PyTorch深度学习框架(一)
文章目录
- pytorch安装步骤
- pytorch基本使用方法
- view操作(改变矩阵维度)
- 格式转化(numpy<----->torch)
- 自动求导机制
-
- 例子实现
- 线性回归模型
- 常见的tensor格式
pytorch安装步骤
pip3 install torch torchvision torchaudio
pytorch基本使用方法
#创建一个矩阵
x=torch.empty(5,3)
print(x)
#来个随机数
y=torch.rand(5,3)
print(y)
#初始化全零矩阵
n=torch.zeros(5,3,dtype=torch.long)
print(n)
#矩阵的加法
w=torch.rand(5,3)
print(w+y)
view操作(改变矩阵维度)
#View操作
x=torch.randn(4,4)
y=x.view(16)
#-1 使用自动计算 ,第二个维度为8,第一个维度自动计算
z=x.view(-1,8)
print(x.size(),y.size(),z.size())
格式转化(numpy<----->torch)
#将torch格式转化为numpy格式
a=torch.ones(5)
b=a.numpy()
print(b)
#将numpy转为torch
a=np.ones(5)
b=torch.from_numpy(a)
print(b)
自动求导机制
#方法一
x=torch.randn(3,4,requires_grad=True)
#方法二
x=torch.randn(3,4)
x.requires_grad=True
print(x)
例子实现
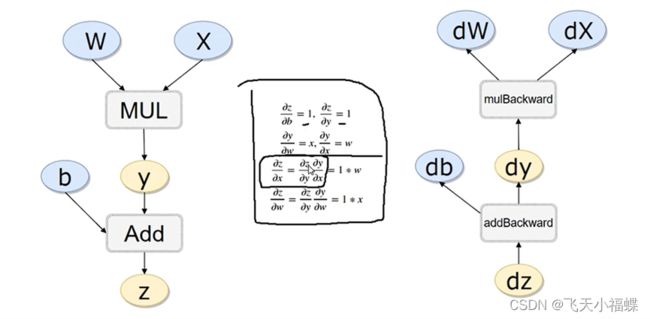
x=torch.rand(1)
b=torch.rand(1,requires_grad=True)
w=torch.rand(1,requires_grad=True)
y=w*x
z=y+b
#反向传播
z.backward(retain_graph=True)
print(b.grad)
线性回归模型
机器学习最常见的场景是监督学习:给定一些数据,使用计算学习到一种模型,然后使用它来预测新的数据。一个简单的监督学习任务可以表示为,给定N个两两数据对(Xi,Yi),使用某种机器学习模型对其进行建模,得到一个模型,其中某个给定的数据对为样本,X为特征,Y为真实值。
#coding=utf-8
from cProfile import label
from pickletools import optimize
from turtle import forward
import torch
import cv2
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
####构造数据集
#首先构造数据集,数据集的行表示预测值的数量,而列表示参数的自变量
x_value=[i for i in range(11)]
x_train=np.array(x_value,dtype=np.float32)
# 参数-1,表示模糊reshape的意思。
# 比如:reshape(-1,3),固定3列 多少行不知道。
x_train=x_train.reshape(-1,1)
y_value=[2*i+1 for i in x_value]
y_train=np.array(y_value,dtype=np.float32)
y_train=y_train.reshape(-1,1)
#建立线性回归模型
class LinearModel(nn.Module):
#input_dim 输入数据的维度 optput_dim 输出数据的维度
def __init__(self,input_dim,output_dim):
super(LinearModel,self).__init__()
self.linear=nn.Linear(input_dim,output_dim)
def forward(self,x):#前向传播函数,将当前的x值传进去输出y值
out=self.linear(x)
return out
#创建模型
model=LinearModel(1,1)
#创建损失函数
Loss=nn.MSELoss()
#创建优化函数0.01为学习率
optimizer=torch.optim.SGD(model.parameters(),lr=0.01)
#设置训练次数
number=1000
plt.ion()
#训练模型
for i in range(number):
i+=1
#转换数据类型
inputs=torch.from_numpy(x_train)
#标签
labels=torch.from_numpy(y_train)
#梯度要清零每一次迭代
optimizer.zero_grad()
#前向传播来计算每次的输出值,将用训练好的模型来将X值输入,预测Y值
outputs=model(inputs)
#计算误差,使用损失函数
loss=Loss(outputs,labels)
#根据损失函数返回的值来反向传播计算出k和b的值 y=kx+b
loss.backward()
#使用优化函数来更新权重参数
optimizer.step()
#使用坐标显示来显示预测的结果
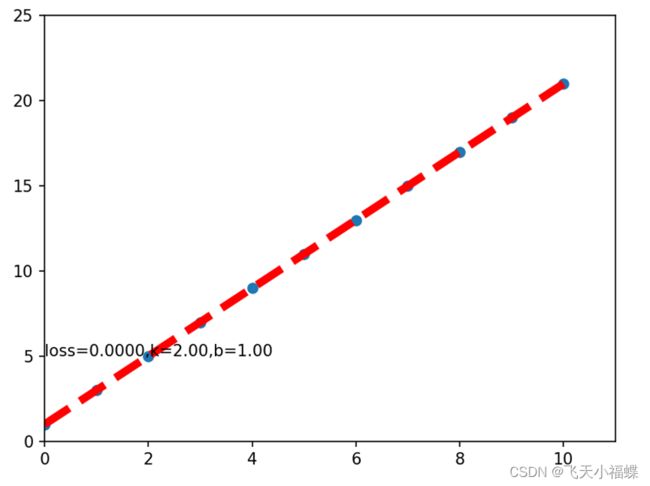
if i%100==0:
plt.cla()
plt.scatter(inputs.data.numpy(),labels.data.numpy())
plt.plot(inputs.data.numpy(), outputs.data.numpy(), 'r--', lw=5)
[w,b]=model.parameters()
plt.xlim(0,11)
plt.ylim(0,25)
plt.text(0,5,'loss=%.4f,k=%.2f,b=%.2f'%(loss.item(),w.item(),b.item()))
plt.pause(1)
plt.ioff()
plt.show()

常见的tensor格式
- 0:scalar
- 1:vector
- 2:matrix
- 3:n-dimensional tensor
#scalar通常是一个数值
x=tensor(42.)
w=2*x
print(w)
print(x)
print(x.item())
#vector 例如:【-5,2,0】在深度学习中通常指特征,例如词向量,某一维度特征等
v = tensor([1.4, -0.5, 3.0])
#输出维度
print(v.dim())
#输出大小
print(v.size())
#Matrix一般计算的都是矩阵,通常是多维的
M=tensor([[1,2],[3,4]])
print(M)
print(M.matmul(M))
print(tensor([1,0]).matmul(M))