论文阅读笔记:AM-Softmax: Additive Margin Softmax for Face Verification
论文阅读笔记:AM-Softmax: Additive Margin Softmax for Face Verification
Tags:Deep_Learning_基础论文
本文主要包含如下内容:
论文地址
代码地址
参考博客
- 论文阅读笔记:AM-Softmax: Additive Margin Softmax for Face Verification
- 主要思想
- 算法原理
- 实验结果
- 总结
- 代码实现
- label_specific_add_layer.hpp/label_specific_add_layer.cpp
本篇论文来自电子科技大学UESTC,论文参考NormFace、A-Softmax进行优化,提出了AM-Softmax。
主要思想
L-Softmax, A-Softmax引入了角间距的概念,用于改进传统的softmax loss函数,使得人脸特征具有更大的类间距和更小的类内距。作者在这些方法的启发下,提出了一种更直观和更易解释的additive margin Softmax (AM-Softmax)。同时,本文强调和讨论了特征正则化的重要性。实验表明AM-Softmax在LFW和MegaFace得到了比之前方法更好的效果。

算法原理
L-Softmax和A-Softmax均是引入了一个参数因子m 将权重W和f的cos距离变为cos(mθ),通过m 来调节特征间的距离。与前两者类似,AM-Softmax将cos(θ)的式子改写为:式子是一个单调递减的函数,且比L-Softmax/A-Softmax所用的 Ψ(θ)在形式和计算时更为简单。
其中s是一个缩放因子,论文中固定为30。
角度距离与余弦距离的关系:Asoftmax是用m乘以θ,而AMSoftmax是用cosθ减去m,这是两者的最大不同之处:一个是角度距离,一个是余弦距离。之所以选择cosθ-m而不是cos(θ-m),这是因为我们从网络中得到的是W和f的内积,如果要优化cos(θ-m)那么会涉及到arccos操作,计算量过大。
归一化特征 feature normalization:高质量的图片提取出来的特征范数大,低质量的图片提取出来的特征范数小,在进行了feature normalizaiton后,这些质量较差的图片特征会产生更大的梯度,导致网络在训练过程中将更多的注意力集中在这些样本上。因此,对于数据集图片质量较差时,更适合采用feature normalization。
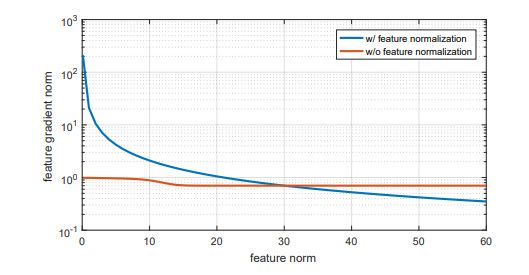
实验结果

值得注意的是,在LFW集上,未采用feature normalization比采用了feature normalizaiton的结果更好,作者分析是由于LFW的数据质量较高。
这里的了feature normalizaiton指的是将Scale层s的参数进行相应的更换,即将固定的s参数改变为对应的特征归一化尺度。即根据特征,缩放比例不一样了。
总结
本文在特征和权值正则化的情况下,提出了一种 additive margin Softmax,更直观也更易解释,同时也取得了比A-Softmax更好的实验结果。
代码实现
代码可以参考NormFace的相关代码, 比较类似。只是在上面进行想应该改进。
这里在NormFace的基础上,提出了新的层LabelSpecificAdd,即AMSoftmax的核心,将cosθ减去m。
layer {
name: "norm1"
type: "Normalize"
bottom: "fc5"
top: "norm1"
}
layer {
name: "fc6_l2"
type: "InnerProduct"
bottom: "norm1"
top: "fc6"
param {
lr_mult: 1
}
inner_product_param{
num_output: 10516
normalize: true
weight_filler {
type: "xavier"
}
bias_term: false
}
}
layer {
name: "label_specific_margin"
type: "LabelSpecificAdd"
bottom: "fc6"
bottom: "label"
top: "fc6_margin"
label_specific_add_param {
bias: -0.35
}
}
layer {
name: "fc6_margin_scale"
type: "Scale"
bottom: "fc6_margin"
top: "fc6_margin_scale"
param {
lr_mult: 0
decay_mult: 0
}
scale_param {
filler{
type: "constant"
value: 30
}
}
}
layer {
name: "softmax_loss"
type: "SoftmaxWithLoss"
bottom: "fc6_margin_scale"
bottom: "label"
top: "softmax_loss"
loss_weight: 1
}
layer {
name: "Accuracy"
type: "Accuracy"
bottom: "fc6"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}label_specific_add_layer.hpp/label_specific_add_layer.cpp
label_specific_add_layer.hpp/label_specific_add_layer.cpp(执行cosθ减去m操作)
公式:
#ifndef CAFFE_LABEL_SPECIFIC_ADD_LAYER_HPP_
#define CAFFE_LABEL_SPECIFIC_ADD_LAYER_HPP_
#include {
public:
explicit LabelSpecificAddLayer(const LayerParameter& param)
: Layer(param) {}
virtual void LayerSetUp(const vector #include ::LayerSetUp(const vector::Reshape(const vector::Forward_cpu(const vector::Backward_cpu(const vector