使用NNI对DLASeg剪枝的失败记录
本文希望对CenterNet算法的Backbone暨DLASeg进行剪枝。
剪枝试验涉及3个文件,分别为:
DCN可变性卷积dcn_v2.py,因为DLASeg依赖DCN。
#!/usr/bin/env python
from __future__ import absolute_import
from __future__ import print_function
from __future__ import division
import math
import torch
from torch import nn
from torch.autograd import Function
from torch.nn.modules.utils import _pair
from torch.autograd.function import once_differentiable
import _ext as _backend
class _DCNv2(Function):
@staticmethod
def forward(ctx, input, offset, mask, weight, bias,
stride, padding, dilation, deformable_groups):
ctx.stride = _pair(stride)
ctx.padding = _pair(padding)
ctx.dilation = _pair(dilation)
ctx.kernel_size = _pair(weight.shape[2:4])
ctx.deformable_groups = deformable_groups
output = _backend.dcn_v2_forward(input, weight, bias,
offset, mask,
ctx.kernel_size[0], ctx.kernel_size[1],
ctx.stride[0], ctx.stride[1],
ctx.padding[0], ctx.padding[1],
ctx.dilation[0], ctx.dilation[1],
ctx.deformable_groups)
ctx.save_for_backward(input, offset, mask, weight, bias)
return output
@staticmethod
@once_differentiable
def backward(ctx, grad_output):
input, offset, mask, weight, bias = ctx.saved_tensors
grad_input, grad_offset, grad_mask, grad_weight, grad_bias = \
_backend.dcn_v2_backward(input, weight,
bias,
offset, mask,
grad_output,
ctx.kernel_size[0], ctx.kernel_size[1],
ctx.stride[0], ctx.stride[1],
ctx.padding[0], ctx.padding[1],
ctx.dilation[0], ctx.dilation[1],
ctx.deformable_groups)
return grad_input, grad_offset, grad_mask, grad_weight, grad_bias,\
None, None, None, None,
dcn_v2_conv = _DCNv2.apply
class DCNv2(nn.Module):
def __init__(self, in_channels, out_channels,
kernel_size, stride, padding, dilation=1, deformable_groups=1):
super(DCNv2, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = _pair(kernel_size)
self.stride = _pair(stride)
self.padding = _pair(padding)
self.dilation = _pair(dilation)
self.deformable_groups = deformable_groups
self.weight = nn.Parameter(torch.Tensor(
out_channels, in_channels, *self.kernel_size))
self.bias = nn.Parameter(torch.Tensor(out_channels))
self.reset_parameters()
def reset_parameters(self):
n = self.in_channels
for k in self.kernel_size:
n *= k
stdv = 1. / math.sqrt(n)
self.weight.data.uniform_(-stdv, stdv)
self.bias.data.zero_()
def forward(self, input, offset, mask):
assert 2 * self.deformable_groups * self.kernel_size[0] * self.kernel_size[1] == \
offset.shape[1]
assert self.deformable_groups * self.kernel_size[0] * self.kernel_size[1] == \
mask.shape[1]
return dcn_v2_conv(input, offset, mask,
self.weight,
self.bias,
self.stride,
self.padding,
self.dilation,
self.deformable_groups)
class DCN(DCNv2):
def __init__(self, in_channels, out_channels,
kernel_size, stride, padding,
dilation=1, deformable_groups=1):
super(DCN, self).__init__(in_channels, out_channels,
kernel_size, stride, padding, dilation, deformable_groups)
channels_ = self.deformable_groups * 3 * self.kernel_size[0] * self.kernel_size[1]
self.conv_offset_mask = nn.Conv2d(self.in_channels,
channels_,
kernel_size=self.kernel_size,
stride=self.stride,
padding=self.padding,
bias=True)
self.init_offset()
def init_offset(self):
self.conv_offset_mask.weight.data.zero_()
self.conv_offset_mask.bias.data.zero_()
def forward(self, input):
out = self.conv_offset_mask(input)
o1, o2, mask = torch.chunk(out, 3, dim=1)
offset = torch.cat((o1, o2), dim=1)
mask = torch.sigmoid(mask)
return dcn_v2_conv(input, offset, mask,
self.weight, self.bias,
self.stride,
self.padding,
self.dilation,
self.deformable_groups)
class _DCNv2Pooling(Function):
@staticmethod
def forward(ctx, input, rois, offset,
spatial_scale,
pooled_size,
output_dim,
no_trans,
group_size=1,
part_size=None,
sample_per_part=4,
trans_std=.0):
ctx.spatial_scale = spatial_scale
ctx.no_trans = int(no_trans)
ctx.output_dim = output_dim
ctx.group_size = group_size
ctx.pooled_size = pooled_size
ctx.part_size = pooled_size if part_size is None else part_size
ctx.sample_per_part = sample_per_part
ctx.trans_std = trans_std
output, output_count = \
_backend.dcn_v2_psroi_pooling_forward(input, rois, offset,
ctx.no_trans, ctx.spatial_scale,
ctx.output_dim, ctx.group_size,
ctx.pooled_size, ctx.part_size,
ctx.sample_per_part, ctx.trans_std)
ctx.save_for_backward(input, rois, offset, output_count)
return output
@staticmethod
@once_differentiable
def backward(ctx, grad_output):
input, rois, offset, output_count = ctx.saved_tensors
grad_input, grad_offset = \
_backend.dcn_v2_psroi_pooling_backward(grad_output,
input,
rois,
offset,
output_count,
ctx.no_trans,
ctx.spatial_scale,
ctx.output_dim,
ctx.group_size,
ctx.pooled_size,
ctx.part_size,
ctx.sample_per_part,
ctx.trans_std)
return grad_input, None, grad_offset, \
None, None, None, None, None, None, None, None
dcn_v2_pooling = _DCNv2Pooling.apply
class DCNv2Pooling(nn.Module):
def __init__(self,
spatial_scale,
pooled_size,
output_dim,
no_trans,
group_size=1,
part_size=None,
sample_per_part=4,
trans_std=.0):
super(DCNv2Pooling, self).__init__()
self.spatial_scale = spatial_scale
self.pooled_size = pooled_size
self.output_dim = output_dim
self.no_trans = no_trans
self.group_size = group_size
self.part_size = pooled_size if part_size is None else part_size
self.sample_per_part = sample_per_part
self.trans_std = trans_std
def forward(self, input, rois, offset):
assert input.shape[1] == self.output_dim
if self.no_trans:
offset = input.new()
return dcn_v2_pooling(input, rois, offset,
self.spatial_scale,
self.pooled_size,
self.output_dim,
self.no_trans,
self.group_size,
self.part_size,
self.sample_per_part,
self.trans_std)
class DCNPooling(DCNv2Pooling):
def __init__(self,
spatial_scale,
pooled_size,
output_dim,
no_trans,
group_size=1,
part_size=None,
sample_per_part=4,
trans_std=.0,
deform_fc_dim=1024):
super(DCNPooling, self).__init__(spatial_scale,
pooled_size,
output_dim,
no_trans,
group_size,
part_size,
sample_per_part,
trans_std)
self.deform_fc_dim = deform_fc_dim
if not no_trans:
self.offset_mask_fc = nn.Sequential(
nn.Linear(self.pooled_size * self.pooled_size *
self.output_dim, self.deform_fc_dim),
nn.ReLU(inplace=True),
nn.Linear(self.deform_fc_dim, self.deform_fc_dim),
nn.ReLU(inplace=True),
nn.Linear(self.deform_fc_dim, self.pooled_size *
self.pooled_size * 3)
)
self.offset_mask_fc[4].weight.data.zero_()
self.offset_mask_fc[4].bias.data.zero_()
def forward(self, input, rois):
offset = input.new()
if not self.no_trans:
# do roi_align first
n = rois.shape[0]
roi = dcn_v2_pooling(input, rois, offset,
self.spatial_scale,
self.pooled_size,
self.output_dim,
True, # no trans
self.group_size,
self.part_size,
self.sample_per_part,
self.trans_std)
# build mask and offset
offset_mask = self.offset_mask_fc(roi.view(n, -1))
offset_mask = offset_mask.view(
n, 3, self.pooled_size, self.pooled_size)
o1, o2, mask = torch.chunk(offset_mask, 3, dim=1)
offset = torch.cat((o1, o2), dim=1)
mask = torch.sigmoid(mask)
# do pooling with offset and mask
return dcn_v2_pooling(input, rois, offset,
self.spatial_scale,
self.pooled_size,
self.output_dim,
self.no_trans,
self.group_size,
self.part_size,
self.sample_per_part,
self.trans_std) * mask
# only roi_align
return dcn_v2_pooling(input, rois, offset,
self.spatial_scale,
self.pooled_size,
self.output_dim,
self.no_trans,
self.group_size,
self.part_size,
self.sample_per_part,
self.trans_std)
pose_dla_dcn.py文件:
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import os
import math
import logging
import numpy as np
from os.path import join
import torch
from torch import nn
import torch.nn.functional as F
import torch.utils.model_zoo as model_zoo
from dcn_v2 import DCN
BN_MOMENTUM = 0.1
logger = logging.getLogger(__name__)
def get_model_url(data='imagenet', name='dla34', hash='ba72cf86'):
return join('http://dl.yf.io/dla/models', data, '{}-{}.pth'.format(name, hash))
def conv3x3(in_planes, out_planes, stride=1):
"3x3 convolution with padding"
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
class BasicBlock(nn.Module):
def __init__(self, inplanes, planes, stride=1, dilation=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=3,
stride=stride, padding=dilation,
bias=False, dilation=dilation)
self.bn1 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3,
stride=1, padding=dilation,
bias=False, dilation=dilation)
self.bn2 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.stride = stride
def forward(self, x, residual=None):
if residual is None:
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += residual
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 2
def __init__(self, inplanes, planes, stride=1, dilation=1):
super(Bottleneck, self).__init__()
expansion = Bottleneck.expansion
bottle_planes = planes // expansion
self.conv1 = nn.Conv2d(inplanes, bottle_planes,
kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(bottle_planes, momentum=BN_MOMENTUM)
self.conv2 = nn.Conv2d(bottle_planes, bottle_planes, kernel_size=3,
stride=stride, padding=dilation,
bias=False, dilation=dilation)
self.bn2 = nn.BatchNorm2d(bottle_planes, momentum=BN_MOMENTUM)
self.conv3 = nn.Conv2d(bottle_planes, planes,
kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=True)
self.stride = stride
def forward(self, x, residual=None):
if residual is None:
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += residual
out = self.relu(out)
return out
class BottleneckX(nn.Module):
expansion = 2
cardinality = 32
def __init__(self, inplanes, planes, stride=1, dilation=1):
super(BottleneckX, self).__init__()
cardinality = BottleneckX.cardinality
# dim = int(math.floor(planes * (BottleneckV5.expansion / 64.0)))
# bottle_planes = dim * cardinality
bottle_planes = planes * cardinality // 32
self.conv1 = nn.Conv2d(inplanes, bottle_planes,
kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(bottle_planes, momentum=BN_MOMENTUM)
self.conv2 = nn.Conv2d(bottle_planes, bottle_planes, kernel_size=3,
stride=stride, padding=dilation, bias=False,
dilation=dilation, groups=cardinality)
self.bn2 = nn.BatchNorm2d(bottle_planes, momentum=BN_MOMENTUM)
self.conv3 = nn.Conv2d(bottle_planes, planes,
kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=True)
self.stride = stride
def forward(self, x, residual=None):
if residual is None:
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += residual
out = self.relu(out)
return out
class Root(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, residual):
super(Root, self).__init__()
self.conv = nn.Conv2d(
in_channels, out_channels, 1,
stride=1, bias=False, padding=(kernel_size - 1) // 2)
self.bn = nn.BatchNorm2d(out_channels, momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=True)
self.residual = residual
def forward(self, *x):
children = x
x = self.conv(torch.cat(x, 1))
x = self.bn(x)
if self.residual:
x += children[0]
x = self.relu(x)
return x
class Tree(nn.Module):
def __init__(self, levels, block, in_channels, out_channels, stride=1,
level_root=False, root_dim=0, root_kernel_size=1,
dilation=1, root_residual=False):
super(Tree, self).__init__()
if root_dim == 0:
root_dim = 2 * out_channels
if level_root:
root_dim += in_channels
if levels == 1:
self.tree1 = block(in_channels, out_channels, stride,
dilation=dilation)
self.tree2 = block(out_channels, out_channels, 1,
dilation=dilation)
else:
self.tree1 = Tree(levels - 1, block, in_channels, out_channels,
stride, root_dim=0,
root_kernel_size=root_kernel_size,
dilation=dilation, root_residual=root_residual)
self.tree2 = Tree(levels - 1, block, out_channels, out_channels,
root_dim=root_dim + out_channels,
root_kernel_size=root_kernel_size,
dilation=dilation, root_residual=root_residual)
if levels == 1:
self.root = Root(root_dim, out_channels, root_kernel_size,
root_residual)
self.level_root = level_root
self.root_dim = root_dim
self.downsample = None
self.project = None
self.levels = levels
if stride > 1:
self.downsample = nn.MaxPool2d(stride, stride=stride)
if in_channels != out_channels:
self.project = nn.Sequential(
nn.Conv2d(in_channels, out_channels,
kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(out_channels, momentum=BN_MOMENTUM)
)
def forward(self, x, residual=None, children=None):
children = [] if children is None else children
bottom = self.downsample(x) if self.downsample else x
residual = self.project(bottom) if self.project else bottom
if self.level_root:
children.append(bottom)
x1 = self.tree1(x, residual)
if self.levels == 1:
x2 = self.tree2(x1)
x = self.root(x2, x1, *children)
else:
children.append(x1)
x = self.tree2(x1, children=children)
return x
class DLA(nn.Module):
def __init__(self, levels, channels, num_classes=1000,
block=BasicBlock, residual_root=False, linear_root=False):
super(DLA, self).__init__()
self.channels = channels
self.num_classes = num_classes
self.base_layer = nn.Sequential(
nn.Conv2d(3, channels[0], kernel_size=7, stride=1,
padding=3, bias=False),
nn.BatchNorm2d(channels[0], momentum=BN_MOMENTUM),
nn.ReLU(inplace=True))
self.level0 = self._make_conv_level(
channels[0], channels[0], levels[0])
self.level1 = self._make_conv_level(
channels[0], channels[1], levels[1], stride=2)
self.level2 = Tree(levels[2], block, channels[1], channels[2], 2,
level_root=False,
root_residual=residual_root)
self.level3 = Tree(levels[3], block, channels[2], channels[3], 2,
level_root=True, root_residual=residual_root)
self.level4 = Tree(levels[4], block, channels[3], channels[4], 2,
level_root=True, root_residual=residual_root)
self.level5 = Tree(levels[5], block, channels[4], channels[5], 2,
level_root=True, root_residual=residual_root)
# for m in self.modules():
# if isinstance(m, nn.Conv2d):
# n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
# m.weight.data.normal_(0, math.sqrt(2. / n))
# elif isinstance(m, nn.BatchNorm2d):
# m.weight.data.fill_(1)
# m.bias.data.zero_()
def _make_level(self, block, inplanes, planes, blocks, stride=1):
downsample = None
if stride != 1 or inplanes != planes:
downsample = nn.Sequential(
nn.MaxPool2d(stride, stride=stride),
nn.Conv2d(inplanes, planes,
kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(planes, momentum=BN_MOMENTUM),
)
layers = []
layers.append(block(inplanes, planes, stride, downsample=downsample))
for i in range(1, blocks):
layers.append(block(inplanes, planes))
return nn.Sequential(*layers)
def _make_conv_level(self, inplanes, planes, convs, stride=1, dilation=1):
modules = []
for i in range(convs):
modules.extend([
nn.Conv2d(inplanes, planes, kernel_size=3,
stride=stride if i == 0 else 1,
padding=dilation, bias=False, dilation=dilation),
nn.BatchNorm2d(planes, momentum=BN_MOMENTUM),
nn.ReLU(inplace=True)])
inplanes = planes
return nn.Sequential(*modules)
def forward(self, x):
y = []
x = self.base_layer(x)
for i in range(6):
x = getattr(self, 'level{}'.format(i))(x)
y.append(x)
return y
def load_pretrained_model(self, data='imagenet', name='dla34', hash='ba72cf86'):
# fc = self.fc
if name.endswith('.pth'):
model_weights = torch.load(data + name)
else:
model_url = get_model_url(data, name, hash)
model_weights = model_zoo.load_url(model_url)
num_classes = len(model_weights[list(model_weights.keys())[-1]])
self.fc = nn.Conv2d(
self.channels[-1], num_classes,
kernel_size=1, stride=1, padding=0, bias=True)
self.load_state_dict(model_weights)
# self.fc = fc
def dla34(pretrained=True, **kwargs): # DLA-34
model = DLA([1, 1, 1, 2, 2, 1],
[16, 32, 64, 128, 256, 512],
block=BasicBlock, **kwargs)
#if pretrained:
# model.load_pretrained_model(data='imagenet', name='dla34', hash='ba72cf86')
return model
class Identity(nn.Module):
def __init__(self):
super(Identity, self).__init__()
def forward(self, x):
return x
def fill_fc_weights(layers):
for m in layers.modules():
if isinstance(m, nn.Conv2d):
if m.bias is not None:
nn.init.constant_(m.bias, 0)
def fill_up_weights(up):
w = up.weight.data
f = math.ceil(w.size(2) / 2)
c = (2 * f - 1 - f % 2) / (2. * f)
for i in range(w.size(2)):
for j in range(w.size(3)):
w[0, 0, i, j] = \
(1 - math.fabs(i / f - c)) * (1 - math.fabs(j / f - c))
for c in range(1, w.size(0)):
w[c, 0, :, :] = w[0, 0, :, :]
class DeformConv(nn.Module):
def __init__(self, chi, cho):
super(DeformConv, self).__init__()
self.actf = nn.Sequential(
nn.BatchNorm2d(cho, momentum=BN_MOMENTUM),
nn.ReLU(inplace=True)
)
self.conv = DCN(chi, cho, kernel_size=(3,3), stride=1, padding=1, dilation=1, deformable_groups=1)
def forward(self, x):
x = self.conv(x)
x = self.actf(x)
return x
class IDAUp(nn.Module):
def __init__(self, o, channels, up_f):
super(IDAUp, self).__init__()
for i in range(1, len(channels)):
c = channels[i]
f = int(up_f[i])
proj = DeformConv(c, o)
node = DeformConv(o, o)
up = nn.ConvTranspose2d(o, o, f * 2, stride=f,
padding=f // 2, output_padding=0,
groups=o, bias=False)
fill_up_weights(up)
setattr(self, 'proj_' + str(i), proj)
setattr(self, 'up_' + str(i), up)
setattr(self, 'node_' + str(i), node)
def forward(self, layers, startp, endp):
for i in range(startp + 1, endp):
upsample = getattr(self, 'up_' + str(i - startp))
project = getattr(self, 'proj_' + str(i - startp))
layers[i] = upsample(project(layers[i]))
node = getattr(self, 'node_' + str(i - startp))
layers[i] = node(layers[i] + layers[i - 1])
class DLAUp(nn.Module):
def __init__(self, startp, channels, scales, in_channels=None):
super(DLAUp, self).__init__()
self.startp = startp
if in_channels is None:
in_channels = channels
self.channels = channels
channels = list(channels)
scales = np.array(scales, dtype=int)
for i in range(len(channels) - 1):
j = -i - 2
setattr(self, 'ida_{}'.format(i),
IDAUp(channels[j], in_channels[j:],
scales[j:] // scales[j]))
scales[j + 1:] = scales[j]
in_channels[j + 1:] = [channels[j] for _ in channels[j + 1:]]
def forward(self, layers):
out = [layers[-1]] # start with 32
for i in range(len(layers) - self.startp - 1):
ida = getattr(self, 'ida_{}'.format(i))
ida(layers, len(layers) -i - 2, len(layers))
out.insert(0, layers[-1])
return out
class Interpolate(nn.Module):
def __init__(self, scale, mode):
super(Interpolate, self).__init__()
self.scale = scale
self.mode = mode
def forward(self, x):
x = F.interpolate(x, scale_factor=self.scale, mode=self.mode, align_corners=False)
return x
class DLASeg(nn.Module):
def __init__(self, base_name, heads, pretrained, down_ratio, final_kernel,
last_level, head_conv, out_channel=0):
super(DLASeg, self).__init__()
assert down_ratio in [2, 4, 8, 16]
self.first_level = int(np.log2(down_ratio))
self.last_level = last_level
self.base = globals()[base_name](pretrained=pretrained)
channels = self.base.channels
scales = [2 ** i for i in range(len(channels[self.first_level:]))]
self.dla_up = DLAUp(self.first_level, channels[self.first_level:], scales)
if out_channel == 0:
out_channel = channels[self.first_level]
self.ida_up = IDAUp(out_channel, channels[self.first_level:self.last_level],
[2 ** i for i in range(self.last_level - self.first_level)])
self.heads = heads
for head in self.heads:
classes = self.heads[head]
if head_conv > 0:
fc = nn.Sequential(
nn.Conv2d(channels[self.first_level], head_conv,
kernel_size=3, padding=1, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(head_conv, classes,
kernel_size=final_kernel, stride=1,
padding=final_kernel // 2, bias=True))
if 'hm' in head:
fc[-1].bias.data.fill_(-2.19)
else:
fill_fc_weights(fc)
else:
fc = nn.Conv2d(channels[self.first_level], classes,
kernel_size=final_kernel, stride=1,
padding=final_kernel // 2, bias=True)
if 'hm' in head:
fc.bias.data.fill_(-2.19)
else:
fill_fc_weights(fc)
self.__setattr__(head, fc)
def forward(self, x):
x = self.base(x)
x = self.dla_up(x)
y = []
for i in range(self.last_level - self.first_level):
y.append(x[i].clone())
self.ida_up(y, 0, len(y))
z = {}
for head in self.heads:
z[head] = self.__getattr__(head)(y[-1])
# return [z] xiehao
return z
def get_pose_net(num_layers, heads, head_conv=256, down_ratio=4):
model = DLASeg('dla{}'.format(num_layers), heads,
pretrained=True,
down_ratio=down_ratio,
final_kernel=1,
last_level=5,
head_conv=head_conv)
return model
测试剪枝主流程的centerNet_prune文件
from nni.compression.pytorch.pruning import L1NormPruner
from nni.compression.pytorch.speedup import ModelSpeedup
import pose_dla_dcn
import torch
num_layers = 34
heads = {'hm': 2, 'wh': 2, 'reg': 2}
config_list = [{
'sparsity': 0.5,
'op_types': ['Conv2d']
}]
model = pose_dla_dcn.get_pose_net(num_layers, heads)
torch.save(model.state_dict(), "baseline.pth")
# model.cuda()
# model(torch.rand(1, 3, 512, 512).cuda()) # 512严格要求
print("--------------raw model--------------")
print(model)
pruner = L1NormPruner(model, config_list, mode='dependency_aware', dummy_input=torch.rand(1, 3, 512, 512))
print("--------------pruned model--------------")
print(model)
# compress the model and generate the masks
_, masks = pruner.compress()
# show the masks sparsity
for name, mask in masks.items():
print(name, ' sparsity: ', '{:.2f}'.format(mask['weight'].sum() / mask['weight'].numel()))
# need to unwarp the model, if the model is wrawpped before speedup
pruner._unwrap_model()
# speedup the model
model.eval()
ModelSpeedup(model, dummy_input=torch.rand(1, 3, 512, 512), masks_file=masks).speedup_model()
print("--------------after sppedup--------------")
print(model)
torch.save(model, "model_pruner.pth")最后一个文件有一个注意点,就是dummy_input输入一定是[batch, 3, 512, 512]的形式,否则卷积池化后残差连接会有问题,会出现[batch, 128, 3, 3] 和[batch, 128, 2, 2]相加的情况。
执行后报错,出错信息为:
self.output = self.module(*dummy_input)
File "D:\programs\python37\lib\site-packages\torch\nn\modules\module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
TypeError: forward() missing 1 required positional argument: 'input'
[2022-11-18 19:15:08] start to speedup the model
D:\programs\python37\lib\site-packages\nni\compression\pytorch\utils\mask_conflict.py:124: UserWarning: This overload of nonzero is deprecated:
nonzero()
Consider using one of the following signatures instead:
nonzero(*, bool as_tuple) (Triggered internally at ..\torch\csrc\utils\python_arg_parser.cpp:882.)
all_ones = (w_mask.flatten(1).sum(-1) == count).nonzero().squeeze(1).tolist()
both dim0 and dim1 masks found.
[2022-11-18 19:18:01] infer module masks...
[2022-11-18 19:18:01] Update mask for base.base_layer.0
[2022-11-18 19:18:03] Update mask for dla_up.ida_0.proj_1.actf.0
Traceback (most recent call last):
File "D:/workspace/newczalgo/CenterNet_3DCar_Slimming/src/centernet_prune/centernet_prune.py", line 34, in
ModelSpeedup(model, torch.rand(1, 3, 512, 512), masks).speedup_model()
File "D:\programs\python37\lib\site-packages\nni\compression\pytorch\speedup\compressor.py", line 536, in speedup_model
self.infer_modules_masks()
File "D:\programs\python37\lib\site-packages\nni\compression\pytorch\speedup\compressor.py", line 371, in infer_modules_masks
self.update_direct_sparsity(curnode)
File "D:\programs\python37\lib\site-packages\nni\compression\pytorch\speedup\compressor.py", line 240, in update_direct_sparsity
state_dict=copy.deepcopy(module.state_dict()), batch_dim=self.batch_dim)
File "D:\programs\python37\lib\site-packages\nni\compression\pytorch\speedup\infer_mask.py", line 80, in __init__
self.output = self.module(*dummy_input)
File "D:\programs\python37\lib\site-packages\torch\nn\modules\module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
TypeError: forward() missing 1 required positional argument: 'input'
Process finished with exit code 1 nni的github上有对应的issue:
Meet a dropout missing argument problem when speed up the model and update mask for my own model · Issue #4297 · microsoft/nni · GitHub
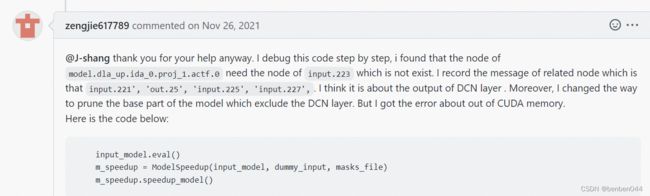 主要是DCN的输出为empy,导致dummy_input的list为空的。
主要是DCN的输出为empy,导致dummy_input的list为空的。
尝试方法一:
网上说把有问题的层信息加入config_list的exclude中,比如:
config_list = [{
'sparsity': 0.5,
'op_types': ['Conv2d']
},
{'exclude': True, 'op_names': ['conv_offset_mask']}
]op_names换成:
dla_up.ida_0.proj_1.actf.0 或 dla_up.ida_0.proj_1.conv.conv_offset_mask或dla_up等都失败,报错信息还是一样的。
尝试方法二:
在compress中当dumpy_input为空时直接return,如下所示:
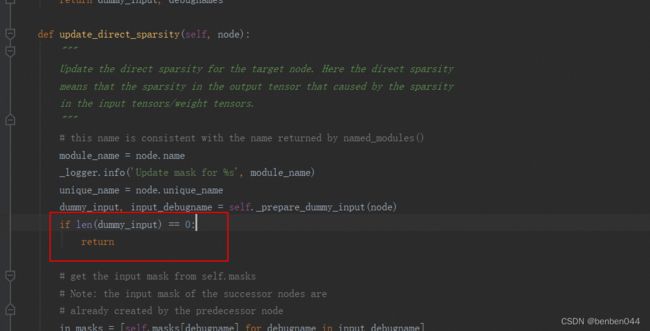
此时又会出现新的bug:
[2022-11-18 21:43:10] Update mask for dla_up.ida_2.aten::add.233
Traceback (most recent call last):
File "D:/workspace/newczalgo/CenterNet_3DCar_Slimming/src/centernet_prune/centernet_prune.py", line 38, in
ModelSpeedup(model, dummy_input=torch.rand(1, 3, 512, 512), masks_file=masks).speedup_model()
File "D:\programs\python37\lib\site-packages\nni\compression\pytorch\speedup\compressor.py", line 539, in speedup_model
self.infer_modules_masks()
File "D:\programs\python37\lib\site-packages\nni\compression\pytorch\speedup\compressor.py", line 374, in infer_modules_masks
self.update_direct_sparsity(curnode)
File "D:\programs\python37\lib\site-packages\nni\compression\pytorch\speedup\compressor.py", line 235, in update_direct_sparsity
func, dummy_input, in_masks, in_constants=in_constants, batch_dim=self.batch_dim)
File "D:\programs\python37\lib\site-packages\nni\compression\pytorch\speedup\infer_mask.py", line 80, in __init__
self.output = self.module(*dummy_input)
TypeError: add() received an invalid combination of arguments - got (Tensor), but expected (Tensor input, Tensor other, *, Number alpha, Tensor out) 结论:DLASeg使用NNI进行剪枝挑战失败!!