开放集域适应文献阅读二
Open Set Domain Adaptation by Backpropagation 基于反向传播的开集域适应
- 1 本文贡献
- 2 方法
-
- 2.1 总体构想
- 2.2 训练程序
- 2.3 与现有方法的比较
- 3 小结
- 参考文献
1 本文贡献
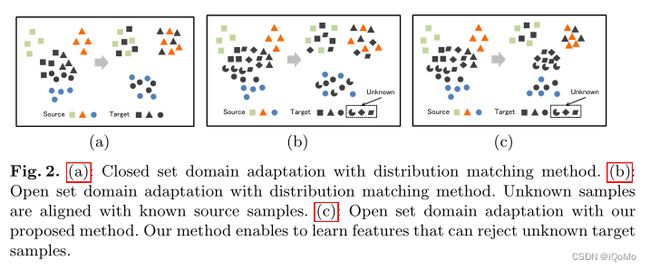
- 提出了一种更具挑战性的不提供任何未知源样本的开放集域自适应(OSDA).
- 提出了一种利用对抗性训练的开放集域自适应场景的方法. 分类器被训练为在源样本和目标样本之间形成边界,而生成器被训练为使目标样本远离边界.
- 评估了我们的数字和对象数据集自适应方法,并证明了其有效性.
2 方法
2.1 总体构想
一组标记的源图像 { X s , Y s } \left\{X_s,Y_s\right\} {Xs,Ys}.
未标记的目标图像 X t X_t Xt.
源图像仅从已知类绘制,而目标图像可以从未知类绘制。作者训练了一个特征生成网络 G G G,它接收输入 x s x_s xs 或 x t x_t xt,以及一个网络 C C C,它从 G G G 中获取特征并将其分类为 K + 1 K+1 K+1 类,其中 K K K 表示已知类别的数量。因此, C C C 每一个样本输出一个对数 { l 1 , l 2 , l 3 , … , l K + 1 } \left\{l_1, l_2,l_3,\ldots, l_{K+1}\right\} {l1,l2,l3,…,lK+1} 的 K + 1 K+1 K+1 维向量。
然后通过应用softmax函数将逻辑转换为类概率.
p ( y = j ∣ x ) = exp ( l j ) ∑ k = 1 K + 1 exp ( l k ) p(y=j \mid \boldsymbol{x})=\frac{\exp \left(l_j\right)}{\sum_{k=1}^{K+1} \exp \left(l_k\right)} p(y=j∣x)=∑k=1K+1exp(lk)exp(lj)
作者建议通过弱训练分类器来为未知类建立伪决策边界,以将目标样本识别为未知类. 然后训练一个特征生成器来欺骗分类器. 重要的是,特征生成器必须将未知目标样本与已知目标样本分离.
作者训练分类器输出 p ( y = K + 1 ∣ x t ) = t p\left(y=K+1 \mid \boldsymbol{x}_t\right) = t p(y=K+1∣xt)=t,其中 0 < t < 1 0
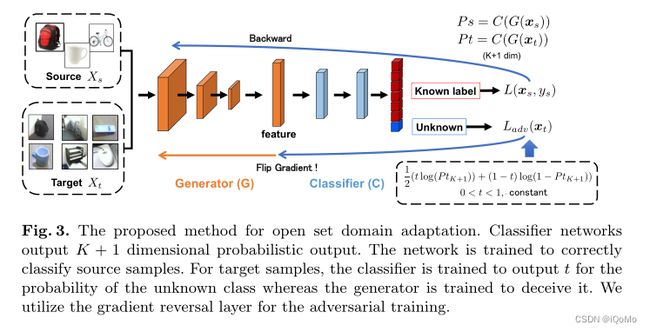
2.2 训练程序
首先,我们训练分类器和生成器来正确地对源样本进行分类. 为此,我们使用标准交叉熵损失.
L s ( x s , y s ) = − log ( p ( y = y s ∣ x s ) ) p ( y = y s ∣ x s ) = ( C ∘ G ( x s ) ) y s \begin{aligned} L_s\left(\boldsymbol{x}_s, y_s\right) &=-\log \left(p\left(y=y_s \mid \boldsymbol{x}_s\right)\right) \\ p\left(y=y_s \mid \boldsymbol{x}_s\right) &=\left(C \circ G\left(\boldsymbol{x}_s\right)\right)_{y_s} \end{aligned} Ls(xs,ys)p(y=ys∣xs)=−log(p(y=ys∣xs))=(C∘G(xs))ys
为了训练分类器为未知样本建立边界,提出利用二元交叉熵损失. t t t 设置为0.5.
L a d v ( x t ) = − t log ( p ( y = K + 1 ∣ x t ) ) − ( 1 − t ) log ( 1 − p ( y = K + 1 ∣ x t ) ) L_{a d v}\left(\boldsymbol{x}_t\right)=-t \log \left(p\left(y=K+1 \mid \boldsymbol{x}_t\right)\right)-(1-t) \log \left(1-p\left(y=K+1 \mid \boldsymbol{x}_t\right)\right) Ladv(xt)=−tlog(p(y=K+1∣xt))−(1−t)log(1−p(y=K+1∣xt))
对于分类器,首先对于source数据要做优化,使得分类效果达到最好;对于target域的数据他想要将其概率固定为 t t t ,所以最小化器loss函数
对于特征提取器,首先对于source数据要要做优化,使得分类效果达到最好;对于target域的数据他想要将其概率远离为 t t t ,所以最大化器loss函数
min C L s ( x s , y s ) + L a d v ( x t ) min G L s ( x s , y s ) − L a d v ( x t ) \begin{aligned} &\min _C L_s\left(\boldsymbol{x}_s, y_s\right)+L_{a d v}\left(\boldsymbol{x}_t\right) \\ &\min _G L_s\left(\boldsymbol{x}_s, y_s\right)-L_{a d v}\left(\boldsymbol{x}_t\right) \end{aligned} CminLs(xs,ys)+Ladv(xt)GminLs(xs,ys)−Ladv(xt)
算法如Alg.1

2.3 与现有方法的比较
与现有方法相比,有三个主要区别.
- 大多数现有方法在训练期间无法访问未知样本,因此它们无法训练特征提取器学习特征以拒绝它们. 该方法中,未知目标样本包含在训练样本中,尽管我们不知道哪些是未知样本. 在这种情况下,我们的方法可以训练特征提取器以拒绝未知样本.
- 如果测试样本的任何已知类别的概率不大于阈值,则现有方法拒绝未知样本. 然而,该方法中可以考虑阈值在样本之间变化,因为模型将不同的分类输出分配给不同的样本.
- 特征提取器形成已知类和未知类之间的伪决策边界. 因此,特征提取器可以识别每个目标样本与未知类别的边界之间的距离. 它试图使它远离边界. 进而表示,使得与已知源样本相似的样本与已知类对齐,而与已知源样本不同的样本与它们分离.
3 小结
本文提出了一种新的用于开集域适应的对抗性学习方法. 提出的方法能够生成能够从已知目标样本中分离未知目标样本的特征. 此外,该方法不需要未知的源样本.
参考文献
[1] Saito, K., Yamamoto, S., Ushiku, Y., Harada, T. (2018). Open Set Domain Adaptation by Backpropagation. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds) Computer Vision – ECCV 2018. ECCV 2018. Lecture Notes in Computer Science(), vol 11209. Springer, Cham. https://doi.org/10.1007/978-3-030-01228-1_10
[2] https://blog.csdn.net/qq_42935317/article/details/125077525