tensorflow1.14(二、线性回归)
- 模型构造
- y = w1x1 + w2x2 + …… + wnxn + b
def linear_regression():
# 1)准备数据 (b,1)*(1,1)+(b,1)=(b,1)
x = tf.random_normal(shape=[100,1])
y = tf.matmul(x,[[0.8]])+0.7 # + tf.random_normal(shape=(100,1),mean=0,stddev=2)
# 2)构建模型: pre = wx+b
w = tf.Variable(initial_value=tf.random_normal(shape=[1,1]))
b = tf.Variable(initial_value=tf.random_normal(shape=[1,1]))
pre = tf.matmul(x, w) + b
# 3)构建损失函数
error = tf.reduce_mean(tf.square(pre - y))
# 4)优化损失
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(error)
# 显示的初始化变量
init = tf.global_variables_initializer()
with tf.Session() as sess:
# 初始化变量
sess.run(init)
# 查看初始化模型参数之后的值
print("训练前模型参数:权重:{}, 偏置:{}, 损失{}".format(w.eval(),b.eval(),error.eval()))
for i in range(20):
sess.run(optimizer) # 20次迭代
print("第{}次迭代:权重:{}, 偏置:{}, 损失{}".format(i,w.eval(),b.eval(),error.eval()))
训练前模型参数:权重:[[2.7860873]], 偏置:[[0.5858318]], 损失4.225954532623291
训练后模型参数:权重:[[2.498422]], 偏置:[[0.63118255]], 损失2.6924474239349365
第0次迭代:权重:[[1.9762952]], 偏置:[[0.66247046]], 损失1.2378976345062256
第1次迭代:权重:[[1.7262127]], 偏置:[[0.7035602]], 损失0.7215265035629272
第2次迭代:权重:[[1.5517955]], 偏置:[[0.70261407]], 损失0.5045949220657349
第3次迭代:权重:[[1.4412438]], 偏置:[[0.6986025]], 损失0.5488945245742798
第4次迭代:权重:[[1.3343186]], 偏置:[[0.6890503]], 损失0.27704915404319763
第5次迭代:权重:[[1.219361]], 偏置:[[0.7189504]], 损失0.16666652262210846
第6次迭代:权重:[[1.127513]], 偏置:[[0.7296285]], 损失0.12387548387050629
第7次迭代:权重:[[1.0769757]], 偏置:[[0.7185438]], 损失0.08834923803806305
第8次迭代:权重:[[1.0163614]], 偏置:[[0.70607823]], 损失0.0467718280851841
第9次迭代:权重:[[0.9667892]], 偏置:[[0.7096984]], 损失0.03674754500389099
第10次迭代:权重:[[0.92438364]], 偏置:[[0.7068214]], 损失0.01663968153297901
第11次迭代:权重:[[0.90252656]], 偏置:[[0.70708495]], 损失0.010061804205179214
第12次迭代:权重:[[0.8791434]], 偏置:[[0.70702046]], 损失0.007077415473759174
第13次迭代:权重:[[0.85823107]], 偏置:[[0.70000976]], 损失0.0033408307936042547
第14次迭代:权重:[[0.8477356]], 偏置:[[0.7005515]], 损失0.0018498379504308105
第15次迭代:权重:[[0.83848387]], 偏置:[[0.69818467]], 损失0.001512147136963904
第16次迭代:权重:[[0.83182824]], 偏置:[[0.69745255]], 损失0.0010836065048351884
第17次迭代:权重:[[0.8263948]], 偏置:[[0.69765127]], 损失0.0005920935072936118
第18次迭代:权重:[[0.8207227]], 偏置:[[0.6983424]], 损失0.0005448741721920669
第19次迭代:权重:[[0.8165649]], 偏置:[[0.69819295]], 损失0.00021598335297312587
梯度爆炸:将学习率设为5
optimizer = tf.train.GradientDescentOptimizer(learning_rate=5).minimize(error)训练前模型参数:权重:[[-0.31440303]], 偏置:[[1.1995844]], 损失1.9203598499298096
第0次迭代:权重:[[13.122035]], 偏置:[[-4.5861564]], 损失148.15634155273438
第1次迭代:权重:[[-100.883385]], 偏置:[[42.844555]], 损失12464.6748046875
第2次迭代:权重:[[926.3107]], 偏置:[[-420.73428]], 损失1035411.5
第3次迭代:权重:[[-9535.682]], 偏置:[[5244.104]], 损失108928880.0
第4次迭代:权重:[[66559.53]], 偏置:[[-30004.014]], 损失5988559872.0
第5次迭代:权重:[[-617555.]], 偏置:[[274763.22]], 损失454119260160.0
第6次迭代:权重:[[6054924.5]], 偏置:[[-1919577.]], 损失35131280588800.0
第7次迭代:权重:[[-57414068.]], 偏置:[[15101759.]], 损失3356088787271680.0
第8次迭代:权重:[[6.617444e+08]], 偏置:[[-2.7006243e+08]], 损失6.246740623034941e+17
第9次迭代:权重:[[-5.625376e+09]], 偏置:[[2.1763274e+09]], 损失3.682285771947403e+19
第10次迭代:权重:[[5.270209e+10]], 偏置:[[-2.841315e+10]], 损失3.339414057145642e+21
第11次迭代:权重:[[-3.2529764e+11]], 偏置:[[2.1325236e+11]], 损失1.664679581495794e+23
第12次迭代:权重:[[3.1254614e+12]], 偏置:[[-1.3837785e+12]], 损失1.0438847603537076e+25
第13次迭代:权重:[[-2.881967e+13]], 偏置:[[1.0862224e+13]], 损失1.1966633095981426e+27
第14次迭代:权重:[[2.5069528e+14]], 偏置:[[-7.718792e+13]], 损失8.043711666807786e+28
第15次迭代:权重:[[-1.9097564e+15]], 偏置:[[2.0037026e+14]], 损失4.0406042516932614e+30
第16次迭代:权重:[[1.6180741e+16]], 偏置:[[-1.5317987e+15]], 损失2.2738873366418764e+32
第17次迭代:权重:[[-1.3484184e+17]], 偏置:[[-4.1298588e+15]], 损失1.8536909196499127e+34
第18次迭代:权重:[[1.14388826e+18]], 偏置:[[9.229123e+16]], 损失1.2232093054854281e+36
第19次迭代:权重:[[-1.1798036e+19]], 偏置:[[-1.6922009e+18]], 损失inf
变量参数:
# trainable = True 能否被训练
w = tf.Variable(initial_value=tf.random_normal(shape=[1,1]),trainable=False)增加其他功能(变量TensorBoard显示与模型保存)
- 增加变量显示
# 增加变量显示 函数讲解
(数据准备后)
# 1. 低纬变量收集:loss
tf.summary.scalar("loss", error)
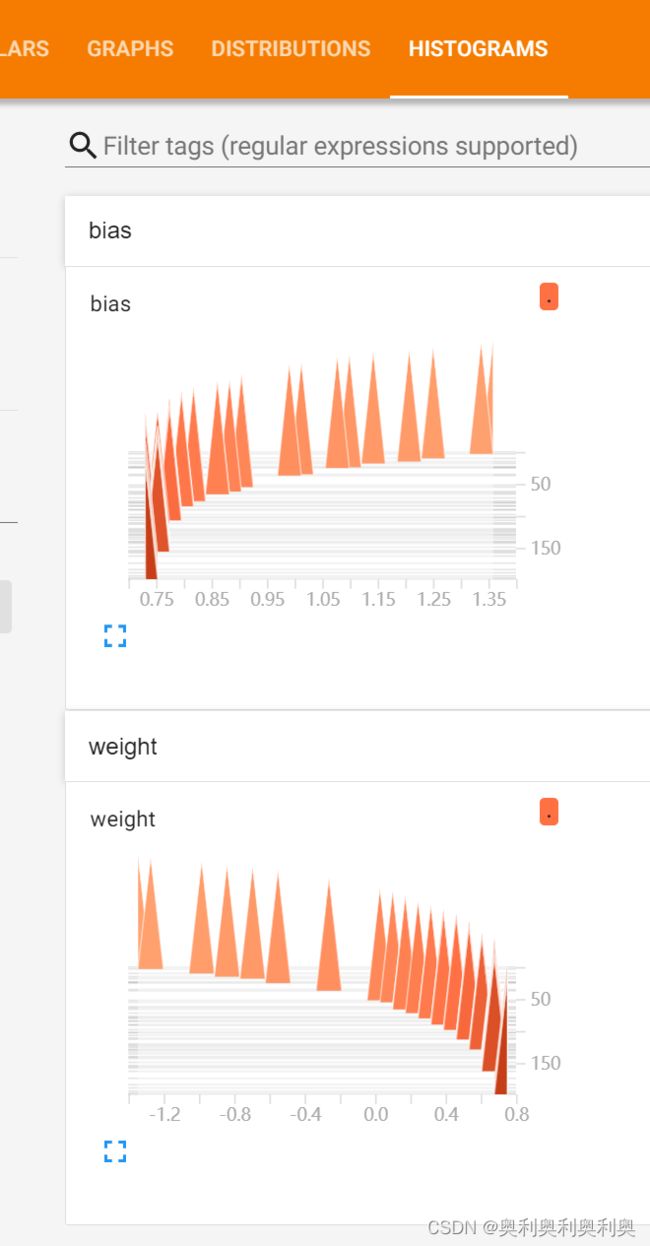
# 2. 高纬变量收集:w、b
tf.summary.histogram("weight", w)
# 3. 合并变量
merged = tf.summary.merge_all()
(创建视图时)
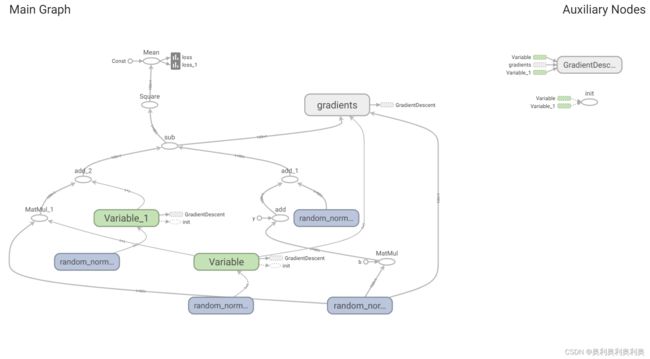
# 4. 创建事件文件:需要用到graph
file_write = tf.summary.FileWriter("./linear",graph=sess.graph)
(迭代训练时)
# 5. 运行合并变量操作
summary = sess.run(merged)
# 6. 将每次迭代后的变量写入事件文件
file_write.add_summary(summary, i)
# 7. 终端运行:>>>tensorboard --logdir="./Demo01/linear/"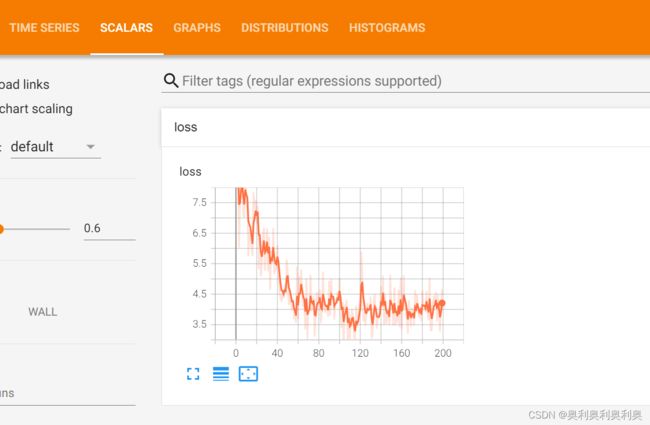
完整代码:
def linear_regression():
# 1)准备数据 y = 0.8*x+0.7周围的点 (b,1)*(1,1)+(b,1)=(b,1)
x = tf.random_normal(shape=[100,1])
y = tf.matmul(x,[[0.8]])+0.7 + tf.random_normal(shape=(100,1),mean=0,stddev=2)
# 2)构建模型: pre = wx+b
w = tf.Variable(initial_value=tf.random_normal(shape=[1,1]))
b = tf.Variable(initial_value=tf.random_normal(shape=[1,1]))
pre = tf.matmul(x, w) + b
# 3)构建损失函数
error = tf.reduce_mean(tf.square(pre - y))
# 4)优化损失
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(error)
#收集变量####################################################
# tf.summary.scalar("weight", w)
tf.summary.scalar("loss", error)
# tf.summary.scalar("bias", b)
tf.summary.histogram("weight", w)
# tf.summary.histogram("loss", error)
tf.summary.histogram("bias", b)
# 合并变量####################################################
merged = tf.summary.merge_all()
# 显示的初始化变量
init = tf.global_variables_initializer()
with tf.Session() as sess:
# 初始化变量
sess.run(init)
# 查看初始化模型参数之后的值
print("训练前模型参数:权重:{}, 偏置:{}, 损失{}".format(w.eval(),b.eval(),error.eval()))
# 创建事件文件##############################################################
file_write = tf.summary.FileWriter("./linear",graph=sess.graph)
for i in range(200):
sess.run(optimizer) # 20次迭代
print("第{}次迭代:权重:{}, 偏置:{}, 损失{}".format(i,w.eval(),b.eval(),error.eval()))
# 运行合并变量操作#################################
summary = sess.run(merged)
# 将每次迭代后的变量写入事件文件#####################
file_write.add_summary(summary, i)
# 终端运行:>>>tensorboard --logdir="./Demo01/linear/"
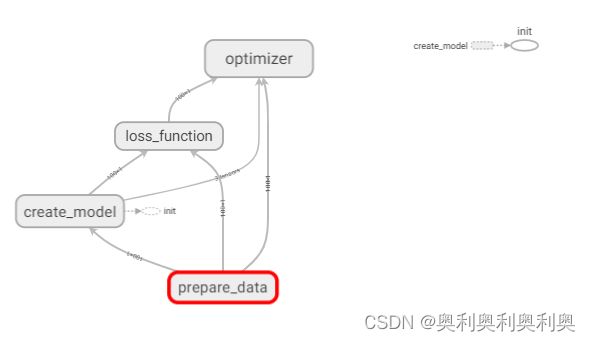
2. 增加命名空间,使得代码结构更加清晰,Tensorboard图结构更加清楚。
with tf.variable_scope("lr_model"):
#实例:分成四个命名空间
with tf.variable_scope("prepare_data"):
# 1)准备数据 y = 0.8*x+0.7周围的点 (b,1)*(1,1)+(b,1)=(b,1)
x = tf.random_normal(shape=[100,1],name="feature")
y = tf.matmul(x,[[0.8]])+0.7 + tf.random_normal(shape=(100,1),mean=0,stddev=2)
with tf.variable_scope("create_model"):
# 2)构建模型: pre = wx+b
w = tf.Variable(initial_value=tf.random_normal(shape=[1,1]),name="W")
b = tf.Variable(initial_value=tf.random_normal(shape=[1,1]),name="B")
pre = tf.matmul(x, w) + b
with tf.variable_scope("loss_function"):
# 3)构建损失函数
error = tf.reduce_mean(tf.square(pre - y),name="Loss")
with tf.variable_scope("optimizer"):
# 4)优化损失
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(error)优化后:
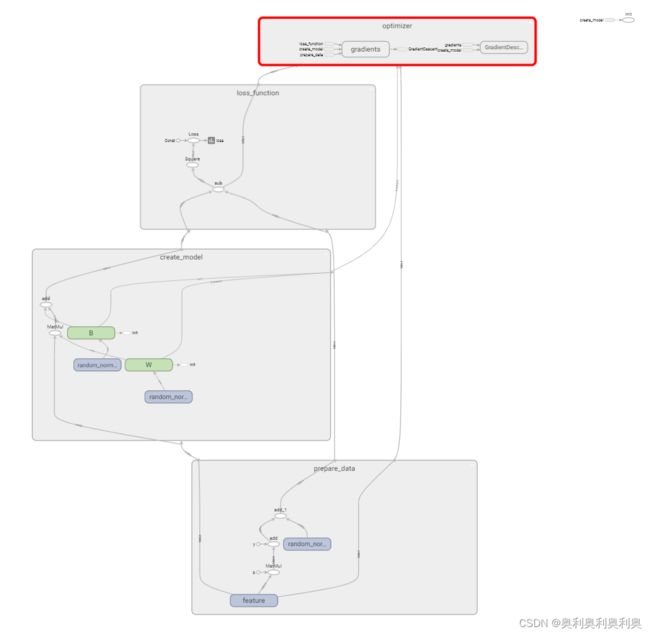
3. 模型的保存与加载
# 实例化对象
saver = tf.train.Saver()
# 保存:
# 1. 可以在迭代下降中循环N次保存一次(数据大防止断电)
# 2. 可以在迭代下降后保存(适合小数据,方便预测)
saver.save(sess, save_path="../model/my_linear.ckpt")
# 加载模型:修改变量值(按照保存的参数),依靠参数名(命名空间+变量名),因此命名空间+变量名要与保存的的一致
if os.path.exists("../model/checkpoint"):
saver.restore(sess, "../model/my_linear.ckpt")
4. 命令行参数的使用
略