李宏毅2019年新增课程 week 15 transformer 课程笔记
李宏毅2019年新增课程 week 15 transformer 课程笔记
-
- RNN和CNN的局限
- Self-Attention
- Self-attention 平行化
- Multi-head self-attention 以2头为例
- self-attention 局限性
- 在一个seq2seq的model里如何使用self-attention
- Transformer
- transformer原始paper的attention visualization
- transformer的应用
- Attention机制的其他参考文章
视频及课件地址:https://www.bilibili.com/video/av65521101/?p=97
RNN和CNN的局限
RNN的输入是一串vector sequence,输出是另外一串vector sequence。如果是单向的RNN,输出是 b 4 b^4 b4 的时候,会把 a 1 a^1 a1 到 a 4 a^4 a4 通通都看过,输出 b 3 b^3 b3 的时候,会把 a 1 a^1 a1 到 a 3 a^3 a3 都看过。如果是双向RNN,输出每一个 b 1 b^1 b1 到 b 4 b^4 b4 的时候,已经把整个input sequence通通都看过。
RNN存在的问题是不容易被平行化,即假设在单向的情况下要算出 b 4 b^4 b4 ,需要先看 a 1 a^1 a1 再看 a 2 a^2 a2 再看 a 3 a^3 a3 再看 a 4 a^4 a4 才能算出 b 4 b^4 b4 。
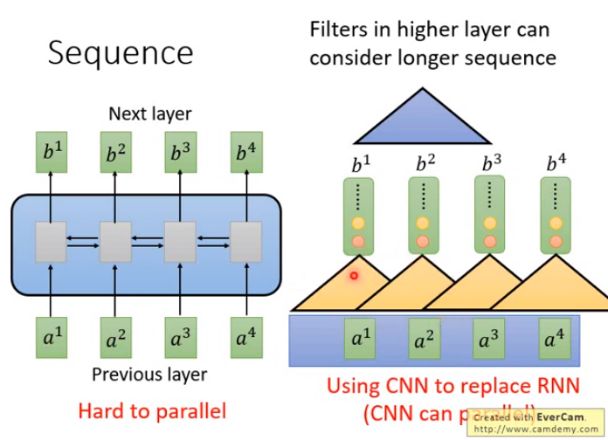
解决方法:用CNN代替RNN,如图,input是一个sequence a 1 a^1 a1 到 a 4 a^4 a4,每一个三角形都代表filter,输入是sequence中一小段,输出一个数值。若有一堆filter,输入是一个sequence,输出是另外的sequence。
CNN也有办法考虑更长的资讯,只要叠加很多层,上层的filter就可以考虑比较多的资讯。举例来说,叠了第一层CNN再叠第二层的CNN,第二层CNN的filter会把第一层的output当做input,如图蓝色的filter由 b 1 b^1 b1, b 2 b^2 b2, b 3 b^3 b3 决定输出,而 b 1 b^1 b1, b 2 b^2 b2, b 3 b^3 b3 是由 a 1 a^1 a1 到 a 4 a^4 a4来决定他们的输出,所以等同于蓝色的filter已经看了 a 1 a^1 a1 到 a 4 a^4 a4 的内容。CNN的好处是可以平行化,每一个同颜色的filter可以同时计算。
CNN缺点:每一个CNN只能考虑非常有限的内容,要叠很多层才能看到长期资讯。
Self-Attention
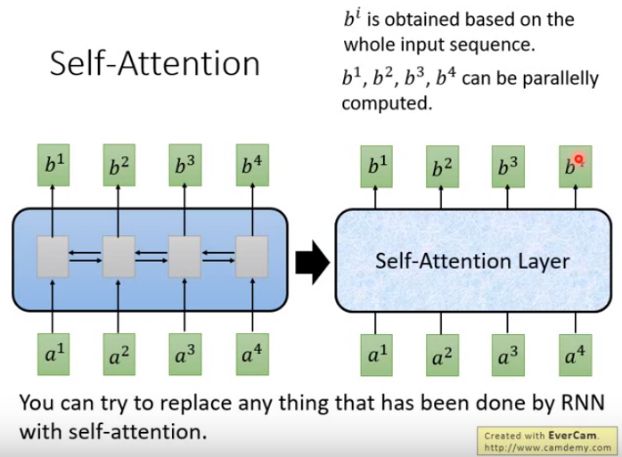
Self-Attention:输入和输出都是sequence,跟Bi-RNN有同样的能力,每个输出都看过input sequence,但特别的地方是 b 1 b^1 b1 到 b 4 b^4 b4 可以并行计算。
self-Attention这个概念最早出现在谷歌的论文 Attention is all you need,意思是不需要CNN也不需要RNN,唯一需要的就是attention。
self-Attention 如何用?
 如图:
如图:
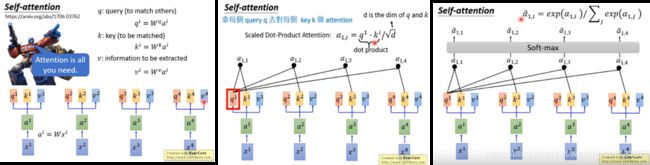
1. input sequence是 x 1 x^1 x1 到 x 4 x^4 x4,每一个input通过embedding乘上一个矩阵,变成 a 1 a^1 a1 到 a 4 a^4 a4 然后丢进self-attention layer。在每个self-attention layer里面,每个input分别乘上3个不同的transformation产生三个vector。
q q q 代表query去和其他人做匹配, k k k 代表key被匹配的, v v v 代表value被抽取出来的信息。
2. 拿每个 q q q 去对 k k k 做attention,attention有各式各样的算法,本质是吃两个向量输出一个数,一般做self-attention layer的时候都套用原始paper的做法,不会做太多变动。
例如:拿 q 1 q^1 q1 对 k 1 k^1 k1 到 k 4 k^4 k4 做attention得到 a 1 , 1 a_{1,1} a1,1 到 a 1 , 4 a_{1,4} a1,4 , 在self-attention layer里面attention算法用的是 scaled dot-product attention,如图公式。 d d d 是 q q q 和 k k k 的维度,直观解释公式中除以 d d d 的原因是, q q q 和 k k k 做dot product的数值会随着维度的增加而增大,用除以 d d d 用来平衡。
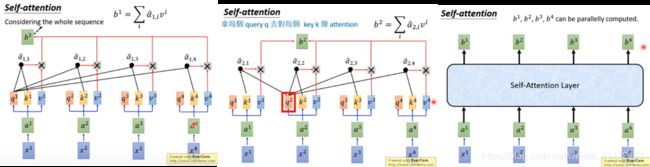
3. soft-max,把 a 1 , 1 a_{1,1} a1,1 到 a 1 , 4 a_{1,4} a1,4 通过softmax得到 a ^ 1 , 1 \hat{a}_{1,1} a^1,1 到 a ^ 1 , 4 \hat{a}_{1,4} a^1,4;公式如图。
4. 把 v 1 v^1 v1 到 v 4 v^4 v4 和 a ^ 1 , 1 \hat{a}_{1,1} a^1,1 到 a ^ 1 , 4 \hat{a}_{1,4} a^1,4 分别相乘再相加,得到sequence的第一个输出向量 b 1 b^1 b1 。
可以注意到,产生 b 1 b^1 b1 的时候用了 v 1 v^1 v1 到 v 4 v^4 v4 的weighted sum;而 v 1 v^1 v1 到 v 4 v^4 v4 由 a 1 , 1 a_{1,1} a1,1 到 a 1 , 4 a_{1,4} a1,4 做transformation得到,所以相当于产生 b 1 b^1 b1 的时候看了 a 1 , 1 a_{1,1} a1,1 到 a 1 , 4 a_{1,4} a1,4 。如果产生 b 1 b^1 b1 的时候不想考虑整个句子的资讯,只想考虑 local 的 information,可以让远的 a ^ 1 , 3 \hat{a}_{1,3} a^1,3 和 a ^ 1 , 4 \hat{a}_{1,4} a^1,4 的值变为0;如果考虑 global 的 information,让 a ^ 1 , 3 \hat{a}_{1,3} a^1,3 和 a ^ 1 , 4 \hat{a}_{1,4} a^1,4 有值就可以。
5. 重复以上步骤计算出 b 2 b^2 b2 , b 3 b^3 b3 , b 4 b^4 b4 ,self-attention layer做的事情和RNN是一样的,与RNN不同的是, b 1 b^1 b1 到 b 4 b^4 b4 可以平行的计算出来。
Self-attention 平行化


1. 把 a 1 a^1 a1 到 a 4 a^4 a4 拼起来变成一个矩阵,用 I 来表示,然后乘 w q w^q wq 得到 Q, Q 的每一列都代表一个query。同理,把 I 乘上 w k w^k wk 得到 K,K 的每一列代表一个key。把 I 乘上 w v w^v wv 得到 V,V 的每一列代表一个value。
2. 现在把 K 的列做转置叠加得到 K T K^T KT。拿 q 1 q^1 q1 对 k 1 k^1 k1 到 k 4 k^4 k4 做匹配,即dot product,得到一个向量 a 1 , 1 a_{1,1} a1,1 到 a 1 , 4 a_{1,4} a1,4 ,这个计算过程是可以平行的。接下来分别把 q 2 q^2 q2, q 3 q^3 q3, q 4 q^4 q4 拿出来跟 K T K^T KT 相乘得到向量。计算attention矩阵A的过程就是把矩阵 K T K^T KT 乘上 Q。如果有n个input,那得到的attention就是n*n的矩阵。然后对A的每一列做softmax得到 A ^ \hat{A} A^。
3. 做weighted sum。把 A ^ \hat{A} A^ 对 V 相乘得到self-attention的输出 O。
总结,self-attention的输入是一个矩阵 I,输出是一个矩阵 O。self-attention里面就是一连串的矩阵乘法,而矩阵乘法可以用GPU加速。
Multi-head self-attention 以2头为例

原理:每个 a i a^i ai 都会得到 q i q^i qi, k i k^i ki, v i v^i vi,在2头情况下,把 q i q^i qi 进一步进行分裂得到 q i , 1 q^{i,1} qi,1 和 q i , 2 q^{i,2} qi,2,把 k i k^i ki 和 v i v^i vi 也进行分裂。接下来做self-attention,只是 q i , 1 q^{i,1} qi,1 只会对 k i , 1 k^{i,1} ki,1, k j , 1 k^{j,1} kj,1跟它同样是第一个的vector做dot product得到attention,然后计算出 b i , 1 b^{i,1} bi,1, q i , 2 q^{i,2} qi,2只会对 k i , 2 k^{i,2} ki,2, k j , 2 k^{j,2} kj,2做attention得到 b i , 2 b^{i,2} bi,2,然后把 b i , 1 b^{i,1} bi,1 和 b i , 2 b^{i,2} bi,2 连接起来。可以对连接起来的向量乘上一个transform做降维得到最终的输出 b i b^i bi。
多头的好处是不同的head关注的点不一样。举例来说,有的head关注local的资讯,有的head关注比较长时间的资讯,比较global的资讯,有了multi-head之后,每个head会各司其职,做自己想做的事情。
self-attention 局限性
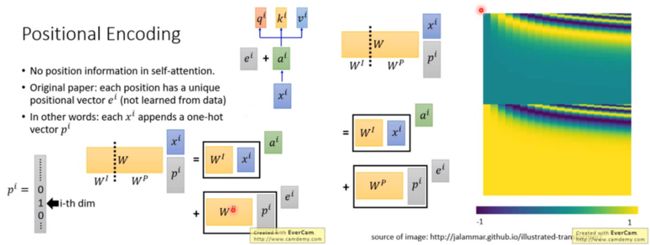 对Self-attention来说,因为它跟每一个input vector都做attention,所以没有考虑到input sequence的顺序。
对Self-attention来说,因为它跟每一个input vector都做attention,所以没有考虑到input sequence的顺序。
而我们希望考虑input sequence的顺序。所以在原始paper里面,每一个input x i x^i xi 通过transform变成 a i a^i ai 以后还要加上一个维度相同的向量 e i e^i ei , e i e^i ei 是手设的,代表位置的资讯。
换一种讲法就是,在input x i x^i xi 后连接一个one-hot vector p i p^i pi, p i p^i pi 代表位置资讯,第i维是1,其余都是0。连接之后乘上一个矩阵 W 做transform,W 可以拆成 W I W^I WI 和 W P W^P WP,把 W I W^I WI 跟 x i x^i xi 相乘得到 a i a^i ai, W P W^P WP 跟 p i p^i pi 相乘得到 e i e^i ei。 W P W^P WP 是可以learn的,论文里面 W P W^P WP 是人手设的,如图。
以上讲的是self-attention可以拿来取代RNN,接下来看self-attention在一个seq2seq的model里面是怎么被使用的。
在一个seq2seq的model里如何使用self-attention

一般的seq2seq model包含两个RNN,分别是encoder和decoder,输入 x 1 x^1 x1 到 x 4 x^4 x4,输出 o 1 o^1 o1 到 o 4 o^4 o4。Input sequence x 1 x^1 x1 到 x 4 x^4 x4 通过Bi-RNN变成 h 1 h^1 h1 到 h 4 h^4 h4,这个Bi-RNN可以用self-attention 取代掉。Decoder 的部分也是一个RNN,也可以用self-attention 取代掉。
总之,看到RNN用self-attention替换掉。
Transformer

以把中文翻译成英文为例,encoder的输入是中文的character sequence比如说是机器学习,在decoder 给他一个begin of sequence的token就输出一个machine,在下一个timestep把machine当作输入,就输出learning,直到输出句点的时候翻译过程结束。
接下来看每一个layer做的事情。
1. 先看左半部的encoder,input通过input embedding layer变成一个vector,然后vector加上positonal encoding,接下来进入灰色的block,这个block重复N次。
2. 在灰色的block里面,第一层是multi-head attention,也就是说input一个sequence,通过multi-head attention layer 得到另外一个sequence。
3. 下一个layer是add & norm,在这一步,把multi-head attention 的 output 跟 multi-head attention 的 input 相加,得到b‘,然后做layer normalization。参考文献见ppt。
Layer normalization和batch normalization 的异同:假设有一个大小为4的batch,在batch normalization 的时候,是对同一个batch里面不同data里面的同样的dimension做normalization,希望同一个dimension 的均值为0,方差为1。而layer normalization是不需要考虑bacth的,给一个data,希望各个不同dimension的均值为0,方差为1。一般情况下layer normalization会搭配RNN一起使用。那transformer很像RNN,所以这里使用layer normalization。
4. 接下来feed forward layer 会把input sequence 的每一个vector进行处理,还有另外一个add & norm 的layer。
5. 接下来是右半部decoder的部分,这个decoder的input 是前一个time step 产生的output,通过output embedding 加上positional information,进入灰色的block,这个block重复N次。
6. 这个灰色block的第一层叫masked multi-head attention。加masked的意思是说,现在做self-attention的时候,decoder会attend 到已经产生出来的 sequence,因为还没有产生出来的无法做attention。
7. add & norm layer
8. 接下来是multi-head attention layer,这个是attend 到之前encoder的输出。
9. 接下来还有add & norm layer, feed forward layer,add & norm layer
10. 最后做linear,softmax得到最终的output
transformer原始paper的attention visualization

在上面左图中,attention的weight越大,线条越粗,attention的weight越小,线条越细,图上两两word之间都会有attention。
在上面右图中,最后一个词是tired的时候,it是attend到animal的,如果把tired换成wide,it此时attend到street。
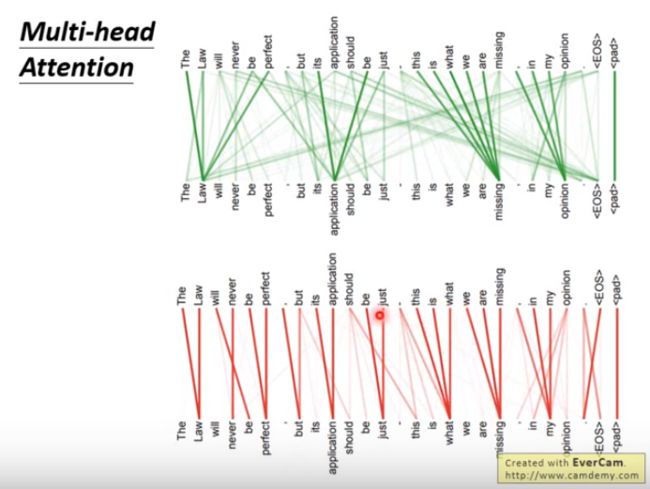
在multi-head attention里面每一组 q , k , v q,k,v q,k,v都做不同的事情,比如说用一组 q k q^k qk 做出来是绿色那部分,每一个word 都attend到很长时间点之后的word ;另一组 q k q^k qk 做出来是红色,显然找的是local information,每一个word都要attend到它之后的下一个word。
transformer的应用

基本上原来可以做seq2seq的,都可以换成transformer。
1. 做summarization
训练一个summarizer,input是一堆文章,output是一篇具有维基百科风格的文章。如果没有transformer,没有self-attention,很难用RNN产生 1 0 3 10^3 103 长的sequence,而有了transformer以后就可以实现。
2. Universal transformer
简单的概念是说,本来transformer每一层都是不一样,现在在深度上做RNN,每一层都是一样的transformer,同一个transformer的block不断的被反复使用。
3. 影像self-attention GAN
让每一个pixel都attend到其他的pixel,可以考虑比较global的资讯
Attention机制的其他参考文章
完全图解RNN、RNN变体、Seq2Seq、Attention机制
Attention机制详解(一)——Seq2Seq中的Attention
Attention机制详解(二)——Self-Attention与Transformer