深度学习笔记(二)
计算机视觉:
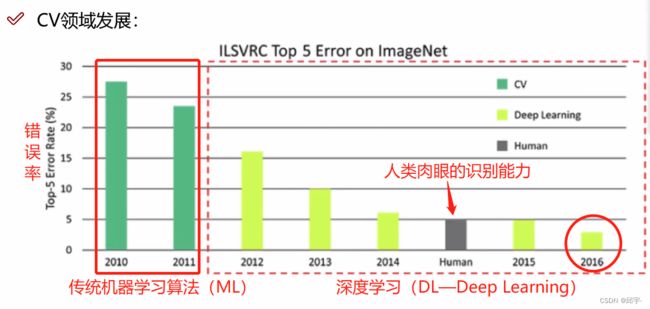 人类肉眼识别的错误率大概在5%。到2016年的时候,计算机视觉中,用深度学习网络达到的错误率已经远低于人类。
人类肉眼识别的错误率大概在5%。到2016年的时候,计算机视觉中,用深度学习网络达到的错误率已经远低于人类。
卷积神经网络(CNN)
1.应用领域

神经网络和卷积神经网络都是用来做特征提取的。传统神经网络在特征提取上有一些问题:第一点,权重参数矩阵特别大;第二点,过拟合风险比较高。卷积神经网络一定程度上就是要解决这些问题。
 超分辨率重构:怎么样重构一张图像,怎么样把一张图片做得更清晰一些?通过训练一个网络达到这些效果。
超分辨率重构:怎么样重构一张图像,怎么样把一张图片做得更清晰一些?通过训练一个网络达到这些效果。


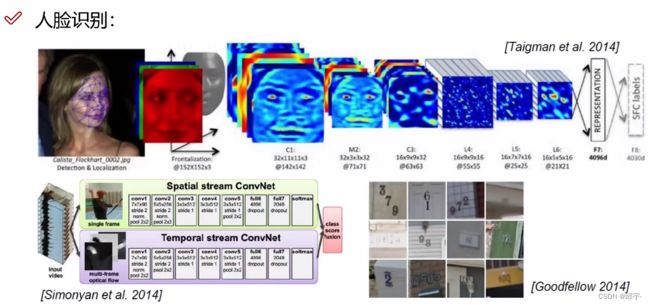
对人脸做重构、对人脸进行一些分析、关键点的提取、特征提取,然后去分析、判断这个人是不是一个人,或者判断这个人是谁。
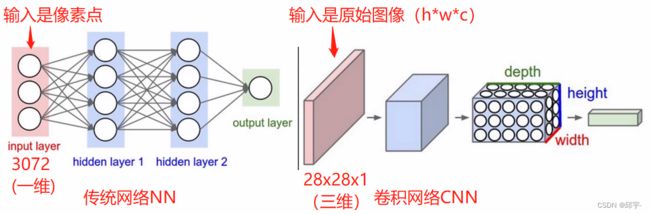
2、卷积网络与传统网络的区别
卷积神经网络整体架构:
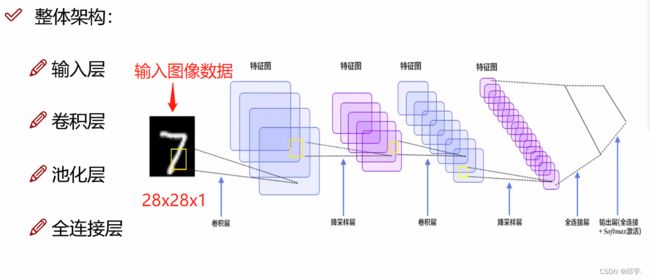 卷积层是提取特征,池化层是压缩特征。
卷积层是提取特征,池化层是压缩特征。
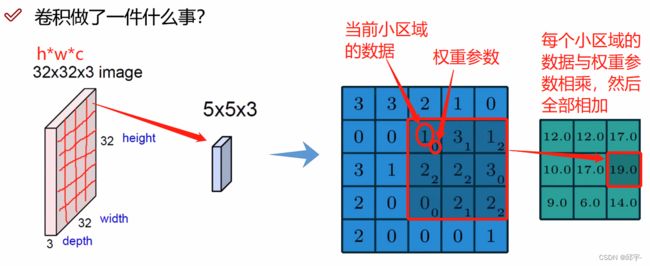 对于一张猫的输入图像,在提取特征时,边界的特征和猫的嘴巴、眼睛的特征是不一样的,把一张图像分成很多部分,对于不同的区域需要提取不同的特征,有的特征重要,有的特征不重要(比如边界特征、背景),需要区别进行处理。
对于一张猫的输入图像,在提取特征时,边界的特征和猫的嘴巴、眼睛的特征是不一样的,把一张图像分成很多部分,对于不同的区域需要提取不同的特征,有的特征重要,有的特征不重要(比如边界特征、背景),需要区别进行处理。
在做卷积的过程中,需要先把图像进行分割,分割为很多小区域,每个小区域是由多个像素点组成的,对每个小区域进行特征提取。接下来,选择一种计算方法,对于每个小区域计算特征值。
3.卷积特征值计算方法

实际的计算当中,要每个颜色通道分别去做计算,最终再把每个通道卷积完的结果加在一起。
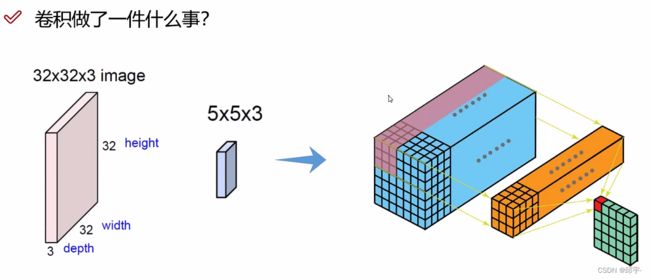 找到一个立体的区域,对每个区域进行特征提取,得到最终的一个特征值。
找到一个立体的区域,对每个区域进行特征提取,得到最终的一个特征值。
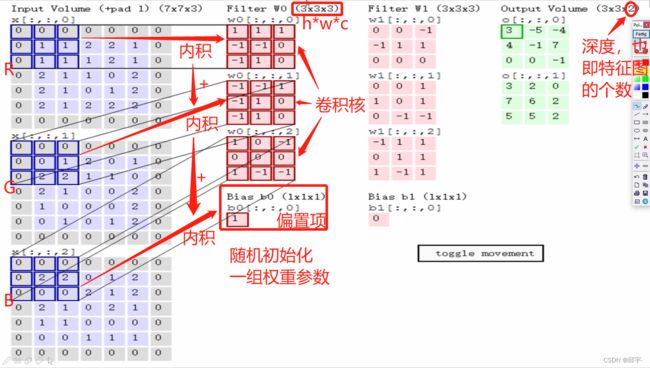
R、G、B的维度都是7x7x1,合在一起是7x7x3的输入。然后分区域对当前的输入进行特征提取。
Filter w0表示先随机化初始一组权重参数。同一个输入数据中不同的部分,它在不同的颜色通道当中像素点值是不一样的。输入数据的通道数c是多少,则Filter中的第三个维度就必须跟它一致。Filter w0中的h*w是卷积核,它的大小代表着在原始输入数据中每多大(比如3*3)的小区域选出来一个特征,对应一个特征值。
所有的卷积网络当中都是用内积做计算的,即对应位置相乘后,所有结果加在一起,最后再加上偏置项。例如上图中所示区域:
R通道的值:0x1+0x1+0x1+0x(-1)+1x(-1)+1x0+0x(-1)+1x1+1x0=0
G通道的值:0x(-1)+0x(-1)+0x1+0x(-1)+0x1+1x0+0x(-1)+2x1+2x0=2
B通道的值:0x1+0x0+0x(-1)+0x0+2x0+2x0+0x1+0x(-1)+0x(-1)=0
w0得到的特征提取的值:(0+2+0)+1(偏置项)=3,对应的就是图中绿色框中的3

第一步,先粗粒度的提取一些大致的特征;
第二步,再细粒度的提取一些中间特征;
最后,再提取一些组合成的高级特征。
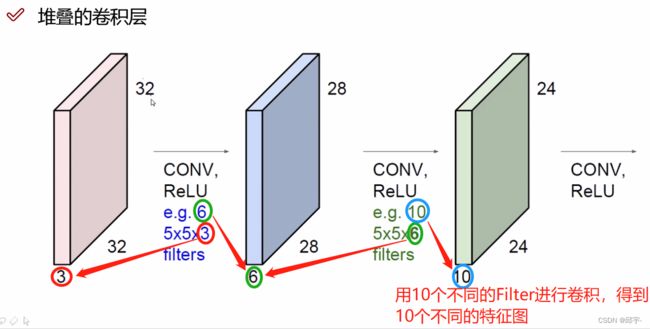
这说明输入一张图像数据后,做一次卷积是不够的,需要进行多次特征提取。通过多次卷积提取出来的特征,才认为是比较好的。卷积层中可以无限制的往下堆叠。
4.卷积层涉及参数 
(1)步长
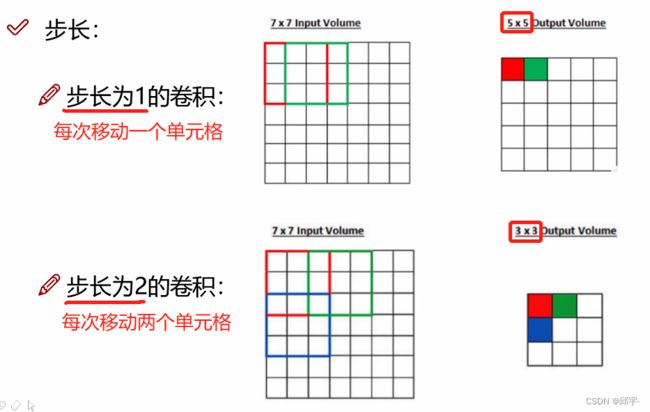 能移动的单元格越多,得到特征值越多,特征图也就越大。
能移动的单元格越多,得到特征值越多,特征图也就越大。
当步长比较小的时候,相当于慢慢地细粒度地去提取特征,这样得到的特征是比较丰富的;当步长比较大的时候,得到的特征是比较少的。实际步长大小的设置是跟具体任务相关的,一般对于图像任务来说,选择步长为1。当然步长为1时,得到的特征比较多,计算的效率也就比较慢。
(2)卷积核尺寸
卷积核越小,也是相当于越细粒度的去提取特征;卷积核越大,提取的特征也就越少。一般情况下,最小的卷积核是3x3。
(3)边缘填充
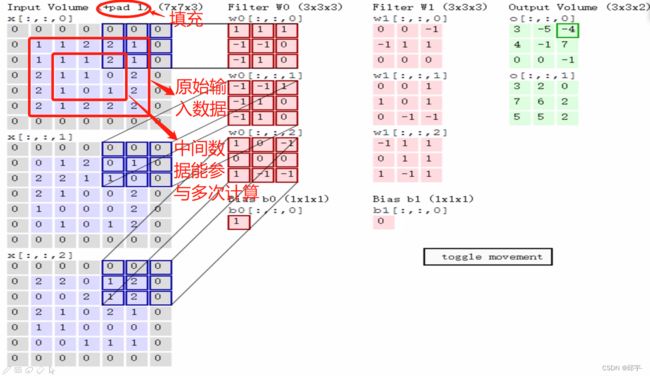 在卷积计算过程中,越往边界的点,能够计算到的次数越少;越往中间的点,能够计算到的次数越多。为了解决这个问题,在边界点外面加上一圈0,使边界点远离边界,一定程度上能弥补边界信息缺失、边界特征利用不充分的问题。加0而不是加其他数据的原因是,如果添加其他数据,比如1,则在计算过程中会对最终结果产生影响;而加0则只会起到一个数据扩充作用,不会影响最终结果。我们将其叫做zero pading——以0为值进行边界填充。可以按照自己的需求添加多圈0。
在卷积计算过程中,越往边界的点,能够计算到的次数越少;越往中间的点,能够计算到的次数越多。为了解决这个问题,在边界点外面加上一圈0,使边界点远离边界,一定程度上能弥补边界信息缺失、边界特征利用不充分的问题。加0而不是加其他数据的原因是,如果添加其他数据,比如1,则在计算过程中会对最终结果产生影响;而加0则只会起到一个数据扩充作用,不会影响最终结果。我们将其叫做zero pading——以0为值进行边界填充。可以按照自己的需求添加多圈0。
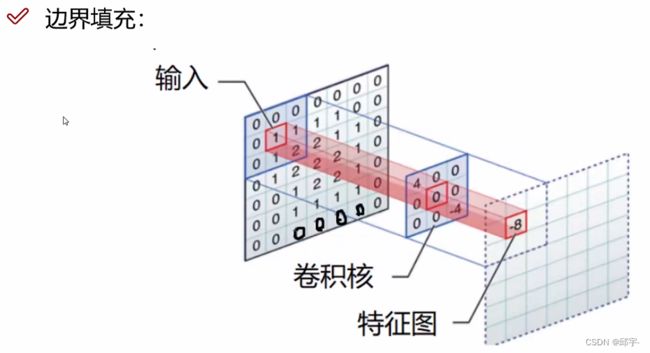
(4)卷积核个数
也就是在计算的过程中,最终要得到多少个特征图。比如要得到10个特征图,卷积核的个数就定为10;要得到20个特征图,卷积核的个数就为20。
5.卷积计算公式
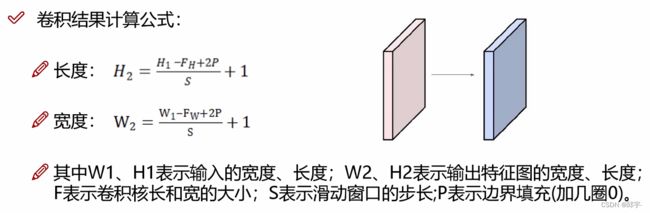 假设卷积核的大小是3x4,则
假设卷积核的大小是3x4,则![]() 等于3,
等于3,![]() 等于4.
等于4.

6.卷积参数共享
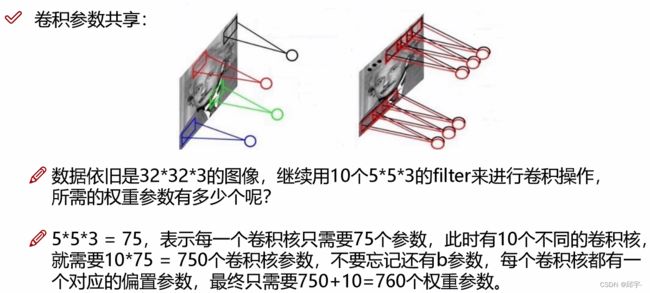
卷积神经网络的一个优点就是卷积参数共享。用同样一组卷积核对图像中每一个小区域进行特征提取,在进行特征提取时,卷积核里面的参数值是不变的,这样的话卷积神经网络里面的权重参数要比传统的全连接网络中的参数少得多,方便训练。
7.池化层
(1)池化层的作用
池化层是用来压缩特征图的,也叫做下采样(downsampling)。当提取的特征过多,并不是所有的都有用,选择重要的特征留下,不重要的就丢弃。

压缩的过程:在每个小区域选择其中比较重要的特征留下,不重要的就进行丢弃。
注意:特征图的个数不会变,只会改变特征图的长(h)和宽(w)。
(2)最大池化
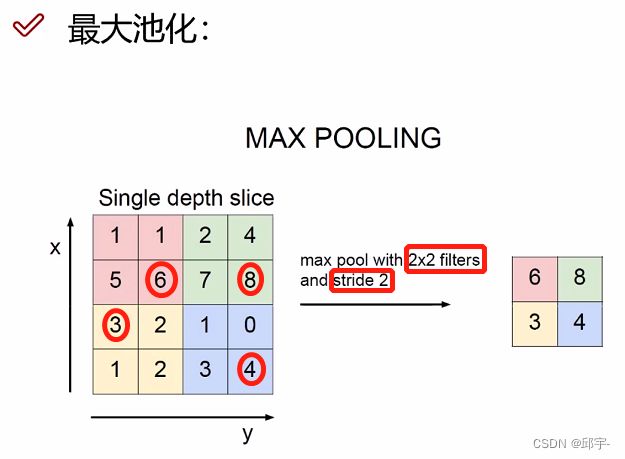
最大池化:按照固定的filter大小和步长,在每个小区域中提取出最大值(即最重要的特征),组成新的特征图。
平均池化(aver pooling):按照固定的filter大小和步长对特征图进行分区,将每个小区域中的特征值计算其平均值,然后组成新的特征图。
例如:上图中,黄色区域的特征值进行平均,即(3+2+1+2)/4=2,则对应的新的特征图的黄色区域就是2。
注意:池化层中没有涉及到任何的矩阵计算,它只是进行一个压缩、筛选、过滤。
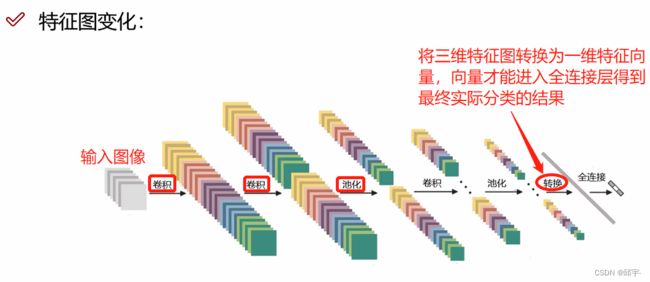
8.整体网络架构
首先,一张图像输入以后先通过卷积进行特征提取,与传统神经网络一样,每个卷积层后面都搭配一个Relu函数,且执行多次卷积后就需要进行一次池化压缩。经过多次的“卷积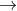 Relu线性变换卷积线性变换池化”这一过程后,需要将得到的三维特征图转换为一维的特征向量,然后通过全连接层来得到各个类别的概率值。假如经过特征提取后得到一个32x32x10的三维特征图,转换为一维特征向量,包含10240个特征值,然后将其转换为各个类别的概率值。
Relu线性变换卷积线性变换池化”这一过程后,需要将得到的三维特征图转换为一维的特征向量,然后通过全连接层来得到各个类别的概率值。假如经过特征提取后得到一个32x32x10的三维特征图,转换为一维特征向量,包含10240个特征值,然后将其转换为各个类别的概率值。
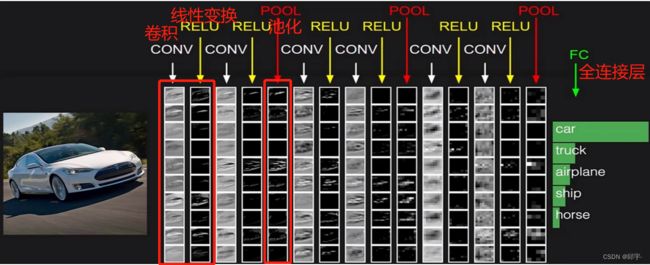
一个神经网络包含多少层?带参数计算的才能叫做一层,卷积层要乘内积然后加偏执参数,是带参数计算的,全连接层也有权重参数矩阵,也是带参数计算的,Relu激活函数和池化层都不带参数计算。如上图所示,有6个卷积层和1个全连接层,加在一起是一个7层的神经网络。