使用PyTorch搭建CNN神经网络
使用pytorch搭建CNN神经网络
- 卷积运算的基本原理
-
- 单层卷积运算
-
- valid convolution
- same convolution
- CNN的基本结构
-
- 数据输入层
- 卷积层
- 池化层
- 全连接层
- 数据导入的实现
- 构建基础的CNN网络
-
- 网络的设计
- 损失函数和优化器
- 训练函数和测试函数
- 实现CNN网络的训练和测试
- Googlenet的实现
-
- 网络框架
- Resnet的实现
-
- 网络框架
卷积运算的基本原理
单层卷积运算
valid convolution
所谓卷积运算就是一个卷积核[也称为过滤器]对指定大小的矩阵进行卷积的过程,具体运算方式如下图所示:
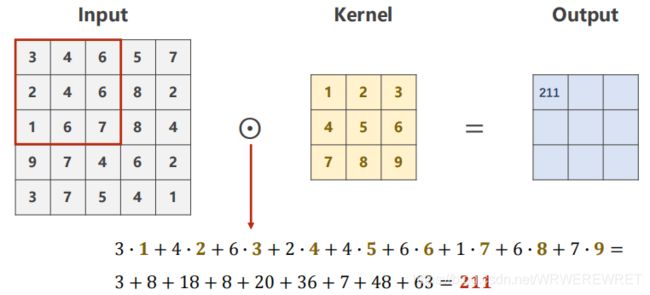
对于一个5x5的方阵,用一个3x3大小的卷积核进行卷积运算,可以看到首先对方阵左上角的3x3方块进行卷积运算,即将3*方块里的每个数与卷积核对应位置上的每个数相乘,最后将九个数相加,得到输出矩阵的第一个元素。
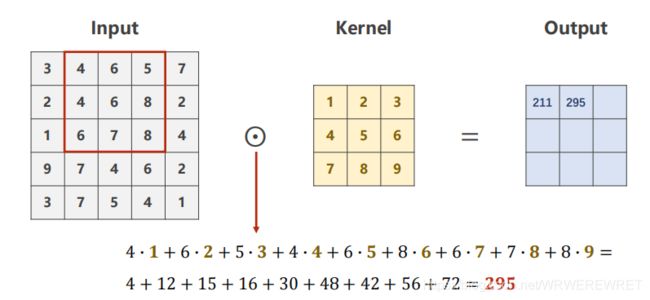
接着,我们将步长默认设置为1,对输入矩阵的第二至四列3x3方块进行卷积运算。
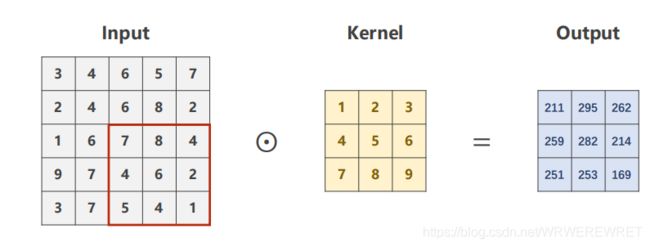
以此类推,将5x5矩阵中所有的3x3方块全部进行一次卷积运算后,即可得到输出矩阵,这就完成了指定卷积核对输入矩阵的卷积,可以由上图中看到,对于一个5x5矩阵使用3x3的卷积核进行卷积运算后得到的输出矩阵为3x3矩阵,由此我们可以得到一个公式:对于一个nxn大小的矩阵,使用mxm大小的卷积核进行计算后得到输出矩阵的大小为(n-m+1)x(n-m+1)大小的矩阵。另外我们也可以设置卷积计算中步长stride的大小,如果将步长设置为2,那么我们每次需要将3x3方块移动两列再与卷积核进行卷积运算,这样得到的输出矩阵大小变为{(n-m)/stride+1} x {(n-m)/stride+1 } [表示对值向下取整],这种卷积运算也称为valid convolution,还有另外一种卷积运算叫做same convolution。
same convolution
在valid convolution计算中,我们得到的输出矩阵大小一般小于输入矩阵,为了使矩阵大小不改变,在卷积运算中可以设置一个参数padding,即在输入矩阵周围填充padding大小的像素值,一般填充0,如图所示:

对于3x3大小的卷积核,我们为了保证输出矩阵大小也为5x5,我们需要将padding设置为1,于是,在same convolution中,输出矩阵[输入矩阵大小为nxn,输出矩阵大小为mxm,步长为stride]的大小公式更新为:{(n+2padding-m)/stride+1} / {(n+2padding-m)/stride+1}。
为了保证输入输出矩阵大小相同,必须满足padding = (f - 1)/2。
##高维度卷积运算
CNN神经网络一般用于处理图像信息,一个图像信息是由RGB三个像素层构成,于是这个时候我们必须同时改变卷积核的通道数,使其与输入数据保持一致。

对于这样一个图像信息,我们需要三个单层卷积核分别对三个像素层进行卷积运算,这个时候我们得到了三个矩阵,然后将三个矩阵相加,即得到了对图像信息进行卷积运算的输出矩阵。

可以看到,无论是多少层数的输入矩阵,最后得到的输出矩阵永远只有一层。若是希望区别不同的颜色,即可将立体卷积核对应的不同层数中的元素分别设置为需要的值。
CNN的基本结构
数据输入层
一般在这一层我们会构建好要训练和测试的数据,本文使用的数据是torchvision下的dataset里面的mnist库。
卷积层
卷积层就是对输入数据进行卷积运算,然后使用激活函数对数据进行激活,常用的激活函数由sigmoid、relu函数等。
池化层
再对每个输入信息进行完卷积运算后还需要对输出数据进行池化,如图所示:
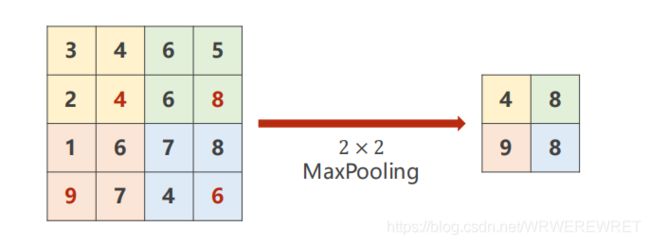
这是一种池化方式叫做最大池化,集设置过滤器的大小,然后取出每个区域块的最大的数值,从而得到池化后的结果,池化后矩阵大小为[输入矩阵为 nxn 大小,过滤器为 fxf 大小] {(n/f)} x {(n/f)}
另外还有别的池化方式,详情请参考链接https://blog.csdn.net/qq_31908897/article/details/90607050
全连接层
全连接层和DNN里的全连接层一样,全连接一般会把卷积输出的二维特征图转化成一维的一个向量,高度提纯图像信息的特征,方便交给最后的分类器或者回归。
数据导入的实现
本文训练和测试使用的是mnist库,可以直接在python中下载,比较方便,以下是本文所有代码需要导入的库:
import torch
import matplotlib.pyplot as plt
from torchvision import transforms, datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
接下来加载数据集:
#加载数据集
batch_size = 10
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307, ), (0.3081, ))])
train_dataset = datasets.MNIST(root = '../dataset/mnist', train = True, download = True, transform = transform)
train_loader = DataLoader(train_dataset, batch_size = batch_size, shuffle = True)
test_dataset = datasets.MNIST(root = '../dataset/mnist/', train = False, download = True, transform = transform)
test_loader = DataLoader(test_dataset, shuffle = False, batch_size = batch_size)
1.batch_size是一次训练数据的批量,可以自行设计。
构建基础的CNN网络
网络的设计
#构建网络
class ConvolutionNet(torch.nn.Module):
def __init__(self):
super(ConvolutionNet,self).__init__()
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size = 5)
self.conv2 = torch.nn.Conv2d(10, 20, kernel_size = 5)
self.pooling = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(320, 10)
def forward(self, x):
batch_size = x.size(0)
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size, -1)
x = self.fc(x)
return x
model = ConvolutionNet()
下图是计算的流程:
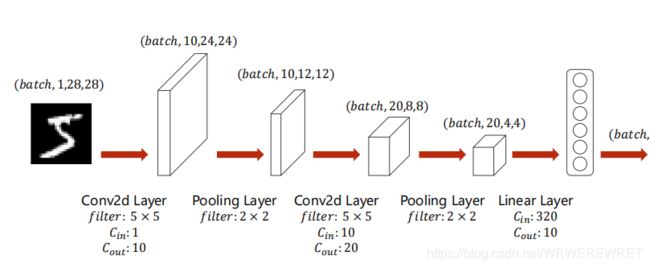
输入数据首先经过第一个卷积层,池化后进入第二个卷积层,再池化,最后进入全连接层。
对代码解释:
1.在torch库中的Conv2d函数能帮助我们自动实现卷积运算,具体的参数介绍请参考https://blog.csdn.net/qq_42079689/article/details/102642610
2.池化层所使用的函数是Maxpool2d,此外还有avg_pool2d之类的函数,都可使用。
3.大家自己设置Conv2d的参数时,若是不清楚全连接层里面数据元素的个数,可以先不写全连接层函数,将forward函数修改为
def __init__(self):
super(ConvolutionNet,self).__init__()
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size = 5)
self.conv2 = torch.nn.Conv2d(10, 20, kernel_size = 5)
self.pooling = torch.nn.MaxPool2d(2)
#self.fc = torch.nn.Linear(320, 10)
def forward(self, x):
batch_size = x.size(0)
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size, -1)
print(x.size())
#x = self.fc(x)
return x
先运行一次,查看x的规格,再补充全连接层。
损失函数和优化器
#构建损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr = 0.01, momentum = 0.5)
损失函数使用的是交叉熵函数,具体的函数介绍和参数设置可以参考pytorch官网,另外类型的损失函数和优化器类型请参考https://blog.csdn.net/shanwenkang/article/details/86634714
也可以自己构建损失函数和优化器。
训练函数和测试函数
#构建训练和测试函数
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss:%.3f' % (epoch + 1, batch_idx + 1, running_loss / 2000))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs, target = data
outputs = model(inputs)
_, predicted = torch.max(outputs.data, dim = 1)
total += target.size(0)
correct += (predicted == target).sum().item()
print('Accuracy on test set:%d %% [%d/%d]' % (100 * correct / total, correct, total))
return 100 * correct / total
实现CNN网络的训练和测试
if __name__ == '__main__':
len = 10
x = [0] * len
y = [0] * len
for epoch in range(10):
train(epoch)
y[epoch] = test()
x[epoch] = epoch
plt.plot(x, y)
plt.xlabel('epoch')
plt.ylabel('Accuracy')
plt.grid()
plt.show()
由于兼容性原因,不能直接运行代码,需要先封装后运行,另外上述代码含有学习曲线的画图部分,若不需要,读者可以删去。
Googlenet的实现
网络框架

这是Googlenet的基本框架,可能看起来比较的复杂,但是我们发现有许多重复的小块,于是我们可以把这些小块代码进行封装,尽可能的减小代码冗余,这些重复性较高的代码块也称为inception块,其模式如下图:
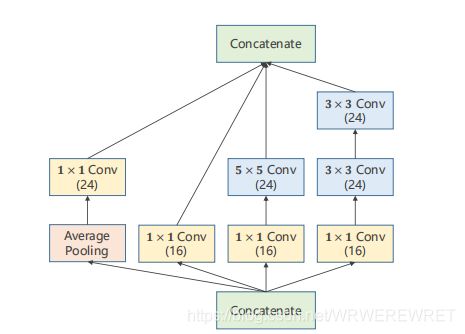
该模块含有四个通道,将输入数据通过四个通道分别进行卷积运算处理,最后将所得的四个张量整合,得到最后结果,在训练过程中,通过调整通道占比来达到训练的目的。
具体实现代码如下:
#设计inception模块
class InceptionA(torch.nn.Module):
def __init__(self, in_channels):
super(InceptionA, self).__init__()
#第一个分支
self.branch1x1 = torch.nn.Conv2d(in_channels, 16, kernel_size = 1)
#第二个分支
self.branch5x5_1 = torch.nn.Conv2d(in_channels, 16, kernel_size = 1)
self.branch5x5_2 = torch.nn.Conv2d(16, 32, kernel_size = 5, padding = 2)
#第三个分支
self.branch3x3_1 = torch.nn.Conv2d(in_channels, 16, kernel_size = 1)
self.branch3x3_2 = torch.nn.Conv2d(16, 32, kernel_size = 3, padding = 1)
self.branch3x3_3 = torch.nn.Conv2d(32, 32, kernel_size = 3, padding = 1)
#第四个分支
self.branchpool = torch.nn.Conv2d(in_channels, 32, kernel_size = 1)
def forward(self, x):
x1 = self.branch1x1(x)
x2 = self.branch5x5_1(x)
x2 = self.branch5x5_2(x2)
x3 = self.branch3x3_1(x)
x3 = self.branch3x3_2(x3)
x3 = self.branch3x3_3(x3)
x4 = F.avg_pool2d(x, kernel_size = 3, stride = 1, padding = 1)
x4 = self.branchpool(x4)
outputs = [x1, x2, x3, x4]
return torch.cat(outputs, dim = 1)
Resnet的实现
网络框架

与一般的神经网络区别在于它将输入数据和输出数据一同作为下个卷积层的输入数据进行计算。
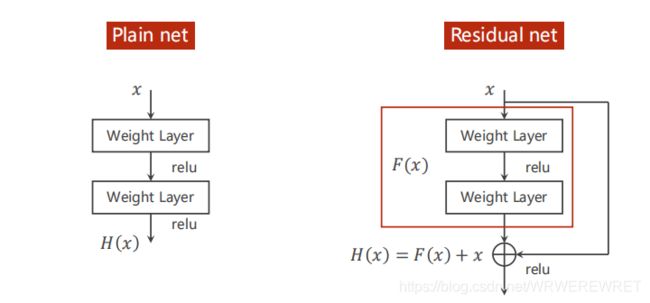
如图所示的代码块也称作Residual Block。
实现代码如下:
#定义Residual Block
class ResidualBlock(nn.Module):
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.channels = channels
self.conv1 = nn.Conv2d(channels, channels, kernel_size = 5, padding = 2)
self.conv2 = nn.Conv2d(channels, channels, kernel_size = 5, padding = 2)
def forward(self, x):
y = F.relu(self.conv1(x))
y = self.conv2(y)
y = self.conv2(y)
return F.relu(x + y)
#构建神经元
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size = 3)
self.conv2 = nn.Conv2d(32, 64, kernel_size = 3)
self.pooling = nn.MaxPool2d(2)
self.resblock1 = ResidualBlock(32)
self.resblock2 = ResidualBlock(64)
self.fc1 = nn.Linear(1600, 200)
self.fc2 = nn.Linear(200, 10)
def forward(self, x):
in_size = x.size(0)
x = self.pooling(F.relu(self.conv1(x)))
x = self.resblock1(x)
x = self.pooling(F.relu(self.conv2(x)))
x = self.resblock2(x)
x = x.view(in_size, -1)
x = self.fc1(x)
x = self.fc2(x)
return x
model = Net()
以上是我学习刘老师的pytorch网课后结合自己的理解整理出来的文章,若有任何问题,欢迎大家指出。