3D目标检测
一、综述
1.1概述:
3D目标检测目前主要的应用场景就是自动驾驶,自动驾驶车不仅仅需要识别障碍物的类型,还需要识别物体的精确位置和朝向。以提供信息给规划控制模块,规划出合理的线路。3D目标检测旨在通过多传感器数据如LIDAR、Camera、RADAR等,使得自动驾驶车辆具备检测车辆、行人、障碍物等物体的能力,保障行驶安全,是自动驾驶领域要解决的核心问题之一。
普通2D目标检测并不能提供感知环境所需要的全部信息,仅能提供目标物体在二维图片中的位置和对应类别的置信度,而3D目标检测结合了深度信息,能够提供目标的位置、方向和大小等空间场景信息,这些对于后续自动驾驶场景中的路径规划和控制至关重要。
3D目标检测方法无外乎以下几种。
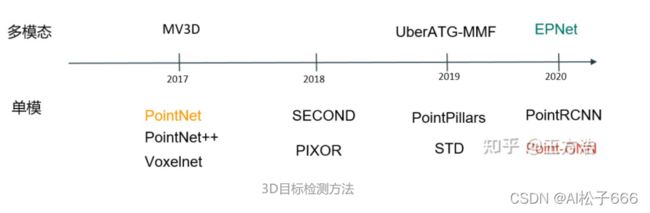
根据输入类型(传感器种类)来划分,目前3D目标检测的方法分为:
单模(Lidar、Camera)
多模(Lidar+Camera、Radar+Camera)
根据特征提取的方法来划分,主要分为以下4种。
Point Clouds - 基于原始点进行特征提取
Voxel - 把点云划分成一个个的网格,然后提取网格的特征
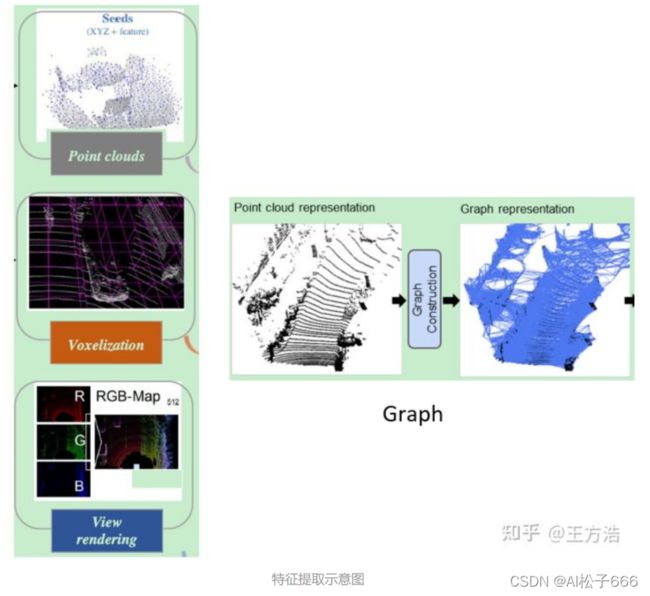
Graph - 利用图的方式,对半径R内的点建立图,然后提取特征
2D View - 把3D投影到2D平面,大部分采用BEV视角,然后用2D卷积提取特征
下图分别描述了上述4种特征提取方式。
1.2资源
可使用的3D目标检测开源代码:
- https://github.com/open-mmlab/mmdetection3d(点云和图像都支持的开源框架工具箱)
2.https://github.com/open-mmlab/OpenPCDet(专注做点云3D目标检测的开源框架工具箱)
3.https://github.com/poodarchu/Det3D(PyTorch中的一个通用3D对象检测代码库)
4.https://github.com/tianweiy/CenterPoint(centerpoint算法源码)
1.3结果形式:
目标检测任务并不需要重构物体完整的3D形状,仅仅确定3D边框即可, 理论上,一个3D bounding box有9个自由度,3个是位置,3个是旋转,3个是维度大小。对于自动驾驶场景下的物体,绝大多数都是水平放置于地面,所以通过假设物体都放置于水平地面,可以设置滚动和倾斜角度相对于水平面为零,这样就可以省略掉2个自由度,还有7个自由度,所以3D目标检测也是一个目标物体7D pose预测问题。一般的3Dbox的定义是: (x, y, z, dx, dy, dz, heading).
3D目标检测的评价标准跟2D目标检测一致,都是计算目标的IOU,统计检测的ap值。
二、相关数据集:
3D目标检测的数据集主要包含Jura、Pascal3D+、LINEMOD、 ScanNet、SUNRGB-D、Waymo、 nuScenes、 KITTI、百度ApolloScape和Udacity等数据集。自动驾驶场景Waymo、 nuScenes、 KITTI三个数据集使用最多。

三、算法方法:
自从2017年以来3D目标检测涌现出了很多经典算法,下面整理了一些算法的时间线。
3.1、Voxelnet
2017年 CVPR Apple公司提出的基于voxel的特征提取方法,算是第一篇只用点云去做3D检测的文章。
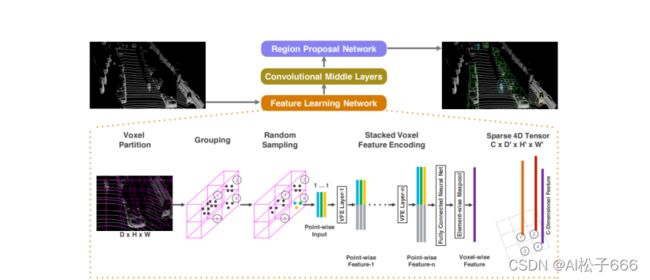
对点云进行网格化,得到规则的特征,然后进行3D卷积。
3.2、PointNet++
2017年 CVPR 是PointNet的改进,基于原始点提取特征。
首先要先介绍下PointNet结构,如下:
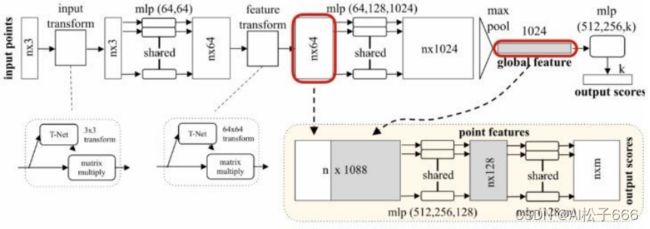
PointNet++的改进:frustum pointnet视锥体点网
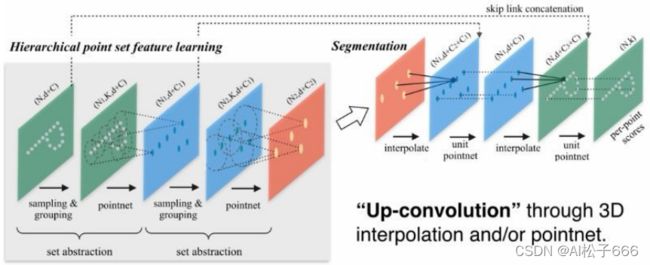
采样算法是最远点采样(farthest point sampling, FPS),相对于随机采样,这种采样算法能够更好地覆盖整个采样空间。
点云数据中的一个点的局部由其周围给定半径的球形空间内的其他点构成。
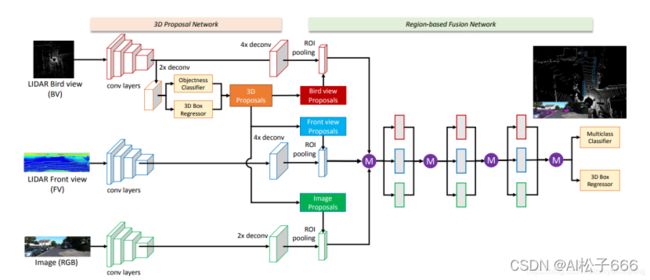
3.3、MV3D
2017年 CVPR - 百度和清华提出,3D投影到2D平面,多模态融合了Lidar和Camera数据
3.4、PIXOR
2018年CVPR Uber one-stage, Lidar only
为什么要把PIXOR单独拿出来,因为PIXOR和MV3D都是采用把3D视图投影到2D视图的方法,而PIXOR只采用了BEV视角的特征,效果却比MV3D还要好,所以证明BEV视角非常关键。

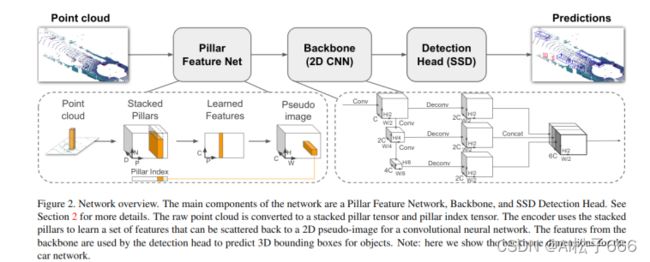
3.5、PointPillars
2019年 CVPR Aptiv
新的点云编码方式,是对SECOND方法的改进。
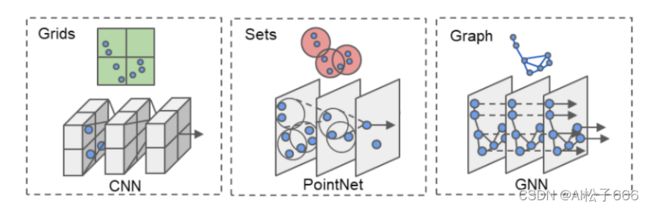
3.6、Point-GNN
2020年 CVPR - Carnegie Mellon University
引入了图神经网络对点云3D特征进行提取
首先论文介绍了3D特征提取的3种方式:投影到2D,聚类点集、图
四、算法实验结果:
1.基于KITTI 数据集
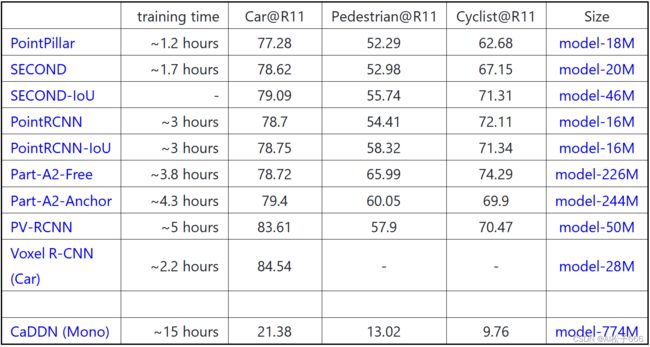
2.基于Waymo 数据集(计算mAP/mAPH)
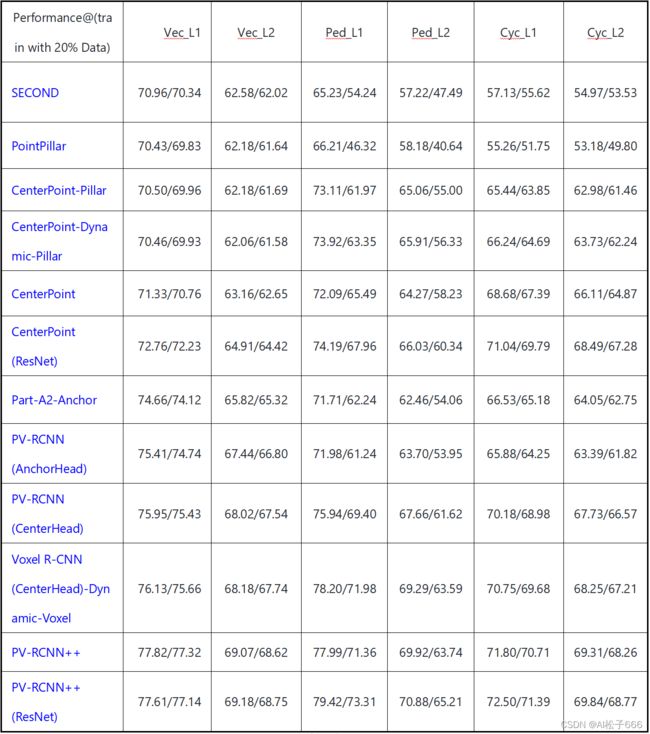
从基于Waymo 数据集的测试结果来看,一阶段的centerpoint(ResNet)网络比较好,二阶段的PV-RCNN++效果最好,PointPillar,没有什么特殊算子,足够简单方便部署,可魔改性还强,兼顾了速度和精度,又容易部署。
![]()