一文尽览 | 首篇Transformer在3D点云中的应用综述(检测/跟踪/分割/降噪/补全)...
后台回复【3D检测综述】获取最新基于点云/BEV/图像的3D检测综述!
1 摘要
Transformer 一直是自然语言处理 (NLP) 和计算机视觉 (CV) 的核心。NLP 和 CV 的巨大成功激发了研究者对 Transformer 在点云处理中的使用的探索。但是,Transformer如何应对点云的不规则性和无序性?Transformer 对不同的 3D 表示(例如点云或体素)的适用性如何?Transformer 对各种 3D 处理任务的能力如何?到目前为止,还没有对这些问题的研究进行系统的调查。论文全面概述了用于 3D 点云分析的 Transformer算法。首先介绍 Transformer 结构的理论并回顾其在 2D/3D 领域的应用。然后,提出了三种不同的分类法(即基于实现、数据表示和任务),可以从多个角度对当前基于 Transformer 的方法进行分类。此外,论文展示了 3D 中self-attention机制的变体和改进的相关结果。为了证明 Transformer 在点云分析中的优越性,论文对各种基于 Transformer 的分类、分割和目标检测方法进行了全面比较。最后,提出了三个潜在的研究方向,为3D Transformer 的发展提供有益参考。
2 介绍
编码器或解码器中的 Transformer现在是 NLP 中的主要神经网络结构。鉴于建模远程依赖的强大能力,它们已成功应用于自动驾驶、视觉计算、智能监控和工业检测等 CV [1]-[3] 领域。一个标准的 Transformer 编码器通常由六个主要组件组成,如下图所示:
-
输入(word)嵌入;
-
位置编码;
-
self-attention;
-
归一化;
-
feed-forward;
-
跳跃链接。
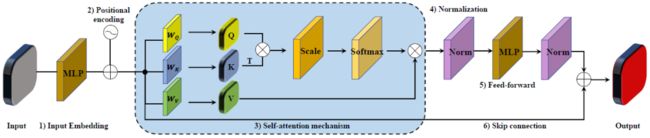
至于 Transformer 解码器,通常被设计为编码器的镜像,除了额外将编码器的潜在特征作为输入。然而,对于 3D 点云应用,解码器可以专门设计(即不是纯 Transformer)用于密集预测任务,例如 3D 点云分析中的部件分割和语义分割。3D 视觉研究人员通常采用 PointNet++ [4] 或其中包含 Transformer 模块的卷积主干。
由于优秀的全局特征学习能力和置换等变操作,Transformer 本质上适用于点云处理和分析。目前研究人员提出了许多用于点云分类和分割的 3D Transformer 主干(见下图)[7]、[12]、[34]、[37]、[69]、[70]、检测 [35]、[ 54],跟踪[56]-[58],配准[59]-[63],[71],[72],补全[50],[66]-[68],[73],[74],仅举几例。此外,3D Transformer 网络也被用于各种实际应用,例如结构监测 [75]、医学图像分析 [37] 和自动驾驶 [76]、[77]。因此,有必要对3D Transformer进行系统的调查。
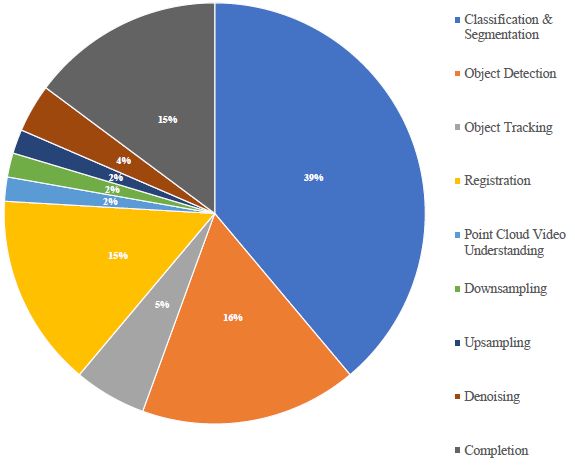
论文设计了三种不同的分类法,如下图所示:1)基于实现 2) 基于数据表示和 3)基于任务。通过这种方式,我们能够从多个角度对 Transformer 网络进行分类和分析。但这些分类法并不相互排斥。以Point Transformer(PT)[7]为例:1)在Transformer实现方面,属于局部Transformer范畴,在目标点云的局部邻域内运行;2)在数据表示方面,属于多尺度基于点云的Transformer范畴,分层提取几何和语义特征;3)在3D任务方面,专为点云分类和分割而设计。此外,论文还对 3D 点云处理中的不同自注意力变体进行了调查。

论文的主要贡献如下:
-
论文是首篇致力于在点云中全面调查 Transformer 来实现 3D 视觉任务的工作;
-
论文研究了点云分析中的一系列自注意力变体。其引入了新的自注意力机制,旨在提高 3D Transformer 的性能和效率;
-
论文在几个 3D 视觉任务上提供了基于 Transformer 方法的比较和分析,包括 3D 形状分类和 3D 形状/语义分割,以及几个公共基准上的 3D 目标检测;
-
论文向读者介绍了 SOTA 方法以及基于 Transformer 的点云处理方法的最新进展。
3 Transformer实现
在本节中,论文从多个角度对 3D 点云中的 Transformer 进行了广泛的分类。首先,就操作尺度(Operating Scale)而言,3D Transformers 可以分为:Global Transformers 和 Local Transformers。操作尺度表示算法相对于点云的范围,例如全局域或局部域。其次,就操作空间而言,3D Transformer 可以分为 Point-wise Transformers 和 Channel-wise Transformers。操作尺度表示算法计算的维度,如空间维度或通道维度。最后,论文回顾了为减少计算量而设计的高效 Transformer 网络。
3.1 操作规模
根据操作,3D Transformer 可以分为两个部分:Global Transformer 和Local Transformer 。前者表示将 Transformer 模块应用于所有输入点云以提取全局特征,而后者表示将 Transformer 模块应用于局部 patch 以提取局部特征。
3.1.1 Global Transformers
现有的许多算法 [8]、[10]-[12]、[31]、[33]、[37]、[38]、[52]、[81] 专注于Global Transformer。对于Global Transformer模块,每个输出特征都可以与所有输入特征建立连接。它在输入的排列方面是等变的,并且能够学习全局上下文特征 [12]。
继 PointNet [5] 之后,PCT [12]作为一个纯全局 Transformer 网络被提出。PCT 以 3D 坐标作为输入,首先提出了一种邻域嵌入结构,将点云映射到高维特征空间。此操作还可以将局部信息合并到嵌入特征中。然后将这些特征输入到四个堆叠的全局 Transformer 模块中以学习语义信息。最终通过全global Max和Average池化提取全局特征,用于分类和分割。此外,PCT 改进的 self-attention 模块,名为 Offset-Attention。
与 PCT 的单一尺度相比,在 [31] 中提出了一个 Cross-Level、Cross-Scale、Cross-Attention的Transformer 网络,名为 3CROSSNet。首先对原始输入点云执行Farthest Point Sampling(FPS)算法[4],以获得具有不同分辨率的三个点云子集。其次,利用堆叠的多个共享多层感知(MLP)模块来提取每个采样点云的局部特征。第三,将 Transformer 模块应用于每个点云子集以进行全局特征提取。最后,提出了Cross-Level Cross-Attention (CLCA) 模块和Cross-Scale Cross-Attention (CSCA) 模块来建立不同分辨率点云子集和不同层级特征之间的连接,以实现远程层间和层内的依赖建模。
其他相关工作[33]、[5]请参考论文。
3.1.2 Local Transformers
与全局 Transformer 相比,局部 Transformer [7]、[34]、[35]、[42]、[85]、[86] 旨在实现局部patch而不是整个点云中的特征聚合。
PT [7] 采用 PointNet++ [4] 分层架构进行点云分类和分割。其专注于local patch处理,并将 PointNet++ 中的共享 MLP 模块替换为local Transformer 模块。PT 有五个local Transformer ,在逐步下采样的点云集上运行。每个模块都应用于采样点云的 K-最近邻 (KNN) 邻域。具体来说,PT 使用的自注意力算子是向量注意力 [87] 而不是标量注意力。前者已被证明对点云处理更有效,因为它支持通道注意力,而不是将单个权重分配给整个特征向量。
Pointformer 在 [35] 中提出,将 Transformer 提取的局部和全局特征结合起来进行 3D 目标检测。Pointformer 主要包含三个模块:Local Transformer (LT) block、Global Transformer (GT) block和Local-Global Transformer (LGT) block。首先,LT 在 FPS [4] 生成的每个centroid point邻域使用密集的自注意力操作。其次,以整个点云为输入,GT模块旨在通过自注意力机制学习全局上下文感知特征。最后,LGT 块采用多尺度交叉注意模块,在 LT 的局部特征和 GT 的全局特征之间建立连接。
受 Swin Transformer [21] 的启发,[51] 提出了 Stratified Transformer 用于 3D 点云分割。它通过 3D 体素化将点云分割成一组不重叠的立方窗口,并在每个窗口中执行局部 Transformer 操作。其他相关工作[88]请参考论文。
3.2 操作空间
根据操作空间,3D Transformer 可以分为两类:Point-wise 和 Channel-wise Transformers。前者测量输入点云之间的相似性,而后者沿通道分配注意力权重[40]。一般来说,这两种Transformer的注意力图可以表示为:
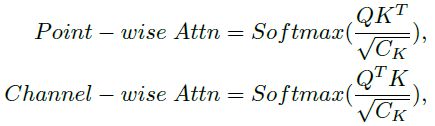
3.2.1 Point-wise Transformers
Point-wise Transformers 旨在研究点云之间的空间相关性,并将输出特征图表示为所有输入特征的加权和。
全局 Transformer 和局部 Transformer 区别在于空间操作尺度,即整个点云或局部patch,因此所有上述方法[7],[8],[10]-[12],[31],[33]-[35] , [37], [38], [42], [51], [52], [81] 可以被认为是Point-wise Transformer。
Point-wise Transformers 也广泛应用于其他任务。[36] 提出了一种用于点云去噪的编码器-解码器 Transformer 网络(TD-Net)。编码器由一个基于坐标的输入嵌入模块、自适应采样模块和四个堆叠的point-wise自注意力模块组成。四个自注意力模块的输出连接在一起作为解码器的输入。此外,TD-Net 使用了自适应采样方法,可以自动学习 FPS [4] 生成的每个采样点云的偏移量。解码器用于根据提取的高级特征构建underlying manifold。最后,可以通过manifold sampling重建去噪后的点云。其他相关算法[37]、[10]、[52]可以参考论文。
3.2.2 Channel-wise Transformers
与point-wise Transformers相比,channel-wise Transformers[38]-[41]、[69]专注于测量不同特征通道间的相似性。其通过强调跨通道交互的作用来改进上下文信息建模[39]。
[40] 利用纠错反馈结构(error-correcting feedback structure)的思想提出了一种用于局部特征捕获的反投影模块。他们设计了一个 Channel-wise Affinity Attention (CAA) 模块以获得更好的特征表示。具体来说,CAA 模块由两个模块组成:Compact Channel-wise Comparator (CCC) 模块和Channel Affinity Estimator (CAE) 模块。CCC 可以在通道空间中生成相似度矩阵。CAE进一步计算了一个affinity矩阵,其中attention值越高的元素代表对应的两个通道的相似度越低。此操作可以提高注意力权重并避免聚合相似或冗余信息。因此,输出特征的每个通道与其他不同的通道有足够的交集,并有利于模型学习。
3.3 Efficient Transformers
尽管在点云处理上取得了巨大成功,但标准 Transformer 往往会因为大量的线性运算而导致高计算量和内存消耗。给定 N 个输入点云,标准自注意力模块的计算和内存复杂度是 N 的二次方,即 。这是在大规模点云数据集上应用 Transformer 的主要缺点。
最近,有几个 3D Transformer 在研究改进自注意力模块以提高计算效率。例如,Centroid Transformer [42] 将 N 个点云特征作为输入,输出 M 个点云特征(M<N)。因此,输入点云中的关键信息可以通过较少数量的输出(称为质心)来概括。具体来说,它首先通过优化一般的“soft K-means”目标函数从 N 个输入点构建 M 个质心。然后使用 M 个质心和 N 个输入点云分别生成 Query 和 Key 矩阵。注意图的大小从 N×N 减少到 M×N,因此 self-attention 的计算成本从 减少到 。为了进一步节省计算成本,作者使用了KNN近似。该操作实质上是将全局 Transformer 转换局部 Transformer。在这种情况下,相似度矩阵是通过测量每个query特征向量与其 K 个相邻key向量之间的关系而不是 N 个向量来生成的。所以计算成本可以进一步降低到。类似的,PatchFormer [89] 也尝试减少注意图的大小。
Light-weight Transformer Network(LightTN)[43]采用不同的方式降低计算成本。LightTN 旨在简化标准Transformer中的主要组件,在提高效率的同时保持Transformer的性能。首先,去除了位置编码,因为输入的 3D 坐标已经包含位置信息,节省了该部分的计算量。其次,利用一个小尺寸的共享线性层作为输入嵌入层。与 [12] 中节省计算的neighbor embedding相比,嵌入特征的维度减少了一半,因此进一步减少了计算量。第三,提出了一个单头自相关层作为自注意模块。由于注意力图仅由输入的自相关参数生成,因此自注意力模块也被命名为自相关模块,可以表述为:
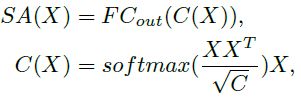
4 数据表示
3D 数据表示有多种形式,例如点云和体素都可以作为 3D Transformer 的输入。由于点云可以由体素表示或转换为体素,因此也可以在点云上进行几种基于体素的方法,例如 3D Transformer。根据输入格式的不同,论文将 3D Transformer 分为 Voxel-based Transformers 和 Point-based Transformers。
4.1 基于体素的Transformers
与图像不同的是,3D 点云通常是非结构化的,不能直接使用传统的卷积算子处理。但是,3D 点云可以很容易地转换为 3D 体素,其结构类似于图像。因此,一些基于 Transformer 的工作 [45]-[47]、[51] 探索了将 3D 点云转换为基于体素的表示。最通用的体素化方法可以描述如下[91]:首先通过栅格化将点云的边界框规则地划分为 3D 长方体。保留包含点云的体素,生成点云的体素表示。
受稀疏卷积的启发 [92]、[93],Mao 等[46] 首次提出了用于 3D 目标检测的体素Transformer (VoTr) 主干。他们提出了Submanifold Voxel模块和Sparse Voxel模块,分别从非空体素和空体素中提取特征。在这两个模块中,在多头自注意力机制(MSA)的基础上,实现了局部注意力和扩张注意力操作,以保持大量体素的低计算消耗。所提出的 VoTr 可以集成到大多数基于体素的 3D 检测器中。为了解决基于体素的室外 3D 检测器的 Transformer 的计算问题,提出了Voxel Set Transformer (VoxSeT) [47] 以一种set-to-set的方式检测室外物体。基于自注意力矩阵的低秩特性,设计了一个Voxel-based Self-Attention (VSA)模块,通过为每个体素分配一组可训练的“latent codes”,其灵感来自于Set Transformer [94]。其他相关算法[48]、[49]请参考论文。
4.2 基于点云的Transformers
由于体素是常规格式而点云不是,因此转换为体素会在一定程度上损失几何信息[4],[5]。另一方面,由于点云是原始表示,它包含了数据的完整几何信息。因此,大多数基于 Transformer 的点云处理框架都属于基于点云的 Transformer 范畴。结构通常分为两大类:统一尺度(uniform-scale)结构[12]、[33]、[50]、[63]、[81]和多尺度(multi-scale)结构[7]、[8]、[37]、[39] ],[51],[52]。
4.2.1 统一尺度
统一尺度结构通常在数据处理过程中保持点云特征的尺度不变。每个模块的输出特征数与输入特征数一致。最具代表性的工作是 PCT [12],在输入嵌入阶段之后,PCT 的四个全局 Transformer 模块直接堆叠在一起以细化点云特征。没有分层特征的聚合操作,这有助于点云分割等密集预测任务。将所有点云送入 Transformer有利于全局特征学习。然而,由于缺乏局部邻域信息,统一尺度的 Transformer 在提取局部特征方面往往较弱。此外,直接处理整个点云会导致高计算量和内存消耗。
4.2.2 多尺度
多尺度Transformer是指在特征提取过程中采用渐进式点云采样策略的Transformer,也称为分层Transformers。PT [7] 是将多尺度结构引入纯 Transformer 网络的开创性设计。PT 中的 Transformer 层应用于渐进式(子)采样点云集。一方面,采样操作可以通过减少 Transformer 的参数来加速整个网络的计算。另一方面,这些分层结构通常带有基于 KNN 的局部特征聚合操作。这种局部特征聚合有利于需要精细语义感知的任务,例如分割和补全。而网络最后一层高度聚合的局部特征可以作为全局特征,用于点云分类。此外,还存在许多多尺度 Transformer 网络 [8]、[37]、[51]、[52],它们利用 EdgeConv [13] 或 KPconv [88] 进行局部特征提取,并利用 Transformer 提取全局特征。因此它们能够结合卷积强大的局部建模能力和 Transformer 卓越的全局特征学习能力,以获得更好的语义特征表示。
5 3D 任务
与图像处理 [29] 类似,与 3D 点云相关的任务也可以分为两大类:高级任务和低级任务。高级任务涉及语义分析,其重点是将 3D 点云转换为人们可以理解的信息。去噪和补全等低级任务侧重于探索基本几何信息。它们与人类语义理解没有直接关系,但可以间接促进高级任务。
5.1 高级任务
在 3D 点云处理领域,高级任务通常包括:分类和分割 [7]、[11]、[12]、[32]-[34]、[37]、[39]、[40] , [42], [44], [45], [51], [85], [86], [89], [95]–[99], 目标检测 [35], [46], [47] , [53]–[55], [69], [77], [100]–[102], 跟踪 [56]–[58], 配准 [59]–[63], [71], [72] , [103] 等等。
5.1.1 分类和分割
与图像分类[104]-[107]类似,3D点云分类方法旨在将给定的3D形状分类为特定类别,例如室内场景的椅子、床和沙发,以及室外场景的行人、骑自行车的人和汽车。在 3D 点云处理领域,由于分割网络的编码器通常是从分类网络发展而来的,因此论文将这些任务一起介绍。
Xie等[11]首次将self-attention机制引入点云识别任务。受形状上下文[108]在形状匹配和目标识别方面成功的启发,作者首先将输入点云转换为形状上下文表示的形式。该表示由一组concentric shell bins组成。基于提出的新颖表示,他们随后引入了 ShapeContextNet (SCN) 提取点云特征。为了自动捕获丰富的局部和全局信息,进一步使用点积自注意力模块,从而产生了 Attentional ShapeContextNet (A-SCN)。
受图像分析 [87]、[109] 和 NLP [83] 中的自注意力网络的启发,Zhao 等 [7] 设计了一个基于向量注意力的点云Transformer层。Point Transformer block是在 Point Transformer layer的基础上以残差方式构建的。PT 的编码器仅使用Point Transformer blocks、逐点变换和用于点云分类的池化操作构建。此外,PT 还使用 U-Net 结构实现点云分割,其中解码器与编码器对称。它提出了一个 Transition Up 模块,用于从下采样点云集中恢复具有语义特征的原始点云。此外,引入了跳跃连接以促进反向传播。凭借这些精心设计的模块,PT 成为第一个在 S3DIS 数据集 [110] 的Area 5上达到超过 70% mIoU (70.4%) 的语义分割模型。至于在 ModelNet40 数据集上的形状分类任务,Point Transformer 也取得了 93.7% 的整体准确率。
5.1.2 目标检测
得益于 3D 点云扫描仪的普及,3D 目标检测正成为越来越热门的研究课题。与 2D 目标检测任务类似,3D 目标检测器旨在输出3D边界框。最近,[15] 提出了第一个基于 Transformer 的 2D 目标检测器 DETR。其将 Transformer 和 CNN 结合起来,并摒弃了非极大值抑制 (NMS)。从那时起,Transformer 相关的作品在基于点云的 3D 目标检测领域也呈现出蓬勃发展的态势。
在 VoteNet [113] 的基础上,[53]、[114] 首次将 Transformer 的自注意力机制引入到室内场景中的 3D 目标检测任务中。他们提出了Multi-Level Context VoteNet(MLCVNet),通过编码上下文信息来提高检测性能。在论文中,每个点云patch和vote cluster都被视为 Transformers 中的token。然后利用自注意力机制通过捕获点云patch和vote cluster的关系来增强相应的特征表示。由于集成了自注意力模块,MLCVNet 在 ScanNet [80] 和 SUN RGB-D 数据集 [79] 上都取得了比基线模型更高的性能。PQ-Transformer [100] 尝试同时检测 3D目标 和预测房间布局。借助 Transformer 解码器的房间布局估计和细化特征,PQ-Transformer 在 ScanNet 上获得了 67.2% 的 [email protected]。
上述方法采用手工分组方案,通过从相应局部区域内的点云学习来获得目标候选的特征。然而,[54] 认为有限区域内的点云grouping往往会限制3D目标检测的性能。因此,他们借助 Transformers 中的注意力机制提出了一个group-free的框架。核心思想是候选目标的特征应该来自给定场景中的所有点云,而不是点云的子集。在获得候选目标后,[54]首先利用自注意力模块来捕获候选目标之间的上下文信息。然后设计了一个交叉注意力模块,利用所有点云的信息来细化目标特征。通过改进的注意力堆叠方案,[54]在 ScanNet 数据集上实现了 69.1% 的 [email protected]。其他相关算法[55]、[69]、[115]可以参考论文。
5.1.3 目标跟踪
3D 目标跟踪将两个点云(即模板点云和搜索点云)作为输入。它在搜索点云中输出目标(模板)的 3D 边界框。即涉及点云的特征提取以及模板和搜索点云之间的特征融合。
[56]认为大多数现有的跟踪方法都没有考虑跟踪过程中目标区域的注意力变化。即搜索点云中的不同区域应该对特征融合过程贡献不同的重要性。基于这一观察,他们提出了一种基于 LiDAR 的 3D 目标跟踪网络 TRansformer network (LTTR)。该方法能够通过捕获跟踪时间的注意力变化来改进模板和搜索点云的特征融合。具体来说,首先构建了一个 Transformer 编码器,分别改进模板和搜索点云的特征表示。然后使用交叉注意力构建Transformer解码器,其可以通过捕获两个点云之间的关系融合来自模板和搜索点云的特征。受益于基于 Transformer 的特征融合,LTTR 在 KITTI 跟踪数据集上达到了 65.8% 的平均精度。[57] 还提出了一个Point Relation Transformer (PRT) 模块,以改进coarse-to-fine的Point Tracking TRansformer (PTTR) 框架中的特征融合。与 LTTR 类似,PRT 使用自注意力和交叉注意力分别对点云内部和点云之间的关系进行编码。不同之处在于 PRT 利用 Offset-Attention [12] 来减轻噪声数据的影响。最终,PTTR 在平均成功率和精度方面分别超过 LTTR 8.4% 和 10.4%,成为 KITTI 跟踪基准上的新 SOTA。
与上述两种专注于特征融合步骤的方法不同。[58]引入了一个Point-Track-Transformer(PTT)模块来增强特征融合步骤后的特征表示。PTTNet 在 KITTI 的 Car上精度相比于 P2B 提高了 9.0%。
5.1.4 点云配准
给定两个点云作为输入,点云配准的目的是找到一个变换矩阵进行对齐。
[59] 中提出的Deep Closest Point (DCP) 模型将 Transformer 编码器引入到点云配准任务中。未对齐的点云首先送入特征嵌入模块,例如 PointNet [5] 和 DGCNN [13],以将 3D 坐标转换到特征空间。然后使用标准的 Transformer 编码器来执行两个特征间的上下文聚合。最后,DCP 利用可微分奇异值分解 (SVD) 层来计算刚性变换矩阵。DCP 是第一个使用 Transformer 来改进配准中点云特征提取的工作。类似地,STORM [60] 也使用 Transformer 来细化 EdgeConv [13] 提取的point-wise特征,以捕获点云之间的长期关系。最终在 ModelNet40 数据集上取得了比 DCP 更好的性能。同样,[61]利用多头自注意力和交叉注意力机制来学习目标和源点云之间的上下文信息。他们的方法专注于处理户外场景,例如 KITTI 数据集 [117]。
最近,[72] 认为在点云配准中可以使用注意力机制替换通过 RANSAC 进行的显式特征匹配和异常值过滤。他们设计了一个名为 REGTR 的端到端 Transformer 框架,以直接查找点云对应关系。在 REGTR 中,来自 KPconv [88] 主干的点云特征被输入到几个多头自注意力和交叉注意力层中,用于比较源点云和目标点云。通过上述简单的设计,REGTR 成为 ModelNet40 [112] 和 3DMatch [118] 数据集上SOTA的点云配准方法。类似地,GeoTransformer [71] 也利用自注意力和交叉注意力来找到鲁棒的superpoint correspondences。在配准 Recall上,REGTR 和 GeoTransformer 在 3DMatch 数据集上都达到了 92.0%。然而,GeoTransformer 在 3DLoMatch [119] 数据集上超过 REGTR 10.2%。其他相关算法[62]请参考论文。
5.1.5 点云视频理解
我们周围的 3D 世界是动态的、时间连续的,这是传统单帧和固定点云无法完全表示的。相比之下,点云视频(以固定帧速率捕获的一组点云)可能是现实世界中动态场景更好的表示。了解动态场景和动态目标对于将点云模型应用于现实世界非常重要。点云视频理解涉及处理 3D 点云的时间序列,所以Transformer 可能是处理点云视频不错的选择,因其擅长处理全局远程交互。
基于上述讨论, [64] 提出了 P4Transformer 来处理点云视频以实现动作识别。为了提取点云视频的局部时空特征,输入数据首先由一组时空局部区域表示。然后使用点云 4D 卷积编码每个局部区域的特征。之后引入Transformer 编码器,通过捕获整个视频的远程关系来接收和整合局部区域的特征。P4Transformer 已成功应用于点云的 3D 动作识别和 4D 语义分割任务。在许多基准测试上(例如,3D动作识别数据集 MSR-Action3D [120] 和 NTU RGB+D 60 [121] 及 4D 语义分割数据集 Synthia 4D [93]),取得了比基于 PointNet++ 的方法更高的结果,展示了 Transformers 在点云视频理解上的有效性。
5.2 低级任务
低级任务的输入数据通常是具有遮挡、噪声和不均匀密度的原始扫描点云。因此,低级任务的最终目标是获得高质量的点云,这可能有利于高级任务。一些典型的低级任务包括点云下采样[43]、上采样[38]、去噪[36]、[65]、补全[50]、[66]-[68]、[73]、[74] ,[123],[124]。
5.2.1 下采样
给定一个具有 N 个点的点云,下采样方法旨在输出具有 M 个点的更小尺寸的点云,同时保留输入点云的几何信息。利用 Transformers 强大的学习能力,LightTN [43] 首先去除了位置编码,然后使用了一个小尺寸的共享线性层作为嵌入层。此外,MSA 模块被单头自相关层取代。实验结果表明,上述策略显着降低了计算成本。在仅采样 32 个点的情况下,仍然可以达到 86.18% 的分类准确率。此外,轻量级的 Transformer 网络被设计成一个可拆卸的模块,可以很容易地插入到其他神经网络中。
5.2.2 上采样
与下采样相反,上采样方法旨在恢复丢失的精细几何信息[125]。我们期望上采样后的点云可以反映真实的几何形状,并位于给定稀疏点云表示的目标表面上。PU-Transformer [38] 是第一个将 Transformer 应用于点云上采样的工作。[38] 设计了两个新颖的模块。第一个模块是Positional Fusion(PosFus)模块,旨在捕获与局部位置相关的信息。第二个是 Shifted Channel Multi-head Self-Attention (SC-MSA) 模块,旨在解决传统 MSA 中不同head输出之间缺乏连接的问题。实验结果表明,PU-Transformer 展示了基于 Transformer 的模型在点云上采样中的巨大潜力。
5.2.3 降噪
去噪以被噪声破坏的点云作为输入,利用局部几何信息输出干净的点云。首篇相关工作TDNet [36],将每个点云作为word token,证明了 NLP Transformer [6] 适用于点云特征提取。基于 Transformer 的编码器将输入点云映射到高维特征空间并学习点云之间的语义关系。通过从编码器中提取的特征,可以获得噪声输入点云的 latent manifold。最后,可以通过对每个patch manifold进行采样来生成干净的点云。
另一类点云去噪方法是直接从输入点云中滤除噪声点。例如,一些激光雷达点云可能包含大量虚拟(噪声)点云,这些点云是由玻璃或其他反射材料的镜面反射产生的。为了检测这些反射噪声点云,[65] 首先将输入的 3D LiDAR 点云投影到 2D range image中。然后使用基于 Transformer 的自动编码器网络来预测噪声掩码,进而获取反射噪声点云。
5.2.4 补全
在大多数 3D 实际应用中,由于来自其他目标的遮挡或自遮挡,通常很难获得目标或场景的完整点云。这个问题使得点云补全成为 3D 视觉领域中一项重要的低级任务。
[66] 首次提出PoinTr,将点云补全转换为集合到集合的翻译任务。具体来说,作者声称输入点云可以由一组局部点云表示,称为“点云代理”。其以一系列点云代理作为输入,精心设计了一个几何感知的 Transformer block来生成缺失部分的点云代理。以一种从粗到细的方式,最终使用 FoldingNet [126] 根据预测的点云代理补全点云。其他相关算法[67]、[68]可以参考论文。
6 3D自注意力变体
基于标准的 self-attention 模块,有许多变体旨在提高 Transformers 在 3D 点云处理中的性能。
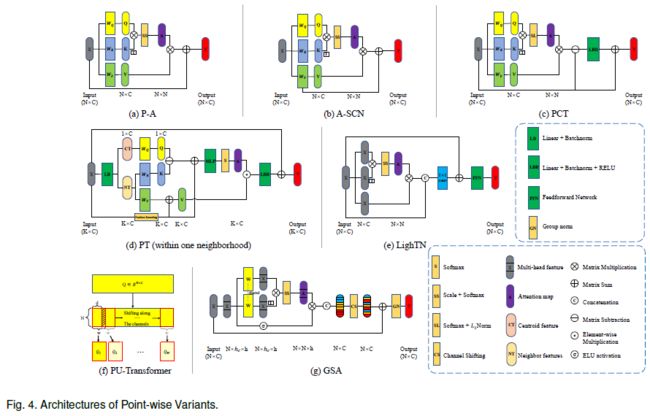
6.1 Point-wise变体
P-A [10](下图a)和 A-SCN [11](下图b)在其 Transformer 编码器中使用不同的残差结构。前者加强了模块的输出和输入之间的联系,而后者则建立了模块的输出与Value 矩阵的关系。相关实验表明,残差连接促进了模型收敛[11]。
受图卷积网络 [82] 中的拉普拉斯矩阵的启发,PCT [12] 进一步提出了 Offset-Attention 模块(下图c)。该模块通过矩阵减法计算自注意力(SA)特征与输入特征X之间的偏移(差异),类似于离散拉普拉斯运算。
PT [7](图 4(d))在其 Transformer 网络中引入了向量减法注意力算子,取代了常用的标量点积注意力。与标量注意相比,向量注意力更具表现力,因为它支持单个特征通道的自适应调制,而不是整个特征向量。这种表达方式在 3D 数据处理中似乎非常有益 [7]。其他相关可以算法[8]、[43]、[38]、[44]可以参考论文。
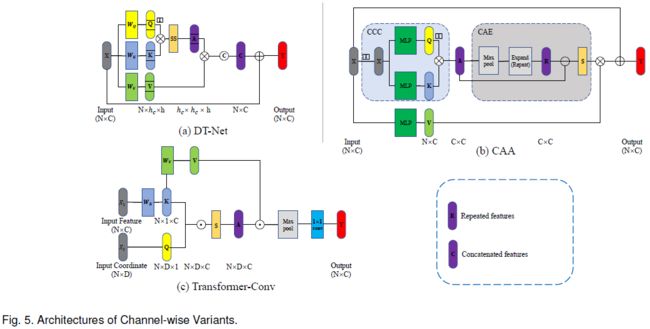
6.2 Channel-wise变体
Dual Transformer Network (DT-Net) [39] 提出了基于通道的 MSA,将自注意力机制应用于通道空间。如下图a所示,与标准的自注意力机制不同,channel-wise MSA 将转置的 Query 矩阵和 Key 矩阵相乘。因此,可以生成注意力图来测量不同通道之间的相似性。
如下图b所示,CAA 模块 [40] 利用类似的方法来生成不同通道之间的相似度矩阵。此外,它设计了一个 CAE 模块来生成亲和矩阵,加强不同通道之间的联系并避免聚合相似或冗余的信息。[41] 中提出的 Transformer-Conv 模块学习了特征通道和坐标通道之间的潜在关系。如下图c所示,Query 矩阵和 Key 矩阵分别由点云的坐标和特征生成。
7 对比和分析
本节对 3D Transformer 在分类、部件分割、语义分割和目标检测等几个主流任务上进行了整体比较和分析。
7.1 分类和分割
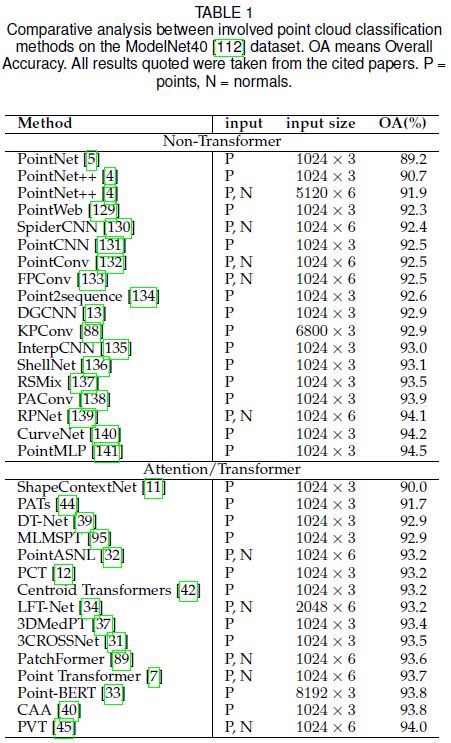
3D 点云分类和分割是两项基本但具有挑战性的任务,Transformers 在其中发挥了关键作用。分类最能反映神经网络提取显著特征的能力。下表展示了不同方法在 ModelNet40 [112] 数据集上的分类精度。为了公平比较,还显示了输入数据和输入大小。
从表格中可以看到最近基于 Transformer 的点云处理方法从 2020 年开始激增,当时在 ViT 论文 [17] 中首次将 Transformer 结构用于图像分类。由于强大的全局信息聚合能力,Transformers 在这项任务中迅速取得领先地位。大多数 3D Transformer 的分类准确率约为 93.0%。最新的 PVT [45] 将极限推到了 94.0%,超过了同期大多数非 Transformer 算法。作为一项新兴技术,Transformer 在点云分类方面的成功展示了其在 3D 点云处理领域的巨大潜力。论文还展示了几种最先进的基于非 Transformer 的方法作为参考。可以看出,最近基于非Transformer的方法的分类准确率已经超过94.0%,最高的是94.5%,由PointMLP[141]实现。Transformer 方法中使用的各种注意力机制是通用的,未来具有很大的突破潜力。我们相信将通用点云处理方法的创新应用于 Transformer 方法可以实现最先进的结果。例如,PointMLP 中的几何仿射模块可以很容易地集成到基于 Transformer 的网络中。
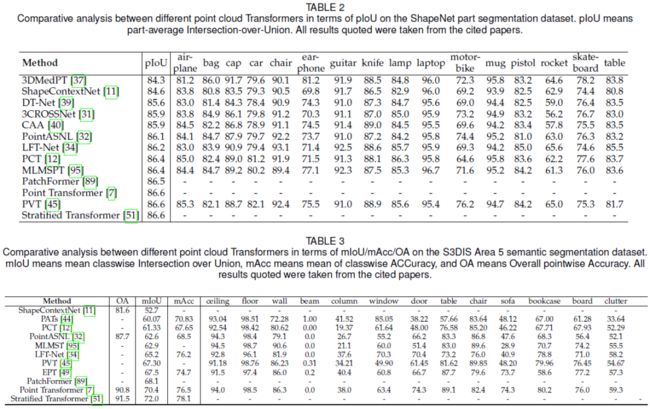
对于部件分割,使用 ShapeNet 部件分割数据集 [142] 结果进行比较。将常用的part-average Intersection-over-Union 作为性能指标。如表2所示,所有基于 Transformer 的方法都实现了大约 86% 的 pIOU,除了 ShapeContextNet [11],它是 2019 年之前发布的早期模型。请注意,Stratified Transformer [51] 实现了最高的 86.6% pIOU。它也是 S3DIS 语义分割数据集 [110](表 3)上语义分割任务中的最佳模型。
7.2 目标检测
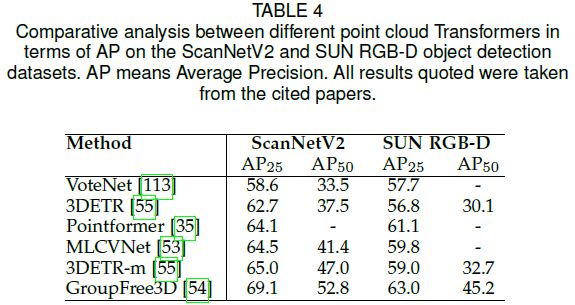
Transformers 在点云 3D 目标检测中的应用仍然较少。最近只有少数基于 Transformer 或 Attention 的方法。一个原因可能是目标检测比分类更复杂。表4 总结了相关算法在两个数据集上的性能:SUN RGB-D [79] 和 ScanNetV2 [80]。VoteNet [113] 也作为参考,这是 3D 目标检测的开创性工作。在 ScanNetV2 数据集中的 AP@25 方面,所有基于 Transformer 的方法都比 VoteNet 表现得更好。Pointformer [35] 和 MLCVNet [53] 基于 VoteNet,并取得了相似的性能。他们都利用了 Transformers 中的自注意力机制来增强特征表示。GroupFree3D [54] 没有利用上述两种方法中的局部投票策略,而是直接从场景中的所有点云聚合语义信息来提取目标的特征。其 69.1% 的性能表明,通过自注意力机制聚合特征比局部投票策略更有效。3DETR [55] 作为第一个端到端的基于 Transformer 的 3D 目标检测器,在 ScanNetV2 数据集中取得第二名,为 65.0%。
8 讨论和总结
8.1 讨论
与 2D 计算机视觉一样,Transformers 在 3D 点云处理方面也展示了其潜力。从 3D 任务的角度来看,基于 Transformer 的方法主要侧重于高级任务,例如分类和分割。论文认为原因是 Transformer 更擅长通过捕获长依赖关系来提取全局上下文信息,这对应于高级任务中的语义信息。另一方面,降噪和采样等低级任务侧重于探索局部几何特征。从性能的角度看,3D Transformers 提高了上述任务的准确性,并超越了大多数现有方法。但是对于某些任务,它们与最先进的基于非Transformer的方法之间仍有差距。这表明仅使用 Transformer 作为主干是不够的。必须采用其他创新的点云处理技术。因此,尽管3D Transformer 发展迅速,但作为一项新兴技术,仍需进一步探索和完善。
基于 Transformer 的特性及其在 2D 领域的成功应用,论文指出了 3D Transformers 的几个潜在未来方向。
8.1.1 Patch-wise Transformers
3D Transformer 可以分为两组:Point-wise 和 Channel-wise Transformers。此外,参考 Transformers 在 2D 图像处理中的探索 [87],可以根据操作形式将 Point-wise Transformers 进一步分为 Pair-wise 和 Patch-wise Transformers。前者通过相应的点云pair计算特征向量的注意力权重,而后者结合了给定patch中所有点云的信息。
目前,在 3D 点云处理领域还很少有patch-wise Transformer 研究。考虑到 patch-wise 的优势及其在图像处理中的出色表现,我们认为将 patch-wise Transformers 引入点云处理有利于性能提升。
8.1.2 Adaptive Set Abstraction
PointNet++ [4] 提出了一个集合抽象(Set Abstraction,SA)模块来分层提取点云的语义特征。它主要利用FPS和query ball grouping算法分别实现采样点云搜索和局部patch构建。然而,FPS 生成的采样点云倾向于均匀分布在原始点云中,而忽略了不同部分之间的几何和语义差异。例如,飞机尾部的几何形状比机身更复杂、更明显。因此,前者需要更多的采样点云来描述。此外,query ball grouping侧重于基于欧几里德距离搜索邻域点云,忽略了点云之间的语义特征差异,这使得具有不同语义信息的点云很容易分组到同一个局部patch中。因此,开发自适应集合抽象有利于提高 3D Transformer 的性能。最近,在 3D 领域有几种基于 Transformer 的方法探索自适应采样 [43]。但很少有人充分利用自注意力机制产生的丰富的短期和长期依赖关系。在图像处理领域,[143]中提出的Deformable Attention Transformer(DAT)通过引入偏移网络来生成deformed sampling points。它以低计算量在基准测试中取得了令人印象深刻的结果。提出一种基于自注意力机制的分层Transformer自适应采样方法将是有意义的。此外,受 2D 超像素 [144] 的启发,我们认为利用 3D Transformers 中的注意力图来获得用于点云oversegmentatio 的“superpoint”[145],将点云级 3D 数据转换为邻域级数据是可行。因此,这种自适应聚类技术可以用来代替query ball grouping方法。
8.1.3 Self-supervised Transformer Pre-training
Transformers 在 NLP 和 2D 图像任务上的成功很大程度上不仅来自于它们出色的可扩展性,还来自于大规模的自监督预训练[83]。Vision Transformer [17] 进行了一系列自监督实验,展示了自监督 Transformer 的潜力。在点云处理领域,尽管有监督的点云方法取得了重大进展,但点云标注仍然是一项劳动密集型任务。有限的标记数据集阻碍了监督方法的发展,特别是在点云分割任务方面。最近,已经提出了一系列自监督方法来处理这些问题,例如 2D 领域的生成对抗网络 (GAN) [146]、自动编码器 (AE) [147]、[148] 和高斯混合模型(GMM)[149]。这些方法使用自动编码器和生成式模型来实现自监督点云表示学习[96],并证明了自监督点云方法的有效性。然而,目前很少有自监督 Transformer 应用于 3D 点云处理。随着大规模 3D 点云的可用性越来越高,值得探索用于点云表示学习的自监督 3D Transformer。
8.2 总结
Transformer 模型在 3D 点云处理领域引起了广泛关注,并在各种 3D 任务中取得了令人瞩目的成果。本文全面回顾了最近应用于点云相关任务的基于 Transformer 的网络,例如点云分类、分割、目标检测、配准、采样、去噪、补全等实际应用。论文首先介绍了 Transformer 的理论,并描述了 2D 和 3D Transformer 的开发和应用。然后,论文利用三种不同的分类法将现有文献中的方法分为多组,并从多个角度对其进行分析。此外,论文还描述了一系列旨在提高性能和降低计算成本的自注意力变体。在点云分类、分割和目标检测方面,本文对所审查的方法进行了简要比较。最后,论文为 3D Transformer的发展提出了三个潜在的未来研究方向。希望本次调查能够让研究人员全面了解 3D 变形金刚,并激发他们进一步创新该领域研究的兴趣。
9 参考
[1] Transformers in 3D Point Clouds: A Survey
往期回顾
BEV最新综述 | 学术界和工业界方案汇总!优化方法与tricks
【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、规划控制、模型部署落地、自动驾驶仿真测试、硬件配置、AI求职交流等方向;
加入我们:自动驾驶之心技术交流群汇总!