YOLO系列算法详解(一)
一、深度学习经典检测方法
1.检测任务中阶段的意义
 对于单阶段(one-stage)检测来说,输入一张图像,经过一个卷积神经网络,输出一个边界框,只需要得到框的(x1,y1)和(x2,y2)四个值即可,是一个简单的回归任务。
对于单阶段(one-stage)检测来说,输入一张图像,经过一个卷积神经网络,输出一个边界框,只需要得到框的(x1,y1)和(x2,y2)四个值即可,是一个简单的回归任务。
两阶段(two-stage)检测中,也是输入一张图像,输出是检测到的物体的边界框,但是在检测过程中,多加了一个RPN(区域建议网络),最终的结果是由一些候选框(预选框)得到的,这样得到的效果会比单阶段检测好。
2.不同阶段算法优缺点分析
one-stage:最核心的优势:速度非常快,适合做实时检测任务!
但是缺点也是有的,效果通常情况下不会太好!
通常来说,在目标检测算法中,速度越快,效果越差;效果越好,速度越慢。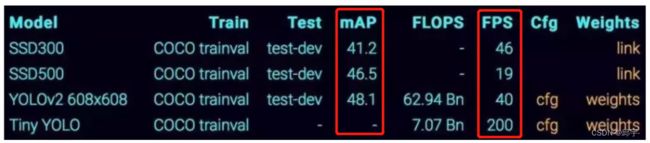
mAP,即均值平均精度(mean Average Precision)
mAP值越大,效果越好
FPS,即每秒帧率 (Frame Per Second)
除了检测准确度,目标检测算法的另一个重要评估指标是速度,只有速度快,才能够实现实时检测。FPS用来评估目标检测的速度。即每秒内可以处理的图片数量。当然要对比FPS,你需要在同一硬件上进行。另外也可以使用处理一张图片所需时间来评估检测速度,时间越短,速度越快。
two-stage:速度通常较慢(5FPS),但是效果通常还是不错的!
非常使用的通用框架Mask-Rcnn,需要熟悉

3.指标分析
(1)TP、TN、FP、FN
在介绍各项评估指标之前,首先介绍一下TP、TN、FP、FN这四个概念。
T(True)或者F(False)代表的是该样本的分类是否正确,P(Positive,正样本)或者N(Negative,负样本)代表的是该样本被分为正样本还是负样本。
TP(True Positives):意思我们倒着来翻译就是“被分为正样本,并且分对了”,
TN(True Negatives):意思是“被分为负样本,而且分对了”,
FP(False Positives):意思是“被分为正样本,但是分错了,其实是负样本”,
FN(False Negatives):意思是“被分为负样本,但是分错了,其实是正样本”。
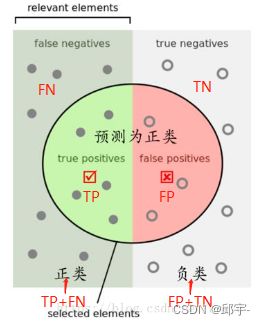
按上图来解释,左半矩形是正样本,右半矩形是负样本。一个二分类器,在图上画了个圆,分类器认为圆内是正样本,圆外是负样本。
TP:那么左半圆分类器认为是正样本,同时它确实是正样本,那么就是“被分为正样本,并且分对了”即TP,
FN:左半矩形扣除左半圆的部分就是分类器认为它是负样本,但是它本身却是正样本,就是“被分为负样本,但是分错了”即FN。
FP:右半圆分类器认为它是正样本,但是本身却是负样本,那么就是“被分为正样本,但是分错了”即FP。
TN:右半矩形扣除右半圆的部分就是分类器认为它是负样本,同时它本身确实是负样本,那么就是“被分为负样本,而且分对了”即TN。
(2)精度(Precision)和召回率(Recall)

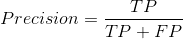
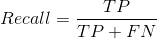
Precision=(TP/(TP+FP)):翻译成中文就是“分类器认为是正类并且确实是正类的部分占所有分类器认为是正类的比例”,衡量的是一个分类器分出来的正类的确是正类的概率。
Recall=(TP/(TP+FN)):翻译成中文就是“分类器认为是正类并且确实是正类的部分占所有确实是正类的比例”,衡量的是一个分类能把所有的正类都找出来的能力。
通常,精度和召回率是两个互斥的指标,当精度高的时候,召回率就低,当召回率高的时候,精度就低。精度是用来衡量图像中需要检测的各个物体检测的准确度;召回率用来衡量图像中需要检测的每个物体是否都检测到了。
(3)IoU(Intersection of Union,交并比) 当进行预测的时候,预测值跟真实值尽可能地越接近越好。
当进行预测的时候,预测值跟真实值尽可能地越接近越好。
IoU越高,说明预测值和真实值越接近,检测的效果越好。
(4)置信度
通俗来讲,置信度就是计算机对于自己检测结果的自信程度,当计算机觉得自己检测得很准确时,置信度就高,当计算机好像不是很确定自己检测的准不准的时候,置信度就低。
目标检测过程中,往往最后会生成很多的预测框,每个预测框自身都会带一个置信度,用来衡量预测框内为检测目标的自信程度,置信度越高,说明当前训练的模型对于这个框的结果越认可。这个认可的程度就被称为置信度。
当进行目标检测时,可以设置一个置信度阈值(比如:0.9,0.8,0.7),当预测框的置信度低于该阈值时,该预测框被认为是一个【被错分为负样本的正样本FN】,只有置信度等于或高于阈值的预测框才会被认为是一个【正确分类的正样本TP】。
 上面的小图可能看不清置信度,来张大的。
上面的小图可能看不清置信度,来张大的。
(5)AP(Average Precision,平均精度)和PR曲线
PR曲线:在直角坐标系中,通过描点的方式表示精度P(Precision)和召回率R(Recall)二者的关系,然后将这些点连接起来绘制的一条曲线。
AP:将PR曲线中每个“峰值点”往左画一条线段直到与上一个峰值点的垂直线相交。这样画出来的红色线段与坐标轴围起来的面积就是AP值。
如图所示,在这里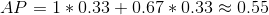
 (5)(6)mAP(mean Average Precision,均值平均精度)
(5)(6)mAP(mean Average Precision,均值平均精度)
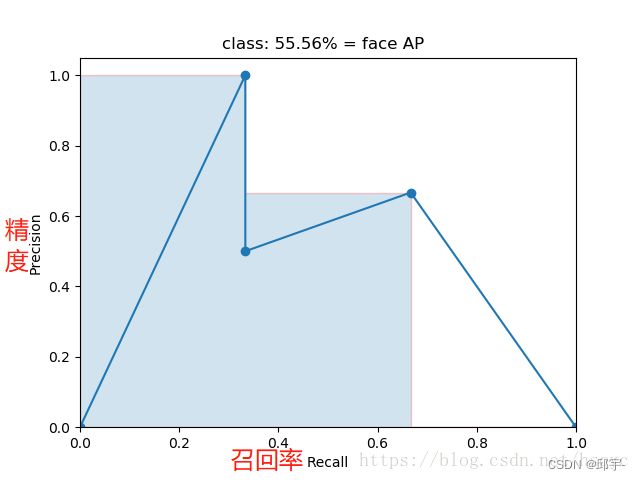
mAP就是所有类别的平均,是对检测效果的综合衡量。作为物体检测中衡量检测精度的指标,其计算公式为:
mAP = 所有类别的平均精度求和除以所有类别。
是对多个验证集求平均AP值,其中QR指验证集个数:
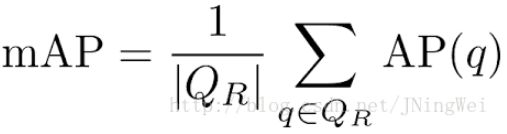
mAP值越接近于1越好。
二、YOLOv1
YOLOv1是经典的one-stage方法,把检测问题转化成回归问题,一个CNN就搞定了,可以对视频进行实时检测,应用领域非常广!
在YOLO系列检测算法面世之前,比较火的检测算法是Fast-Rcnn,但Fast-Rcnn的缺点就是检测速度太慢,FPS太低,不适合实时检测。YOLO系列算法出现后,虽然从检测效果来看mAP值比Faster-Rcnn低了十个点,但是仍以其极高的FPS深受人们喜爱。

1.YOLOv1的核心思想
把输入数据分成SxS个小格子,每个小格子预测出四个坐标值(归一化之后的偏移量,在0到1之间)和一个置信度,坐标值表示bounding box的位置,置信度值表示的是当前这个点对应的是物体的可能性有多大,置信度比较小的表示它很可能不是一个物体,而只是背景,会被过滤掉,剩下的每个小格子会产生两种候选框并且分别与真实值(即真实框)计算IoU,选出IoU大的一个候选框进行微调,最终得到实际的预测框。
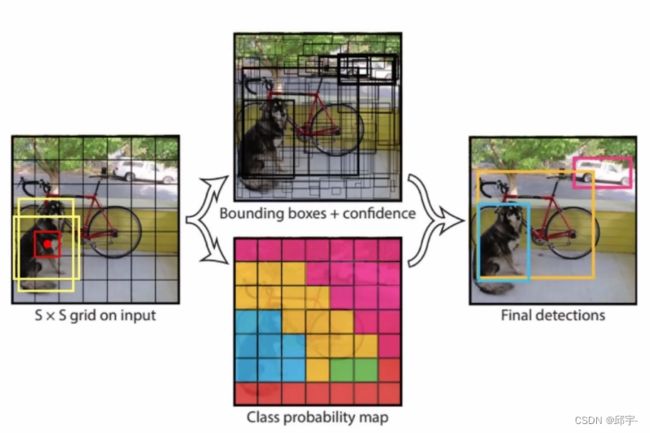
2.网络架构
首先,拿到一张输入图像,大小是指定的448x448x3,但并不是只能检测固定大小的图像,而只是把图像Resize到固定值,图像里面物体的坐标都相应的会做改变,可以实际的映射到原始的输入图像当中。这是由于YOLOv1中有全连接层。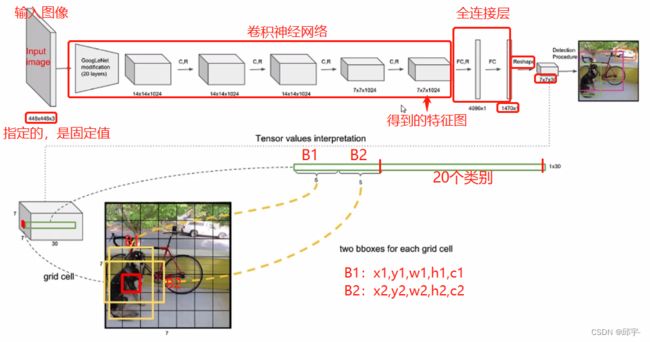
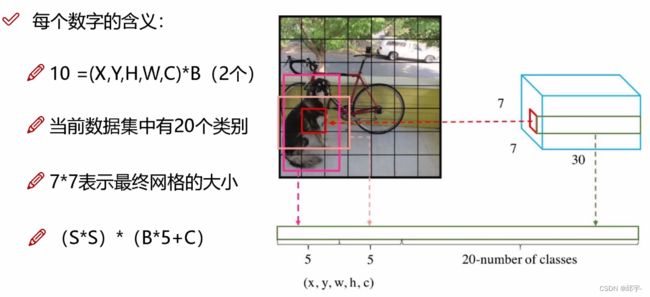
7x7x30:7x7表示格子的大小,30表示每个格子中有30个值。每个格子产生两种候选框,每种框对应5个值:x,y,w,h,c,其中x,y,w,h表示的是每个格子归一化之后的偏移量,在0到1之间,c表示的是候选框的置信度。于是前10个值就是两种候选框对应的5个值,剩下的20个值表示有20个类别,每个值代表的是当前这个格子检测出来的物体属于每个类别的概率值。
3.损失函数
损失函数由三部分组成:坐标预测损失、置信度预测损失(分为含有object的和不含object的)、分类预测损失。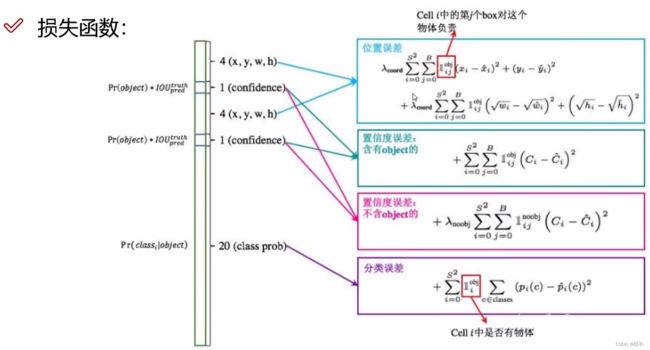
式中,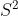 即SxS,代表格子的数量,B代表每个格子产生的候选框的个数。
即SxS,代表格子的数量,B代表每个格子产生的候选框的个数。
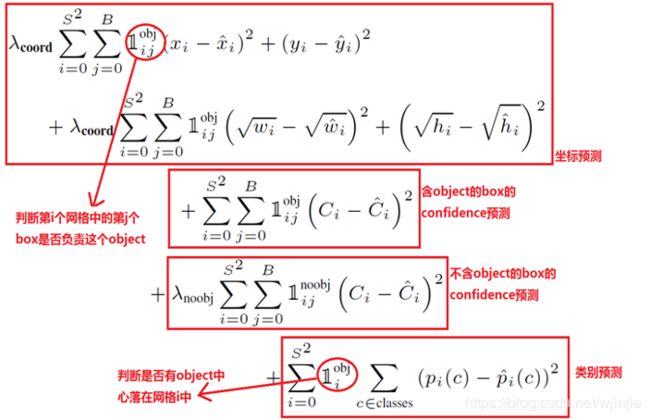
(1)坐标预测损失(也称定位误差、位置误差)
使用的是差方和误差。需要注意的是,w和h在进行误差计算的时候取的是它们的平方根,原因是对不同大小的bounding box预测中,相比于大物体bounding box预测偏一点,小物体box预测偏一点更不能忍受。而差方和误差函数中对同样的偏移loss是一样。 为了缓和这个问题,作者用了一个比较取巧的办法,就是将bounding box的w和h取平方根代替原本的w和h。
![]() ,是对定位误差增加的惩罚系数。
,是对定位误差增加的惩罚系数。
(2)置信度预测损失(也称置信度误差)
在每个图像中,许多网格单元不包含任何目标。训练时就会把这些网格里的框的“置信度”分数推到零,这往往超过了包含目标的框的梯度。从而可能导致模型不稳定,训练早期发散。因此要减少了不包含目标的框的置信度预测的损失,使 ![]() 。
。
(3)分类预测损失(也称分类误差)
预测值的概率和真实值的概率之间的差方和误差。比如:预测是猫的概率和物体真的是猫的概率之间的差值。
4.NMS(非极大值抑制)
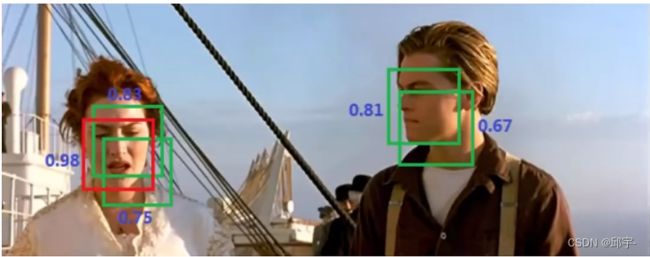
在预测框的时候,可能检测到的很多框都是重叠的。比如同样一个人,检测到的人脸框有很多个,将IoU大于一定比例的先按置信度进行排序,只取其中置信度值最大的人脸框,其余的忽略掉。
5.优缺点
优点:快速、简单!
(1)标准版本的YOLOv1可以每秒处理45张图像,极速版本的YOLOv1每秒可以处理150帧图像。这就意味着YOLO可以以小于25ms延迟,实时地处理视频。对于欠实时系统,在保证准确率地情况下,YOLO速度快于其他方法。
(2)YOLO实时监测的平均精度是其他实时监测系统的两倍。
(3)迁移能力强,能运用到其他的新的领域。(比如艺术品目标检测)
缺点: 问题1:每个cell只预测一个类别,如果重叠无法解决。比如在同一个格子中有两种不同的物 体,一只狗把后面的一只猫挡住了一部分,那么后面的猫就检测不出来。
问题2:小物体检测效果一般,长宽比可选但单一(只有两个候选框)。