论文笔记 Inter-sentence Relation Extraction with Document-level Graph Convolutional Neural Network
一、动机
为了抽取文档级别的关系,许多方法使用远程监督(distant supervision )自动地生成文档级别的语料,从而用来训练关系抽取模型。最近也有很多多实例学习(multi-instance learning)的方法被提出来解决这个问题。
跨句子的关系抽取不仅需要句子内部的依赖关系还需要句子之间的依赖关系。依存语法树(Dependency trees)可以很好处理句子内的关系抽取,但是无法处理跨句子的关系抽取。如下图,这是一个命名实体之间的非局部依赖关系,Oxytocin和Oxt之间是共指关系,也就是红色箭头表示的。而黄色箭头代表语义依赖关系。

文档级别的关系抽取需要处理各种各样的特征,局部的,非局部的,句法的,语法的信息。而已有的方法并没有充分利用这些信息,所以作者提出了一种基于图卷积神经网络(Graph Convolutional Neural Network)的模型去做文档级别的关系抽取。作者首先对文档进行图的构建,其中图中的节点代表单词,图中的边代表局部或非局部的特征。然后使用GCNN提取图的特征,最后使用多实例学习进行关系分类。
二、模型
模型的目标是抽取文档级别,也就是跨句子的关系抽取。假设一个文档 中有
中有 个单词,
个单词, 和
和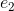 分别代表文档中的两个实体,也就是我们需要判断是否存在某种关系的一对实体。那这个任务输入为
分别代表文档中的两个实体,也就是我们需要判断是否存在某种关系的一对实体。那这个任务输入为![]() ,输出一个关系的类别,或者是“无关系“。
,输出一个关系的类别,或者是“无关系“。

整体模型结构如上图所示。模型的输入时整篇文档和两个实体的指称,然后对输入进行图的构建,接着使用GCNN提取图的特征。最后使用多实例学习进行关系分类。
2.1 节点特征
节点的特征表示分为三个部分,该单词本身表示,单词距离第一个实体的位置,单词距离第二个实体的位置。因为文档中包含多个实体的指称,只选最近的一个。
2.2 图的构建
图的构建由五大类特征构成
- Syntactic dependency edge. 使用句子内的依存语法树,每种依存关系作为一种类型的边
- Coreference edge. 共指边,代表两个指称描述同一个实体
- Adjacent sentence edge. 将相邻句子的依存语法树根节点连接构成一种类型的边
- Adjacent word edge. 相邻的单词
- Self-node edge. 自反边
2.3 GCNN
为了能够捕捉不同类型边的特征,作者使用带标签的GCNN[paper]去单独学习不同类型边的图,这样可以保留更加丰富的信息。由于五大类特征中还包含各种类型的边,这样的话图的数量过多容易过拟合。作者在进行创建图的时候只选择top-N类型的边进行训练,其他类型的边全部作为"rare"进行训练。
2.4 多实例学习
因为一个实体可能在一篇文章中出现多次,所以这里使用多实例学习进行关系分类。作者借助bi-affine pairwise scoring [paper]模型对文章中出现的所以单词对进行打分,从而预测关系类别。bi-affine是一种self-attention编码器,可以一次计算出文档中所有mention之间的关系。
三、 实验
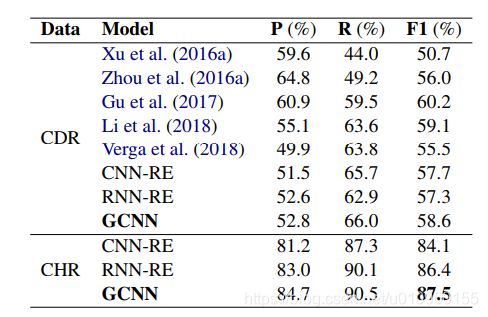
作者在Chemical-Disease Relations dataset (CDR)和CHemical Reactions dataset (CHR)上进行了实验,结果如下表所示。GCNN的在两个数据集上表现比CNN-RE和RNN-RE都要高,证明了这个模型的有效性。在CDR上GCNN比(Gu et al., 2017)的模型要低1.6个百分点,但是这个模型对局内和句间的关系使用了两个模型,GCNN仅使用了一个模型就搞定了。
作者尝试对top-N这个参数进行调整,选取不同数量的类型的边进行对比。实验结果如下表,在边的类型数量等于4的时候F1分数达到峰值,再增加边的类型之后效果开始下降。所以作者使用top-4种边加上rare边进行后面的实验。这里有个问题是既然只选择了top-4种边,那是不是说明想排名第10的共指关系就没有用了?我觉得共指关系可以用来消歧,对于判断句间关系还是非常有用的。

最后作者还做了ablation analysis,为了分析不同类型的边分别对句内和句间关系的影响,作者把数据集进行了拆分。Intra是句内关系数据集,Inter是句间关系数据集。结果如下表,其中所以的类型边对局内关系都有影响。对于句间关系来说,dependency这种类型的边比较关键。

四、结论
作者提出了一种非常新颖的基于图方法的文档级别关系抽取模型。作者把文档中的单词作为节点,把依存关系、邻接关系、共指关系等等句内和句间的信息构建成节点和节点之间的边,然后使用带标签的GCNN对不同类型边的图提取特征,最终使用一种bi-affine模型对每一对节点进行关系打分,从而可以预测关系的类别。
这种GCNN关系抽取模型目前应该还没人做过,这篇文章给了我们另外一种角度来做关系抽取。同时我认为还有几点疑问,首先,对于节点的表示,作者只使用了单词本身加上position特征,是不是还可以加上其他的特征丰富节点的表示呢?其次,作者构建了很多种类型的边,最后只选择top-4,那是不是说模型本身过于复杂了呢?能不能再对这部分进行简化呢,把所有边融合成一个带权重的边?判断每种类型的关系所需要特征也是不同的,是不是应该对每种边区别对待? 另外一点,对所有文档所有的mention对都进行打分是不是浪费呢,我们只需要对我们关注的实体对进行打分就可以了。