YOLO v5学习记录
文章目录
-
- 下载yolov5
- 安装环境
- 下载数据集
- 运行程序进行预测
下载yolov5
YOLOv5-github
YOLOv5-官网
下载zip,解压:
安装环境
- 在该目录路径输入cmd:

- 或者在pycharm打开该目录,进入terminal即可
- 输入命令:
conda create -n yolov5-master python=3.8
-
*yolo要求python>=3.6、yolov5-master是环境的名字
-
*conda命令合集:
conda --version:查看Conda版本
conda -h:查看帮助文件
conda create -n env_name python=3.x:创建自己的环境env_name, 使用版本为3.x的Python
conda acitvate env_name :激活env_name作为当前环境
conda install pckg:为当前环境安装某个包
conda list:查看当前环境装了哪些包
conda update pckg:升级当前环境中的指定包pckg
conda remove pckg:删除当前环境中的指定包pckg
conda deactivate env_name:退出当前环境
conda create -n env_name --clone other_env_name:克隆某一环境
conda remove -n env_name --all:删除某一环境
conda env list:查看所有环境
conda install --name env_name pckg:为某一环境安装某个包
conda remove -n env_name pckg:从某一环境中移除pckg
- 输入:
conda activate yolov5-master
- 进入创建好的环境

- 输入命令:
pip install -r requirements.txt
-
*-r Install from the given requirements file. This option can be used multiple times. 即可根据requirements文件多次调用install命令。
-
YOLOv5环境需要用到的命令:
# pip install -r requirements.txt
# Base ----------------------------------------
matplotlib>=3.2.2
numpy>=1.18.5
opencv-python>=4.1.2
Pillow>=7.1.2
PyYAML>=5.3.1
requests>=2.23.0
scipy>=1.4.1
torch>=1.7.0
torchvision>=0.8.1
tqdm>=4.41.0
# Logging -------------------------------------
tensorboard>=2.4.1
# wandb
# Plotting ------------------------------------
pandas>=1.1.4
seaborn>=0.11.0
# Export --------------------------------------
# coremltools>=4.1 # CoreML export
# onnx>=1.9.0 # ONNX export
# onnx-simplifier>=0.3.6 # ONNX simplifier
# scikit-learn==0.19.2 # CoreML quantization
# tensorflow>=2.4.1 # TFLite export
# tensorflowjs>=3.9.0 # TF.js export
# Extras --------------------------------------
# albumentations>=1.0.3
# Cython # for pycocotools https://github.com/cocodataset/cocoapi/issues/172
# pycocotools>=2.0 # COCO mAP
# roboflow
thop # FLOPs computation
下载数据集
数据集地址
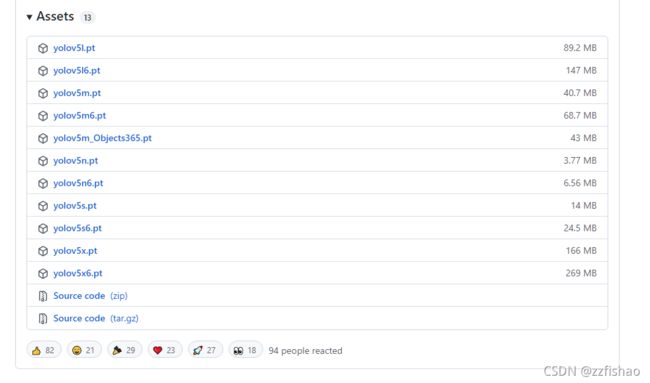
- 这里的.pt后缀的就是需要下载的数据集,准确来说他不叫数据集,叫Pretrained Checkpoints(预训练检查点),他是用数据集所训练出来的一种文件,yolo算法识别这个检查点就可以使用该训练集所训练出来的模型进行图像识别。
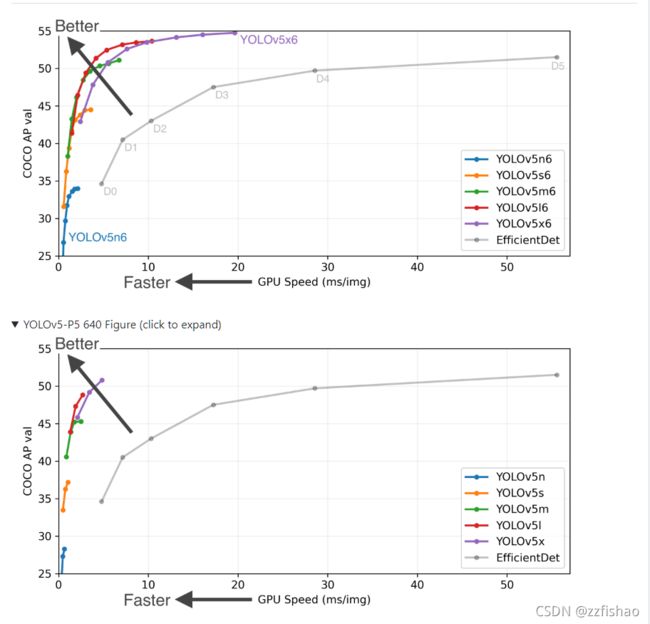
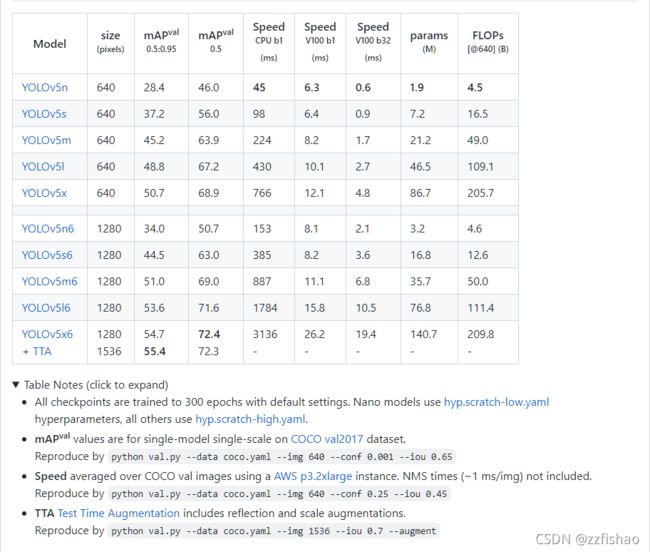
- 越大的数据集预测的效果相对来说更好一点,且相对来说对设备的要求会更高一点,以下是不同数据集的性能指标对比。
- 将下载好的pt文件放入yolo的根目录下,之后点击detect.py文件
运行程序进行预测
- 预测函数主要参数:需要注意的有weights需要修改为下载好的训练集,source图片路径,需要的时候可以更改置信阈值进行调参。
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model path(s)') # 选择训练集pt文件
parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob, 0 for webcam') # 需要预测的图片路径
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w') # 图片的尺寸
parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold') # 置信阈值,即当置信度大于0.25时显示框框
parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image') # 每张图片最大检测数目
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='show results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--visualize', action='store_true', help='visualize features')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name') # 输出路径
parser.add_argument('--name', default='exp', help='save results to project/name') # 输出name
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
opt = parser.parse_args()
opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
print_args(FILE.stem, opt)
return opt
- 调好之后运行代码,由于没来及调cuda,我是用cpu跑的,分别用了yolov5m和yolov5s两种数据集跑的样张,运行结果如下:
yolov5s:
C:\Users\hp.conda\envs\yolov5-master\python.exe F:/python/yolov5-master/yolov5-master/detect.py
detect: weights=yolov5s.pt, source=data\images, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs\detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False
YOLOv5 2021-11-16 torch 1.10.0+cpu CPU
Fusing layers…
Model Summary: 213 layers, 7225885 parameters, 0 gradients
image 1/2 F:\python\yolov5-master\yolov5-master\data\images\bus.jpg: 640x480 4 persons, 1 bus, Done. (0.290s)
image 2/2 F:\python\yolov5-master\yolov5-master\data\images\zidane.jpg: 384x640 2 persons, 1 tie, Done. (0.223s)
Speed: 1.0ms pre-process, 256.6ms inference, 2.1ms NMS per image at shape (1, 3, 640, 640)
Results saved to runs\detect\exp2
Process finished with exit code 0
yolov5m:
C:\Users\hp.conda\envs\yolov5-master\python.exe F:/python/yolov5-master/yolov5-master/detect.py
detect: weights=yolov5m.pt, source=data\images, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs\detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False
YOLOv5 2021-11-16 torch 1.10.0+cpu CPU
Fusing layers…
Model Summary: 290 layers, 21172173 parameters, 0 gradients
image 1/2 F:\python\yolov5-master\yolov5-master\data\images\bus.jpg: 640x480 4 persons, 1 bus, Done. (0.518s)
image 2/2 F:\python\yolov5-master\yolov5-master\data\images\zidane.jpg: 384x640 3 persons, 2 ties, Done. (0.435s)
Speed: 1.0ms pre-process, 476.5ms inference, 2.0ms NMS per image at shape (1, 3, 640, 640)
Results saved to runs\detect\exp4
Process finished with exit code 0
- 可以看出来数据集越large,运行速度越慢。
- 原图片:


- 使用yolov5s预测:


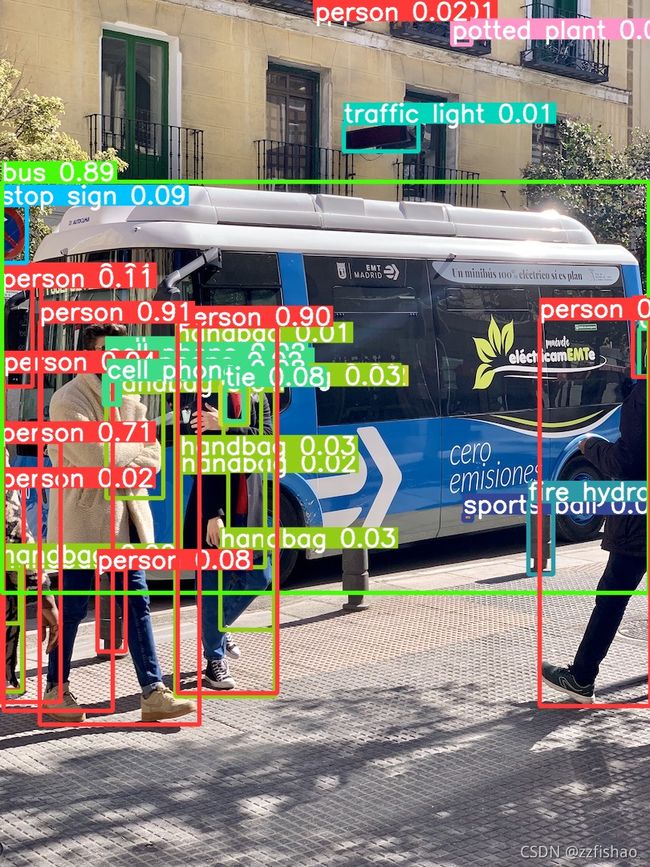
- 使用yolov5m预测:
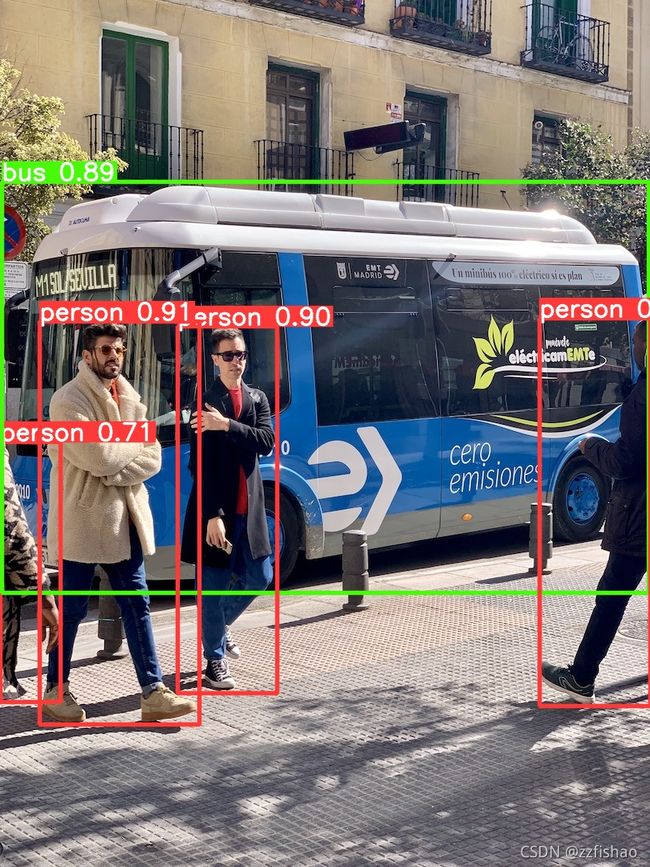

- 可以看出,更大的数据集所预测的结果置信度更接近于真实值,甚至在第二张图片中多识别了一条领带和一个人。
- 如果我们使用middle数据集将置信阈值调为0.01,识别情况将杂乱无章,所以选择一个好的置信阈值也是提高识别准确率的一个很关键的因素。
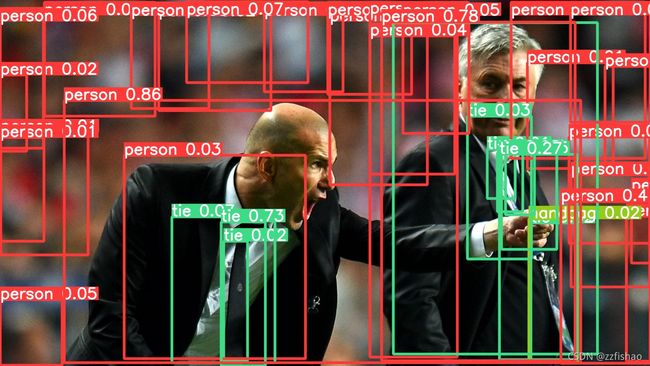
- 随后附上如何训练自定义训练集和如何获取数据以及对数据的标注。