[Transformer]CoAtNet:Marrying Convolution and Attention for All Data Sizes
CoAtNet:卷积+注意力用于任意规模的分类任务
- Abstract
- Section I Introduction
- Section II Model
-
- Part 1 Merging Convolution and Self-Attention
- Part 2 Vertical Layput Design
- Section III Related Work
- Section IV Experiments
-
- Part 1 Main Results
- Part 2 Ablation Studies
- Section V Conclusion
- Appendix
-
- Part 1 Model Details
from Google Research Brain Team
Paper
Abstract
Transformer在CV领域越来越引起人们的研究兴趣,但是某些任务Transformer的性能仍然逊于CNN模型。本文表示,虽然Transformer模型容量更大,但是由于缺乏适当的归纳偏执信息,因此Transformer的泛化性比CNN更差。
为了有效的结合两种架构的优势,本文提出CoAtNet这种混合框架,有以下优点:
(1)深度卷积和自注意力可以轻松的结合在一起
;
(2)通过垂直的堆叠注意力层和卷积层可以显著提升泛化性和模型性能
实验结果表明,本文的CoAtNet在不同数据集以及不同资源约束下达到了SOTA:在不借助额外数据的帮助下在ImageNet达到了86%的top-1准确率;如果借助ImageNet-21K上预训练的帮助江都会提升到88.56%;如果借助更大的JFT-300M预训练精度会提升到90.88%.
Section I Introduction
自从AlexNet取得突破,卷积神经网络一直是计算机视觉的主要模型;而看到Transformer在NLP领域取得的成就,也有越来越多的研究将其应用于CV领域。最近的研究表明即使只是用一层原始的Transformer也可以在ImageNet上达到较为合理的性能;如果在大规模数据集JFT-30M上岗预训练后更是可以达到与当前最先进ConvNet相近的结果,这表明Transformer可能比ConvNet拥有更大的容量。
虽然ViT表现出优异的性能但是在数据有限的情况下仍然落后于卷积网络,有的工作尝试借助特殊的正则化、数据增强来做弥补但是在相同的数据量和计算量下这些ViT变体并不能优于SOTA的卷积模型,主要是因为原始的Transformer缺乏convnets所具有的归纳偏执,因此需要大量的数据和计算资源来进行弥补。
因此近期许多工作尝试将卷积的局部性加入到Transformer模块中,或是通过施加局部感受野或者通过增强注意力或者通过在FFN层中使用隐式或显式的卷积操作。但是这些工作要么集中于某一个方面,缺乏对卷积和注意力的整体理解。
本文则从机器学习的泛化性和模型容量两方面系统的研究了如何将卷积与注意力混合。研究结果表明,卷积层具有较强的归纳偏置能力,收敛更快;注意力层具有更大的模型容量,可以从大量数据中获益。将二者结合,一方面借助归纳偏执可以收敛的更快,借助注意力可以拥有更好的模型容量和泛化性。问题的关键是如何将二者进行有效的结合,从而更好地权衡性能和效率。
本文提出两个观点:
首先常用的深度卷积可以有效的与注意力进行结合
;其次以恰当的方式堆叠卷积层和注意力层可以获得优异的性能提升以及泛化能力。
基于以上观点,本文提出一种简单但有效的混合网络架构-CoAtNet。(谐音:coat外套)
本文提出的CoAtNet在不同数据集 大小以及不同资源约束下均达到了SOTA,尤其在数据有限的情况下由于具有良好的归纳偏执同时又具有优异的泛化性能也表现出很高的精度;在大型数据集上CoAtNet不仅具有Transformer的扩展性同时收敛速度更快,从而提高了效率。
在仅使用ImageNet1K进行新联达到了86%de top-1准确率,当在ImageNet-21K预训练后准确率提升到88.56%,与在JFT-300M上与训练的ViT性能相近,二者数据集差23倍;在JFT-3B预训练后CoAtNet则表现出更加优异的性能,精度提升到90.88%,计算量则比Vit-G减少了1.5倍。
Section II Model
本节会重点探究卷积核Transformer的最优组合方式。将该问题分解成两部分来解决:
(1)如何在一个基本计算模块中将卷积与自注意力结合?
(2)如何将不同类型的计算模块堆叠在一起从而形成一个完整的网络?
本文将逐个解决。
Part 1 Merging Convolution and Self-Attention
卷积本文主要关注MBConv模块,主要借助深度卷积来捕获空间交互信息。选择MBConv的主要原因就是Transformer中的FFN和MBConv均采用了“inverted bottleneck”的设计,即首先将通道数扩展到原始的4倍然后再通过扩宽网络将通道数缩回去。
此外本文还注意到深度卷积核自注意力都可以表示为一个在预定义的感受野中所有值的加权和操作。比如卷积是在一个预定义好的感受野中提取特征:

其中L表示局部感受野
而自注意力则可以理解为感受野是整张图,依旧计算的是所有值的加权和,再通过归一化得到最终输出。
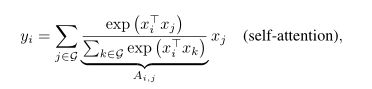
其中G表示全局感受野。
下边来分析二者的特性,这样才能将二者的长处结合在一起。
(1)深度卷积的卷积核与输入无关,而注意力权重A则依赖于输入,因此也不难理解SA可以捕获两个空间位置之间更复杂的关系,而这是我们在处理高级概念时所需要的的;但是也确实有过拟合的风险,尤其是在数据量有限的前提下。
(2)对于任意一对位置(i,j)卷积只关注二者之间的相对位移(i-j)而不是i,j本身的值。
这种特性通常被称作-平移不变性,这一特性有助于提升模型的泛化性能。在ViT中由于使用的是绝对位置嵌入不具备这种可行,这也能解释为什么ViT在小型数据集上的效果没有卷积好。
(3)感受野的大小是卷积核SA最终要的一大区别。
通常来说,感受野越大能提供的上下文越丰富,因此模型的容量也更大,SA具有的全局感受野也是诸多任务采用Transformer的原因;但是代价就是计算成本爆炸,是输入分辨率的平方项。
Table 1展示了卷积核SA的特性对比,因此理想的模型应该具有上述三种特征,二者的公式也比较类似,一个简单的将二者结合的方法就是在softmax归一化之前或者之后将全局的静态卷积核与attention注意力矩阵进行一个相加。
![[Transformer]CoAtNet:Marrying Convolution and Attention for All Data Sizes_第1张图片](http://img.e-com-net.com/image/info8/1a9512a6cea0458a938ef3d7b6d13a4c.jpg)
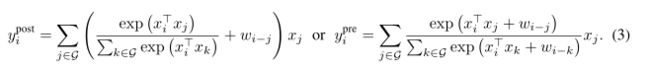
虽然这一想法十分简单,但是ypre似乎对应着相对注意力的一种特定版本,即注意力矩阵A取决于相对位移和输入,因此本文将Ypre作为CoAtNet的关键组成部分。
Part 2 Vertical Layput Design
在确定如何将卷积和注意力有效结合后,接下来考虑如何通过堆叠搭建一个完整的网络。
因为前文提到过SA的复杂度是输入分辨率的平方项,因此如果直接使用原始图像作为输入计算复杂度太高了,因此本文考虑一下三种方法:
(1)通过一些下采样操作降低输入分辨率,在feature map到达一定程度后计算全局相对注意力;
(2)增强局部注意力 即将全局感受野G限制在局部范围,就像卷积的局部感受野一样;
(3)将SA的计算替换为线性复杂度的操作。
本文简单尝试了(3)但效果并不好;(2)则涉及到许多变形操作需要频繁的访存。这种对硬件不友好,无法发挥TPU加速的效果,还损害了模型的容量。因此本文将重点放在(1)上。
那么下采样操作可以通过:(1)像ViT一样借助步长卷积或者(2)像卷积一样的多尺度网络逐渐下采样.
当使用ViT时直接堆叠L个Transformer block,称之为ViTrel;
当参考卷积搭建多尺度网络时搭建了5层网络逐渐降低分辨率,分别是S0,S1,S2,S3S4,,每个stage空间分辨率都会减半,同时通道数加倍。
S0是一个单纯的2层卷积模块,
S1使用了SE操作的MBConv
MBConv:采用深度可分离卷积 主要为了降低参数量;采用到瓶颈设计会先升维再降维。
S2-S4则是各种变体的组合,分别是:,C-C-C-C、C-C-C-T、C-C-T-T和C-T-T-T,其中C和T分别表示卷积和Transformer
实验则主要对比两方面:泛化性和模型容量。
泛化性:本文感兴趣的是训练损失以及验证精度。如果两个模型的训练损失一样,那么验证损失越低证明泛化性越好。泛化性对训练数据有限的情景至关重要。
**模型容量:**模型容量则表征了在大型数据集上的学习能力,模型容量越大越不容易过拟合,也容易获得更好的性能。
![[Transformer]CoAtNet:Marrying Convolution and Attention for All Data Sizes_第2张图片](http://img.e-com-net.com/image/info8/0211bd57635a435bb76a09c330da781d.jpg)
为了对比这5种模型的容量,分别在ImageNet-1K和JFT上训练300和3个rpoch,但没有使用任何数据增强或正则化操作。
Fig 1展示了训练损失和验证损失,在泛化性方面对比结果是:
![]()
可以看到ViT的泛化性远远弱于其他模型,本文推测这与下采样过程中缺少恰当的低层次信息有关;总体趋势是模型中的卷积越多泛化性能越好。 在模型容量方面,可以看到最终排名如下:
![]()
这表明,Transformer越多并不一定代表处理视觉任务的能力越强。虽然最终结果显示Transformer模型最终超过两种MBConv的变体,显示了Transformer的建模能力,但也有两种MBConv性能优于Transformer,这说明基于步长的ViT模型丢失了太多信息,限制了模型的建模能力。
更有趣的是这两种模型性能接近说明在处理低层次信息方面卷积这种局部操作与SA一样强大,同时卷积还可以大大减少内存和计算成本。
最终本文在C-C-T-T和C-T-T-T之间进行了一个迁移性测试,即在两个JFT数据集上预训练后的模型迁移到ImageNet-1K上对比迁移性能。
![[Transformer]CoAtNet:Marrying Convolution and Attention for All Data Sizes_第3张图片](http://img.e-com-net.com/image/info8/9c0e51913a194208a8adfcca6e55bee6.jpg)
Table 2是对比结果可以看到C-C-T-T这种结构有更好的迁移性能。 综合考虑到模型效率、模型容量、可迁移性,本文最终为CoAtNet选用C-C-T-T结构。
Section III Related Work
Convolutional network building blocks
卷积神经网络已经是许多计算机视觉任务的主流框架,如ResNet;另一方面像深度卷积因为其计算成本低参数少也在轻量级网络、移动端备受青睐。近期MBConv中提出的改进版倒置残差模块可以更好的权衡精度和效率,而前面也讨论过MBConv与卷积存在强烈的联系,因此绝大多数文章选用MBConv作为基础的卷积模块。
Self-Attention and Transformer
SA是Transformer的核心部件,Transformer目前已被广分用于语言建模和理解任务中。之前有工作表明只是用SA也可以获得一定的效果。ViT是第一个将Transformer用于图像分类也获得了较好的性能,但是ViT仍然稍逊于OCnvNet,需要在大规模数据集上预训练。因此许多工作都集中在如何提升Transformer的效率上。
Relative Attention
相对注意力有多种变体,通常可以分为两类:
一类是额外的相对注意力分组是输入的函数;一类是与输入无关的相对注意力。
CoAtNet属于第二类-输入依赖版本,但是本文并不会共享跨层的相对注意力参数,也不使用bucket,这样的好处是计算成本比较低。除此之外可以缓存结果以便进行推理。最近的一项工作也使用了这种输入独立的参数化方案,但是将感受野限制在局部窗口内。
Combining convolution and self-attention
将卷积与SA结合这种idea并不新鲜,通常是选择ConvNet作为backbone然后使用显示的自注意力或非局部模块来增强backbone,或者将部分卷积层替换为SA或其他更灵活的线性注意和卷积混合操作;但这通常会增加额外的计算成本。
虽然SA可以体高精度但是通常被认为是卷积网络的一个附加组件类似SE模块。
另一个方向是基于Transformer网络,将卷积或一些卷积特性融合进去。
本文的工作虽然也基于这种思想,但是本文是自然结合了深度卷积核基于内容的注意力,以及额外的附加成本也比较小。
更重要的是本文从泛化性和模型容量出发。展示不同stage倾向于哪些类型的层。比如与ResNet-ViT相比,当整体尺寸增加时CoAtNet也可以缩放卷积尺寸;另一方面与采用局部注意力的模型相比,本文的S3,S4可以保证模型的容量,因为S3,S4阶段占据了主要的算力和参数量。
Section IV Experiments
实验设定
CoAtNet family
Table3展示了本文设计的不同规模的CoAtNet网络,一般不同阶段通道数会加倍,分辨率会减半。
评价准则
为了测试模型性能,本文在三种不同规模数据集上进行了测试,分别是ImageNet-1K,ImageNet-21K,JFT-300M,数据集规模越来越大。
以及也测试了直接训练和预训练之后的结果。
数据增强和正则化
本文只考虑两种广泛使用的数据增强:随机增强和MixUp,以及三种正则化方案:stocastic depth,label smoothing,weight decay.
本文还观察到一个有趣的现象,如果在预训练时没有用这种增强,微调时使用这种增强反而会导致性能下降,本文认为这可能和数据分布的偏移有关。
因此本文在ImageNet和JFT预训练时使用比较小程度的随机深度,这样可以在微调时使用更多种正则化或数据增强,来提升下游任务的性能。
Part 1 Main Results
![[Transformer]CoAtNet:Marrying Convolution and Attention for All Data Sizes_第4张图片](http://img.e-com-net.com/image/info8/a969f988d3e8442eaf2a3d39c983f1b2.jpg)
ImageNet-1K
Table 4展示了在ImageNet-1K上的实验结果,可以看到CoAtNet不仅超过了ViT的性能也可以与CNN的性能相媲美,比如EfficientNet-V2和NFNets。Fig 2还展示了以224x224分辨率为输入的精度对比,可以看到随着注意力模块的增多CoAtNet的性能逐渐提升。
![[Transformer]CoAtNet:Marrying Convolution and Attention for All Data Sizes_第5张图片](http://img.e-com-net.com/image/info8/f6120f943d874b8b98fcd50a7df77e00.jpg)
ImageNet-21K
Table 4还展示了ImageNet-21K的实验结果,可以看到预训练后CoAtNet的效果有很大提升,可以超过所有参与对比的网络,最高达到了88.56%的top-1精度,而性能达到88.55%的ViT-h/14则是在JFT数据集上预训练的结果才能达到,并且模型也是CoAtNet的2.3倍。这充分说明了CoAtNet在数据效率和计算效率方面有明显提升。
![[Transformer]CoAtNet:Marrying Convolution and Attention for All Data Sizes_第6张图片](http://img.e-com-net.com/image/info8/75724ba65d324cc2bdfc0970295cd4a4.jpg)
JFT
Table 5展示的是在JFT数据集上的训练结果,可以看到CoaTNet-4几乎可以与之前的NFTNet-F4的性能相媲美,但是在训练时间和参数方面提升了2x;如果达到和NFNet相近的参数量和计算资源,精度可以达到89.77%.
如果将CoAtNet达到ViT-G/14的规模,使用JFT-3B数据集训练,CoAtNet-6的精度可以达到90.45%,计算量减少1.5x;CoAtNet-7的top-1精度为90.88%是当前最高的精度。
Part 2 Ablation Studies
首先研究了将卷积与SA组合成一个计算单元使用相对注意力的重要性。主要对比两种模型,一个是使用了relative attention一个没哟使用。
从Table 6的实验结果可以看出相对注意力的效果比标准注意要更好,并且具有更好的泛化性。比如在ImageNet-21K实验找那个,二者的心更难接近但是相对主义表现出更好的迁移性能,说明相对注意在视觉任务中的优势不是更高的建模能力而是更好的泛化能力。
其次 因为S2(MBConv)和S3(relative Transformer)占据了主要的计算量,自然产生一个问题:
如何给二者分配计算资源从而获得最优的精度组合,实验中就归结为给每个stage分配多少block-本文称之为布局设计(layout).Table 7展示了不同布局的精度对比。
![[Transformer]CoAtNet:Marrying Convolution and Attention for All Data Sizes_第7张图片](http://img.e-com-net.com/image/info8/ff89e1cfb71443ad821f5a4667ad5fcc.jpg)
![[Transformer]CoAtNet:Marrying Convolution and Attention for All Data Sizes_第8张图片](http://img.e-com-net.com/image/info8/1b00791344e8449c8983ae1ce47557f4.jpg)
实验结果限制基本在S3中设置更多的Transformer block性能会更好,直到S2中因为block数目太少无法进行很好的泛化。
为了进一步评估折中组合是否有一定的迁移性,本文进一步比较了在1K和21K上同种设计的性能,但却发现性能下降了 因此说明了卷积再迁移性和泛化性方面起到的重要作用。
最后本文还探究了模型的细节设计,从Table 8中可以看出将head size从32增加到64会降低性能,虽然可以提升硬件加速效果;因此实践中需要考虑精度-速度的权衡问题;另一方面BN和LN性能相同,但是使用BN却对硬件更友好,TPU平均快10%-20%。
Section V Conclusion
本文系统研究了卷积核Transformer的特点,从而提出一种将二者混合的新方法-CoAtNet。大量的实验证明,CoAtNet与ConvNet一样具有良好的泛化性能,同时比Tranformer具有更大的模型容量,在不同规模数据集上均达到了SOTA。
值得注意的是本文专注于在ImageNet上分类模型的研发,但是本文相信CoAtNet适合更广泛的应用场景,比如目标检测和语义分割,本文会在未来继续研究。
Appendix
Part 1 Model Details
Fig 4展示了CoAtNet的详细结构
。
![[Transformer]CoAtNet:Marrying Convolution and Attention for All Data Sizes_第9张图片](http://img.e-com-net.com/image/info8/d1207752531b4e6fb5b6e27202e8f490.jpg)
2D Relative Attention
对于大小为[H,W]的图像,对于每一个注意力头都会创建一个[2H-1,2W-1]的可训练参数P,然后计算任意两个位置(i,j)和(i’,j’)之间的向硅位置。在TPU上训练时则分别沿着高度轴和宽度轴分别计算,整体计算复杂度为O(HW(H+W));GPU上哪些索引可以更高效的通过访问内存进行计算。
推理的时候会对H2W2范围内的元素进行缓存从而提高吞吐率;如果需要更大分辨率则使用双线性插值插值到所需尺寸即可。
Pre-Activation
为了提升模型的同质性本文始终使用pre-activation对MBConv和Transformer模块。本文还测试了在MBConv中也使用LN发现性能是一样的,但是LN在TPU上加速较慢,所以本文都使用GELU作为激活函数。
![]()
Down-Sampling
对于S1到S4每一个stage中第一个block,对于残差分支和identity分支均使用下采样操作;此外identity 分支还会进行通道映射映射到更大的hidden size。
因此SA模块的下采样操作可以表述为:

MBConv下采样可以表述为:
![]()
可以看到与标准MBConv是不一样的,原始的是通过步长卷积完成的;但是本文发现这种方法在模型较小的比较慢,参考Fig 9。
![[Transformer]CoAtNet:Marrying Convolution and Attention for All Data Sizes_第10张图片](http://img.e-com-net.com/image/info8/6d8eca566b204e8d9d164b0c91456e61.jpg)
因此为了更好的速度-精度权衡,本文采用了上式这种下采样操作。
Classification head
本文并没有像ViT中那样添加一个额外的 < cls > 来进行分类,而是对最后一个stage使用全局池化来简化过程。
![[Transformer]CoAtNet:Marrying Convolution and Attention for All Data Sizes_第11张图片](http://img.e-com-net.com/image/info8/9c03459d2e2843638d3c21e4f4f471b5.jpg)
![[Transformer]CoAtNet:Marrying Convolution and Attention for All Data Sizes_第12张图片](http://img.e-com-net.com/image/info8/ede7dac61f154683a6e5434b102e465a.jpg)
![[Transformer]CoAtNet:Marrying Convolution and Attention for All Data Sizes_第13张图片](http://img.e-com-net.com/image/info8/f5d74851bde44a3d99e29ad2e5298026.jpg)
![[Transformer]CoAtNet:Marrying Convolution and Attention for All Data Sizes_第14张图片](http://img.e-com-net.com/image/info8/83b717259d0a47b7abd46c59b17f52bf.jpg)
![[Transformer]CoAtNet:Marrying Convolution and Attention for All Data Sizes_第15张图片](http://img.e-com-net.com/image/info8/f3dc606b21b4494ea3b953e347a02e7d.jpg)