前世今生-MobileNetV1 翻译
MobileNetV1是2017年由谷歌公司提出的,用于移动视觉应用的高效卷积神经网络。
摘要
我们为移动和嵌入式视觉应用软件提出了一类有效的模型,称之为MobileNets。MobileNets基于流线型的架构,利用了深度可分离卷积来构建一个轻量级的深度神经网络。我们引入了2个简单的全局超参数用来权衡速度和准确率。这些超参数允许模型生成器根据实际问题的约束为应用选择适当大小的模型。我们在ImageNet分类数据集上进行了大量性能和准确率权衡的实验,来展现模型相比较其他主流模型的强大之处。我们还展示了MobileNets在更广泛的领域上的应用,包括目标检测,精细分类,人脸属性和大规模地理定位。
1、介绍
自从AlexNet在2012年获得了ImageNet挑战冠军,深度卷积神经网络被普及,卷积神经网络已经在计算机视觉中变得无处不在。普遍的趋势是生成更深更复杂的网络来提高准确率。然而这些提升准确率的改进不一定会使得网络在规模和速度方面更加有效。在一些现实应用中比如机器人,自动驾驶,增强现实等识别任务中,需要在有限的计算平台上及时完成。
本文描述了一种有效的网络结构和一组2个超参数,用来建立一个非常小,低延时的模型,可以很容易的适配移动和嵌入式视觉应用。Section2中回顾了建立小模型的过程。Section3中介绍了MobileNets体系机构和2个超参数一个宽度超参数一个分辨率超参数,用来定义更小更有效的MobileNets。Section4中描述和了在ImageNet和一些不同应用上的实验。Section5做了一个总结描述。
2、前期工作(大概看看)
在最近的一些工作中,人们对构建小型高效的神经网络的兴趣提升了。一些不同的方法通常被分为压缩预训练网络和训练一个小网络。本文提出了一类网络体系结构,允许模型开发者根据他们的应用的资源(延迟,大小)匹配一个小的网络。MobileNets主要关注于优化延迟,但也产生了小型网络。一些论文中只关注模型大小,忽略了模型性能。
MobileNets首先在[26]上使用了深度可分离卷积,随后在Inception模型【13】中减少了一开始几层的计算。展开网络[16]用完全因子化的卷积建立了一个网络,并显示了极端因子化网络的潜力。独立于本文,分解网络[34]引入了类似的分解卷积以及拓扑连接的使用。随后,Exception网络[3]演示了如何扩展深度可分离过滤器,以超越Initiation V3网络。另一个小型网络是Squeezenet[12],它使用瓶颈方法来设计一个非常小的网络。其他简化计算网络包括结构化转换网络[28]和深度转换网络[37]。
另一种获得小网络的方法是收缩、分解或压缩预训练网络。文献中提出了基于乘积量化[36]、哈希[2]和剪枝的压缩、矢量量化和哈夫曼编码[5]。此外,还提出了各种因子分解来加速预训练网络[14,20]。另一种训练小网络的方法是蒸馏法[9],它使用较大的网络来教导较小的网络。它是对我们方法的补充,并在第4节的一些用例中介绍。另一种新兴的方法是低比特网络[4,22,11]。
3、MobileNet体系结构
在本节中,我们首先描述MobileNet构建的核心层,这些核心层是深度可分离的过滤器。然后,我们描述了MobileNet网络的结构,最后给出了两个模型收缩超参数宽度乘数和分辨率乘数的描述。
3.1、深度可分离卷积
MobileNet基于深度可分离卷积,这是一种分解卷积的方式,将标准卷积分解为一个深度卷积和一个被称为点卷积的1x1卷积。对于MobileNets,深度卷积对输入的每个通道使用一个单独的滤波器(卷积核)。点卷积使用一个1x1卷积对深度卷积的输出进行合并。标准卷积是在一步之中完成对输入进行卷积得到新的输出,但是深度可分离卷积分成了两层,一层用来做卷积过滤,一层用来合并输出。这种分解方法能有效减小计算量和模型大小。图2展示一个标准的卷积(a),被分解为一个深度卷积(b)和一个1x1的点卷积(c)。一个标准的卷积层的输入大小D_F x D_F x M的特征F,和输出一个大小为D_F x D_F x N的特征G。 其中D_F表示输入的正方形特征图的宽度和高度(因为原始输入图片都是正方形的,卷积池化也是方形,所以过程中的特征都是正方形)。其中M是输入特征的通道数,也是卷积核的深度,N是输出出特征的通道数,也是卷积核的个数,D_F是输入输出(考虑padding)特征图的宽和高。对于标准卷积而言,考虑步长为1,padding到同样大小时的计算量为 D_F x D_F x M x N x D_K x D_K,其中D_K代表了卷积核的大小。MobileNets解决了这些问题。首先使用深度可分离卷积解决了输出通道数和卷积核大小的关系。(标准卷积中输出通道数 = 卷积核的通道数。这里卷积核通道数永远=1。)
标准卷积运算的作用是基于卷积核对特征进行滤波,并对特征进行组合以产生新的表征。通过使用被称为深度可分离卷积的因式分解进行卷积,可以将滤波和组合步骤分为两个步骤,从而大大降低计算成本。
深度可分离卷积由两层组成:深度卷积和点卷积。深度卷积对每个通道(深度上)用一个单独的滤波器(卷积)。点卷积,一个1x1卷积,对深度卷积层的输出进行一个线性组合。MobileNets同样对每一层使用了batchnorm和RELU的非线性激活。深度卷积在对每一个通道进行单一的滤波操作的计算量为D_K x D_K x M x 1 x D_F x D_F,其中D_M为卷积核大小,M卷积个深度,也是输入特征的通道数,1表示卷积核个数,因为对单个通道进行卷积,因此卷积核个数1。此时的输出特征大小为:D_F x D_F x M。再进行点卷积的计算量为 1 x 1 x M x D_F x D_F x N。总的计算量为D_K x D_K x M x 1 x D_F x D_F+1 x 1 x M x D_F x D_F x N,与标准卷积对比,计算量占比:
深度可分离卷积计算量/标准卷积计算量 = 1/N + 1/D_K^2,一般标准卷积计算过程中N的数值都很大:256,512。而D_K的值一般3,5。显然计算量基本上=1/D_K^2。MobileNets中的卷积核大小D_K=3,即计算量降低到了原来的1/9,但是精度下降却很小。
3.2网络结构和训练
MobileNet除了第一层是全卷积,其余层都是使用了深度可分离卷积。MobileNets的结构定义在表1。每一层的后面都有一个batchnorm和RELU非线性层。全链接层除外,该层没有非线性层,后接一个softmax用于分类。图3对比了正常卷积+BN+RELU和深度可分离卷积+BN+RELU的过程。下采样过程由加了strided的卷积的深度卷积完成(就是卷积过程没有了padding)。在最后全连接层前使用了一个全局平局池化,将分辨率降低到了1。将深度卷积和点卷积分别作为一层,MobileNet一共有28层包括一个全连接层,13个深度卷积层,14个点卷积层。
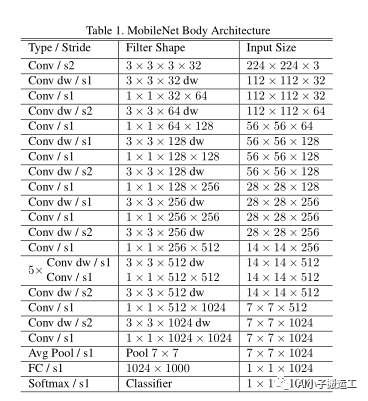
图片来源于原论文。
其中s2的作用是用来进行下采样,s1没有进行下采样。
单纯的依靠少量乘-加的运算来设计的网络是远远不够的。保证这些操作被有效的执行也是很重要的。比如非结构化的稀疏矩阵的操作并不一定比稠密矩阵操作的速度快,除非矩阵的稀疏程度非常高。我们的计算量几乎都在稠密的1x1卷积中,这样可以使用高度优化的GEMM算法来进行矩阵计算,通常卷积使用GMEE算法进行计算时需要在内存中进行重新排序,即所谓的im2col,这个方法被广泛使用在caffe包中。1×1卷积不需要在内存中重新排序它可以直接用GEMM算法来实现,GEMM算法是数值线性代数中最优化的算法之一。MobileNet中95%的计算和75%的参数都在1x1卷积中,剩余的参数几乎都在最后的全连接层。
MobileNet模型在Tensorflow上进行训练,采用的异步梯度下降法跟InceptionV3类似。跟训练大模型不同的是,我们采用更少的正则和数据增强方法,因为小模型更难出现过拟合现象。训练MobileNet时我们也不需要使用标签平滑,控制最小图片大小等在训练Inception模型时使用的技巧。
3.3宽度超参数:更小的模型
尽管标准的MobileNet已经很小,使用资源也少,但很多特殊场景需要更小更快的模型。为了构造这些更小,计算量更少的模型,我们构造了一个简单的参数alpha,叫做宽度乘积参数。参数alpha的作用可以对网络的每一层进行瘦身。
对一个给定的层和宽度系数alpha,使得输入的通道数M变成alpha * M,输出的通道数N变成 alpha * N。从而计算量变成 D_K*D_K*alpha*M*D_F*D_F+alpha*N*alpha*M*D_F*D_F,其中alphs取值范围是0~1,可取1不可取0。alpha的一般取值为0.25,0.5,0.75,1.0,alpha=1时,就是正常的MobileNet,alpha<1时就是减弱的MobileNets。通过宽度超参数的设计,计算量大概减小到了alpha的平法倍。
3.4分辨率超参数:降低无关表示
第二个用来减小网络计算消耗的超参数是分辨率超参数rou。超参数rou被用在了输入图片中,并且内部每一层都被同样的rou进行了分辨率降低。在使用时,我们通过设置输入图片的分辨率来达到设置rou的目的,标注输入224,使用192的输入,则rou = 192/224。
使用了宽度超参数alpha和分辨率超参数rou后,使用了深度可分离卷积的核心网络层的计算消耗可以用下面的表达式:
D_K *D_K *alpha*M *rou*D_F *rou*D_F +alpha*M *alpha*N *rou*D_F *rou*D_F
rou取值范围0~1,取1不取0,rou的值是通过设置输入图片的分辨率达到设置rou的目的。输入分辨率可选224,192,160,128。
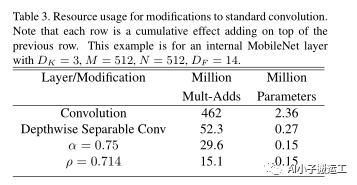
表格3中给出了具体的例子,图片来自论文
4、实验
总结,MobileNet在各种场景都取得了不错的效果。
5、官方代码
https://github.com/tensorflow/models/tree/master/research/slim/nets/mobilenet
欢迎关注微信公众号
