YOLO-V4 Pytorch版本训练自建数据集和预测
1. 程序下载
本文程序核心部分完全参考开源代码:https://github.com/WongKinYiu/PyTorch_YOLOv4 。
只是从一种学习的角度去写了我的代码仓库,在基础上增加了一些常用的脚本(会持续更新)。
我的仓库地址为:https://github.com/hx-0614/yolov4-pytorch-learing
git clone https://github.com/hx-0614/yolov4-pytorch-learing.git
其中我新增的脚本文件,会在README.md文件中说明。代码结构如下(红色框内为我想对于原作者代码更改或者新增的脚本文件,核心代码没有更改)。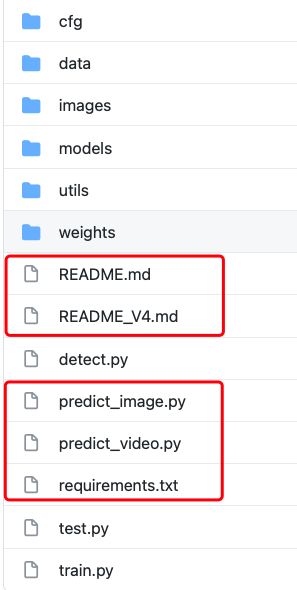
2. 代码结构解析
如上图所示代码结构。
|cfg # 存储模型结构配置文件的地方。
|------|yolov4.cfg
|------|......
|data # 数据读取文件参数。
|------|hyp.scratch.yaml # 训练相关的参数,我一般使用默认。
|------|coco.data # 训练集,验证集,数据集类别,数据集标签类别参数文件。
|------|coco.names # 数据集标签类别。这个文件一般测试的时候使用,貌似train没用到。
|------|......
|images # 存储模型结构的图片。
|------|......
|models # 构建模型的脚本文件。
|------|......
|utils # 程序执行过程中要用到的其他相关函数的脚本文件。
|------|......
|weights # 存放模型的文件,我是把预先训练模型存到了这里。
|------|......
|detect.py # 模型自带的批量推理代码,默认是输入一个图片文件夹,然后输出检测带有框的文件夹。
|test.py # 测试mAP的脚本文件。其中train.py 也会调用它,也可以单独使用,主要是针对coco.data里面的测试集路径进行测试。
|train.py # 训练脚本文件。
### 我新建的一些脚本 ###
|predict_image.py # 预测一张图片的脚本。
|predict_video.py # 预测一段视频的脚本。
|run_train.sh # 运行train.py的shell脚本。
### README.md ###
|README_V4.md # 原作者的README.md文件。
|README.md. # 我的README.md文件。
|requirements.txt # 需要的相关环境下载文件。
3. 训练自己的数据集
3.1. 首先需要准备自己的数据集
这里假设已经有每张图片对应的边框标签文件。
大多数我们可能拿到的是VOC格式的数据集,先将其整理成下图所示的格式(其实不麻烦,有annotations和images就可以其他两个文件需要自己新建)图片来自于公开数据集Seaships。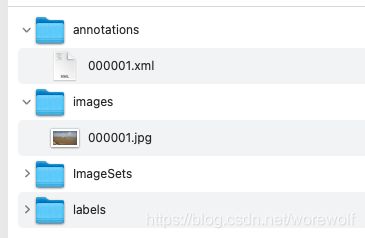
然后通过脚本制作YOLO-V4 Pytorch版本可以读取的格式(这个格式通用于u版的yolo系列,包括现在比赛常用的YOLO-V5)。数据集制作脚本百度搜索很多,我的代码也是搜索自百度,所以没有放到代码仓库里面,这里就在下面直接附上代码(…/代表自己数据集的路径)。
# makeTxt.py 制作训练集和测试集列表的脚本。
# 需要将脚本中的所有路径进行更改,手动改就好,改成自己数据集存储的地方,我建议大家使用绝对路径(不要出现中文)。
import os
import random
trainval_percent = 0.2 # 可自行进行调节
train_percent = 1
xmlfilepath = '../annotations'
txtsavepath = '../images'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
# ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('../ImageSets/test.txt', 'w')
ftrain = open('../ImageSets/train.txt', 'w')
# fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
# ftrainval.write(name)
if i in train:
ftest.write(name)
# else:
# fval.write(name)
else:
ftrain.write(name)
# ftrainval.close()
ftrain.close()
# fval.close()
ftest.close()
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# voc_label.py 生成YOLO可以读取的数据集格式,最后会在labels文件夹下面生成每个图片的标签文件,txt结尾。
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test']
classes = ['a', 'b', 'c'] # 自己训练的类别
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('../annotations/%s.xml' % (image_id))
out_file = open('../labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
print(root.find('filename').text)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('../labels/'):
os.makedirs('../labels/')
image_ids = open('../ImageSets/%s.txt' % (image_set)).read().strip().split()
list_file = open('../%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write('../images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
最后会在路径"…/"下面生成两个文件 train.txt, test.txt(路径写成…/train.txt, …/test.txt,后续需要根据自己的路径更改,建议写绝对路径),然后labels下面会生成每个图片对应的标签文件txt结尾。
3.2. 修改相关的配置文件
(1)修改data文件夹下面的配置文件。主要修改两个文件,也可以新建两个文件一个是 .data结尾一个是 .names结尾的文件,如下:
# my.data
# train和test的路径根据自己的生成情况更改,但是train.txt里面存储的是路径。不是图片的名字。
train: ../train.txt
val: ../test.txt
test: ../test.txt
# number of classes
nc: 3
# class names
names: ['a', 'b', 'c']
# my.names
# 这个文件存储类别,写的时候把这两行备注去掉以防出bug。
a
b
c
(2)修改cfg文件,模型结构文件,以yolov4.cfg为例子。
主要修改两个地方,yolo层和yolo层的上一层。如下图的红色框所示。
比如我们的类别为[‘a’, ‘b’, ‘c’] 所以yolo层里面的 classes改成3。yolo层上一层的filters改成(3 + 5)* 3,这个公式和yolo的输出维度有关系为 (类别数 + 5)* 3。每个cfg文件可能有多个yolo层,标准的YOLO-V4有3个yolo层需要更改三次。
(3)预先训练模型。这里把预先训练模型上传到了百度网盘,大家可以下载。
链接: https://pan.baidu.com/s/1d-Q36qbcV-puNKmGrBLzAg 密码: 0oue
3.3. 执行训练代码train.py
这里可以直接运行我的脚本文件run_train.sh里面写好了训练脚本,大家只需要根据自己的需求和自己的实际路径更改就可以,具体代码如下,每个参数的意思都很直观 (–logdir是存储结果的路径自行更改就好,源代码是写的相对路径,–device 选择显卡,cpu环境可以不写,我习惯本地cpu环境测试,跑通后在服务器运行)。
# 训练脚本shell文件
python train.py --weights weights/yolov4.weights --cfg cfg/yolov4.cfg --epochs 100 --batch-size 4 --img-size 512 --data data/xinye.yaml --device 0 --logdir runs/
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
bash run_train.sh
注意:requirements.txt是按照原代码所写的,我这里是**习惯使用torch1.7.1,torchvision0.8.2版本**相对来说没有什么错误。如果遇到有些包没有,其实再pip就好了,我习惯于加上清华镜像安装环境。
在训练可能会遇到ModuleNotFoundError: No module named ‘mish_cuda’ ,需要根据bug提示把所有的from mish_cuda import MishCuda as Mish替换就好(原作者代码写了安装mish_cuda,但是我选择了直接替换了代码)。
class Mish(nn.Module):
def __init__(self):
super().__init__()
def forward(self,x):
x = x * (torch.tanh(F.softplus(x)))
return x
4. 预测图片和视频
4.1. predict_image.py
这里面的代码主要是方便大家进行测试一张图片,或者后续大家部署的时候可以使用此接口,在代码中写明了,每个函数的作用。这里面需要把模型读取,包括模型读取的尺寸,图片路径进行更改,图片输入尺寸等进行更改,后续会进行更新,写成更加简洁化的接口形式,也希望大家对我的代码提出意见。
if __name__ == "__main__":
"""
letterbox() 图片resize后空白区域填充函数
non_max_suppression() nms
scale_coords_() 图片尺寸还原
read_img() 读取单张图片,返回归一化后的张量 和 原图
init() 初始化模型
process() 主运行函数。输入参数为model,img 返回每张图得到的bbox结果 json格式
"""
img, img0 = read_img(path="data/samples/0056.jpg")
model = init()
res = process(model, img, img0)
4.2. predict_video.py
这是读取一个视频的代码,本质是调用了predict_image.py里面的预测接口进行。在predict_image.py里面的detect()函数是predict_video.py调用的接口,比较好理解,我就是在predict_video.py里面写好了读取视频每一帧的方法所以在调用detect()的时候不需要再根据图片路径读取图片,直接对读取好的图片变量进行后处理。
其他相关连接
下面是我写的一些博客,其实不一定非常详细但是都是按照我学习过程中总结的方式进行的。
YOLO-V1:https://blog.csdn.net/worewolf/article/details/116563934?spm=1001.2014.3001.5501
YOLO-V2:https://blog.csdn.net/worewolf/article/details/116569183?spm=1001.2014.3001.5501
YOLO-V4:https://blog.csdn.net/worewolf/article/details/116569208?spm=1001.2014.3001.5501
github:https://github.com/hx-0614/yolov4-pytorch-learing
后续
后续将补充转成tensorrt,以及如何修改代码等脚本。希望大家看到我的博客能提出指正。
在学习过程中也参考了很多其他大佬的代码,博客,视频,如有侵权将修正。