pytorch的损失函数总结
最近在学习DL相关的一些论文,想要用pytorch复现一些算法,发现pytorch中内置了许多损失函数。虽说这些东西都可以自己实现,但是本着尽量避免造轮子的原则,还是希望能够在可以调用现有的接口时直接调用他们。
在试图使用时发现,这里面存在一些不大不小的坑。因此,在这里对pytorch中的这些损失函数做个总结,方便自己和他人学习和使用。
(我用的是python 3.6.8, pytorch版本号为1.1.0)
预计会总结以下内容,在工作中需要用到或者业余看论文和coding时遇到相关的东西时慢慢增加,有兴趣的同学可以先关注,写完了再看。
nn.NLLLoss(),
nn.KLDivLoss(),
nn.CrossEntropyLoss(),
nn.MSELoss(),
nn.AdaptiveLogSoftmaxWithLoss(),
nn.BCELoss(),
nn.BCEWithLogitsLoss(),
nn.CosineEmbeddingLoss(),
nn.CTCLoss(),
nn.HingeEmbeddingLoss(),
nn.MarginRankingLoss(),
nn.MultiLabelMarginLoss(),
nn.MultiLabelSoftMarginLoss(),
nn.MultiMarginLoss(),
nn.PoissonNLLLoss(),
nn.SoftMarginLoss(),
nn.NLLLoss2d(),
nn.TripletMarginLoss(),
nn.L1Loss(),
nn.SmoothL1Loss()
nn.NLLLoss
构造函数的参数说明:
nn.NLLLoss(self, weight=None, size_average=None, ignore_index=-100,reduce=None, reduction='mean')这些参数全部都是可选的。
weight可以给不同类别不同的权重,默认所有类别的权重相同;
size_average已被废除;
ignore_index可以指出某个类别是无用的,最终不会给输入产生贡献,可以很方便的mask掉一些预测。当然,也可以自己构造一个{0,1}的mask矩阵和预测结果相乘来实现这个功能。
reduce:废除;
reduction:'none' | 'mean' | 'sum',这些中的任意一个,默认是‘mean’。‘none’表示不作维度约减,输出是向量,“sum”表示通过求和来输出标量的loss,“mean”表示对求和的结果除以样本数N来得到标量的loss。
含义
一般中文译作负对数似然损失。对于某一概率分布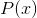 ,其似然函数为
,其似然函数为 ,对数似然为
,对数似然为 ,一般可以通过最大化似然函数来求解模型参数,由于习惯原因,总是通过加负号的方式把最大化问题转化为最小化问题,负对数似然函数的名称由此而来。
,一般可以通过最大化似然函数来求解模型参数,由于习惯原因,总是通过加负号的方式把最大化问题转化为最小化问题,负对数似然函数的名称由此而来。
在分类问题中,需要估计的分布通常是条件分布 ,其负对数似然函数为
,其负对数似然函数为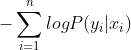 ,也可等价地写成
,也可等价地写成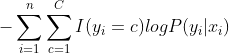 ,其中,
,其中,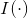 为指示函数。
为指示函数。
特殊地,在二分类情况下,可以写为 ,其中,
,其中,![]() 。
。
举例,对某一样本 的真实标签为第1类(从0开始),若其为四个类别的概率依次为![]() ,则负对数似然为
,则负对数似然为![]() 。
。
Pytorch中的nn.NLLLoss()假定输入的概率已经经过了log转换 。
其forward函数定义为:
def forward(self, input, target):
pass情况一,input的形状为![]() ,target的形状为
,target的形状为![]() 。含义为,有
。含义为,有 个样本,类别个数为
个样本,类别个数为 。input中的位置
。input中的位置 的元素表示第
的元素表示第 个样本的类别为
个样本的类别为 的对数概率,target中的第个元素表示第个样本的类别。
的对数概率,target中的第个元素表示第个样本的类别。
nll=nn.NLLLoss(reduction="none")
x=torch.Tensor([0.2,0.5,0.1,0.1]).reshape(1,-1)
y=torch.LongTensor([1])
print(-torch.log(x))
print(nll(torch.log(x),y))情况二,input的形状为![]() ,target的形状为
,target的形状为![]() ,暂时没用过,这里留个空,以后用到了再填。
,暂时没用过,这里留个空,以后用到了再填。
nn.KLDivLoss
构造函数的参数说明:
nn.KLDivLoss(self, size_average=None, reduce=None, reduction='mean')全部可选。
size_average:已废除
reduce:已废除
reduction:`'none'`` | ``'batchmean'`` | ``'sum'`` | ``'mean'``
意义基本同上,一点点区别是“batchmean”按N去平均的,“mean”是按元素个数平均的。例如,shape为(5,3)的话,前者按5平均,后者按15平均。
含义
KL散度,用来度量两个概率分布和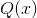 之间的距离,值越小表示这两个分布的一致程度越高,值越大表示这两个分布之间的越不一致。
之间的距离,值越小表示这两个分布的一致程度越高,值越大表示这两个分布之间的越不一致。
对离散分布而言,计算公式为: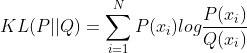 ,这里的表示离散分布的随机变量取值个数,而非机器学习中的样本数,可以近似理解为总共有类,这个分布表示某样本分为每一类的概率。
,这里的表示离散分布的随机变量取值个数,而非机器学习中的样本数,可以近似理解为总共有类,这个分布表示某样本分为每一类的概率。
举例,离散分布 为
为![]() ,离散分布
,离散分布 为
为![]() ,其KL散度为...(看下面代码吧,显然得)。
,其KL散度为...(看下面代码吧,显然得)。
pytorch的forward函数定义为:
def forward(self, input, target):
passinput的形状为![]() ,target的形状为
,target的形状为![]() ,其中,表示有多少对分布需要计算KL散度,大致对应机器学习中的样本数概念。后面为
,其中,表示有多少对分布需要计算KL散度,大致对应机器学习中的样本数概念。后面为 的原因是,概率分布可能是多维随机变量,而不必一定是一维随机变量。
的原因是,概率分布可能是多维随机变量,而不必一定是一维随机变量。
输入参数说明:默认input中的概率分布已经取了log,而target中的没取log。(这么设计的原因是上述KL散度的公式可以展开,其中分布Q只需要以logQ的形式出现),也就是说input对应公式中的Q,target对应公式中的P
from torch import nn
kl=nn.KLDivLoss(reduction="none")
a=torch.Tensor([0.2,0.5,0.1,0.1])
b=torch.Tensor((0.6,0.3,0.05,0.05))
print(kl(torch.log(a),b))
print((b*torch.log(b/a)))
nn.CrossEntropyLoss
构造函数:
def __init__(self, weight=None, size_average=None, ignore_index=-100,
reduce=None, reduction='mean'):weight: 给不同类别不同权重。
size_average: 已废除;
ingnore_index:预测出的某个类别被忽略掉,不对反向传播和梯度更新产生贡献
reduce:废除
reduction:“none”|“mean”|“sum”,none表示不缩减维度,输出向量形式的loss,sum是指通过求和获得标量loss,mean通过平均来获得标量loss
含义
熵是用来衡量一个分布的不确定程度的,对于离散分布而言,其计算公式为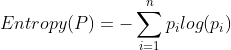 ,其中,
,其中, 为随机变量的取值个数,即在分类问题中的类别个数,
为随机变量的取值个数,即在分类问题中的类别个数, 表示随机变量等于的概率。
表示随机变量等于的概率。
交叉熵可以用来衡量两个分布的一致程度,对于离散分布而言,其计算公式为 ,特殊地,在分类问题中,类别
,特殊地,在分类问题中,类别 和预测概率
和预测概率 的交叉熵恰好为
的交叉熵恰好为 ,若将类别进行性one-hot编码,则可得到该样本的交叉熵损失为
,若将类别进行性one-hot编码,则可得到该样本的交叉熵损失为![]() ,其中,是该样本的标签编号。
,其中,是该样本的标签编号。 个样本的总损失则为
个样本的总损失则为 ,其中
,其中![]() 表示第k个样本属于第j类的概率,j为第k个样本的真实标签编号。此时,其实交叉熵损失和负对数似然损失是等价的。简单点总结一句,在分类问题中,对label进行onehot编码来计算预测概率和label的交叉熵等价于计算该概率模型的负对数似然损失。
表示第k个样本属于第j类的概率,j为第k个样本的真实标签编号。此时,其实交叉熵损失和负对数似然损失是等价的。简单点总结一句,在分类问题中,对label进行onehot编码来计算预测概率和label的交叉熵等价于计算该概率模型的负对数似然损失。
和KL散度也有一点点联系, ,当我们取P为实际的分布(例如,onehot过的label,或者labelsmoothing中的软label),Q为预测的概率分布时,KL散度展开后的第一项是常量,此时优化P和Q的KL散度等价于优化P和Q的交叉熵。
,当我们取P为实际的分布(例如,onehot过的label,或者labelsmoothing中的软label),Q为预测的概率分布时,KL散度展开后的第一项是常量,此时优化P和Q的KL散度等价于优化P和Q的交叉熵。
forward的参数和行为:
def forward(self, input, target):
pass情况一: input的形状![]() ,target的形状
,target的形状![]() 。假定输入的input是未经softmax的概率,有时也将其称为logit,该函数将logit取softmax变成概率,再和标签target算负对数似然损失,(也可以理解为去softmax变成概率,然后和onehot的target算交叉熵)。注意,由于pytorch中的nn.NLLLoss()假定输入的概率是经过了log转换的,所以nn.Crossentropy()等价于nn.LogSoftmax()+nn.NLLLoss()。
。假定输入的input是未经softmax的概率,有时也将其称为logit,该函数将logit取softmax变成概率,再和标签target算负对数似然损失,(也可以理解为去softmax变成概率,然后和onehot的target算交叉熵)。注意,由于pytorch中的nn.NLLLoss()假定输入的概率是经过了log转换的,所以nn.Crossentropy()等价于nn.LogSoftmax()+nn.NLLLoss()。
import torch
from torch import nn
nll=nn.NLLLoss()
cross=nn.CrossEntropyLoss()
input=torch.rand((5,3))#假定是还没有softmax的
input1=torch.softmax(input,dim=1)#softmax之后
target=torch.randint(0,3,(5,))
print(nll(torch.log(input1),target))
print(cross(input,target))情况二:input的形状![]() ,target的形状
,target的形状![]() ,暂时没用过,以后有空了再填坑
,暂时没用过,以后有空了再填坑
nn.MSELoss()
英文全称是 mean squared error (squared L2 norm),均方误差,没什么好解释的,计算公式:
构造函数:
def __init__(self, size_average=None, reduce=None, reduction='mean'):
passsize_average:已废除
reduce:已废除
redction:``'none'`` | ``'mean'`` | ``'sum'``
forward的参数:
def forward(self, input, target):
passinput的形状:(N,*),target的形状:(N,*),这里吐槽一下,reduction=“mean”的含义是按element个数平均,而没有提供reduction=“batchmean”的选项,所以想按batch_size平均的话,得自己取sum再除以N,这一点值得注意。
import torch
from torch import nn
mse=nn.MSELoss(reduction="none")
x=torch.randn((4,6))
y=torch.randn((4,6))
mse(x,y)nn.AdaptiveLogSoftmaxWithLoss
这个东西比较有意思,pytorch的文档中提到了一个叫zipf分布的东西,这个分布其实是一个经验分布。其通式可以写为![]() ,写到这里肯定很多人都认识了,其实无标度网络中的度分布就是服从这样的分布的,这个分布有时也被叫做幂律分布,或者长尾分布。这种分布在现实生活中也有例子,比如某云上歌曲的播放量,某宝上店铺的热度,自然语言中单词的词频,每个人拥有的财产量,都近似服从这样的分布。它描述的是极少数实体就掌握了绝大多数的资源(比所谓的2/8法则更加极端)。
,写到这里肯定很多人都认识了,其实无标度网络中的度分布就是服从这样的分布的,这个分布有时也被叫做幂律分布,或者长尾分布。这种分布在现实生活中也有例子,比如某云上歌曲的播放量,某宝上店铺的热度,自然语言中单词的词频,每个人拥有的财产量,都近似服从这样的分布。它描述的是极少数实体就掌握了绝大多数的资源(比所谓的2/8法则更加极端)。
那这个分布和这个损失函数有什么关系呢?
我们知道商品推荐、单词预测等问题可能会被形式化为一个类别数极大的多分类问题,当
“睡觉了,有空整理一下接着写”
这个损失函数和一篇论文有关,这里贴出来题目和链接《Efficient softmax approximation for GPUs》https://arxiv.org/abs/1609.04309
有空单独写一篇介绍这个论文。