【论文阅读】【三维目标检测】Multi-Task Multi-Sensor Fusion for 3D Object Detection
目录
- 网络
-
- 点云分支
- 图像分支
- Point-wise Fusion
- 3D box estimation & RoI Crop
- Depth Completion分支
- Loss
- 实验
文章 Multi-Task Multi-Sensor Fusion for 3D Object Detection
2019CVPR
该文章使用了相机和激光雷达传感器融合方法检测3D Object,使用了一个网络解决多任务,并且多个子任务是为了3D Object Detection服务的。
网络
网络结构图如下,主要完成Ground Estimation,Depth Completion和3D Object Detection的问题。
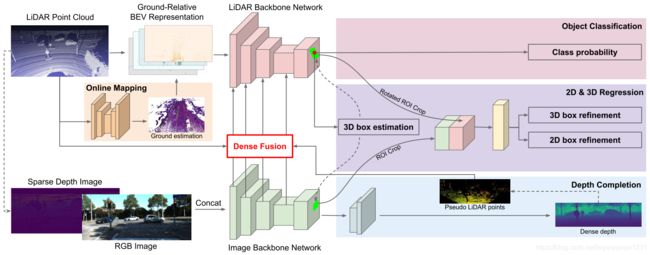
点云分支
该分支的输入为栅格化后的点云,也就是一个 b a t c h × c h a n n e l × w × l × h batch \times channel \times w \times l \times h batch×channel×w×l×h的一个Tensor,然后将其高度与channel数合并之后,认为得到BEV俯视图,就可以把这个Tensor变为一个4维Tensor,就可以用处理图像的CNN进行处理。文章中提到:
“We consider the resulting 3D volume as BEV representation by treating the height slices as feature channels. This allows us to reason in 2D BEV space, which brings significant efficiency gain with no performance drop.”
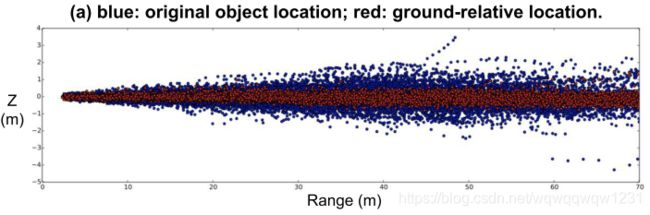
在BEV表示的点云后加入U-net,做Ground Estimation,得到俯视图中的路面高度,然后使用路面高度与真实的点云做差,得到每个点相对于路面的高度。就可以认为这样做是减去了路面高度的起伏对3D Object Detection的影响。这个思想在HDNet中已经出现过了。结果如下图,可以看到,确实这个过程是将物体的位置更拉向高度为0处,从而减少学习的难度。在实验中也验证了这个模块的有效性。
然后使用ResNet的结构对栅格化的点云进行特征提取,只不过相比于ResNet-18,点云处理的网络更深但更瘦。(深可以理解,但瘦是指什么?)
图像分支
由点云投影到图像平面,得到Sparse Depth Image,与RGB Image共同输入图像的特征提取网络,这个网络使用ResNet-18。点云和图像的特征提取的网络的输出均为输入大小的 0.25 × 0.25 0.25 \times 0.25 0.25×0.25。
Point-wise Fusion
原文中提到:
“For each pixel in the BEV feature map, we find its nearest LiDAR point and project the point onto the image feature map to retrieve the corresponding image feature. We compute the distance between the BEV pixel and LiDAR point as the geometric feature. Both retrieved image feature and the BEV geometric feature are passed into a Multi-Layer Perceptron (MLP) and the output is fused to BEV feature map by element-wise addition.”
相比于论文作者之前的成果(2018ECCV,图的解释如下),本文中只使用最近点,而不是KNN方法寻找多个点,但这两者之间的差别,本文也没有多做对比实验。

文中把融合后的feature加到了point cloud的feature上。
3D box estimation & RoI Crop
可以认为右上角的classification也是输入box estimation的一部分,这一部分对应着的是传统two-stage模型的RPN,文中提这个object detection使用1x1的卷积核进行,分类就给预测的box一个label,判断其是否是前景。
在BEV预测了box之后,就需要提取box之内的特征了。这个特征分为两部分:
- 一部分来自于image的feature,使用RoI Align的方法
- 一部分来自于BEV,其实也是RoI Align的方法。只不过,文中提到来自于BEV中的feature需要考虑两个问题:第一问题如下:
“First, the periodicity of the ROI orientation causes the reverse of fea- ture order around the cycle boundary. To solve this issue, we propose an oriented ROI feature extraction module with anchors. Given an oriented ROI, we first assign it to one of the two orientation anchors, 0 or 90 degrees. Each anchor has a consistent feature extraction order. The two anchors share the refinement net except for the output layer.”
但我认为这个不算是问题,因为在预测box的时候是有方向的,也就是车辆朝向是固定的,是否转180度是可以判断的。作者也没有再详细说明ROI feature extraction module,只是提了以固定的顺序进行特征提取。那么第二个问题就是不同于传统的RoI Align中,RoI是与feature map不平行的,所以需要一个旋转。
得到两种特征之后,进行concatenation操作,得到RoI wise的Fusion。
Depth Completion分支
使用图像得到的feature map,使用bilinear up-sampling和convolution层进行预测深度图像,从而可以得到稠密的深度信息,以补充点云稀疏的深度信息。这种稠密的深度信息可以转化为稠密的伪点云,从而进行Point-wise fusion。文中只是提到,当找不到真实点云的点,则使用伪点云的点。但文中也没有再具体介绍这部分的详细操作。
我猜是在Point-wise fusion的过程中,是要对每个BEV中的pixel寻找最近的激光雷达点,可能这个寻找是有一定范围的,由经验给出,或者是这个激光雷达点得在BEV这个pixel内。如果没有激光雷达点,则使用伪点云中的点。
Loss
loss的部分文中已经将的很清楚。
实验
本文分别在KITTI和TOR4D上做了测试,证明了该方法的有效性。
并在KITTI上做了 Ablation Study,证明了多任务的有效性。但Depth Completion在KITTI上提升不明显,在TOR4D上对于Car这类的提升到了5%。文中给的解释是KITTI的图像和雷达中的车辆的分辨率差不多,所以伪点云提升不大,但在TOR4D中Image的分辨率明显高,伪点云来自于image,所以变得更有效。
We hypothesize that this is because in KITTI the captured image is at equivalent resolution of LiDAR at long range (as shown in Figure 5 b). Therefore, there isn’t much juice to squeeze from image feature. However, on TOR4D benchmark where we have higher resolution camera images, we show in next section that depth completion helps not only by multi-task learning, but also dense feature fusion.