GLAMD: Global and Local Attention Mask Distillation for Object Detectors
全局-局部 注意力的mask蒸馏
传统KD关注fore,而忽视的backg,关注全局,忽略local。本文GLAMD,提取了全局+局部,将future map 分为 几个 patch,并对global和 patch使用attention。
introduction
GLAMD通过对按patch划分的全局和局部特征应用 注意力机制来创建 全局+局部 注意力掩码。然后将生成的mask应用于 中间特征、分类输出和回归输出,以更有效的提取教师的知识。

图1展示了前面的全局注意力方法和我们的基于patch的注意力方法生成的注意力掩码。与图1 ( b )中只关注一个人的全局注意力掩码相比,图1 ( c )中我们的方法生成的local patch掩码覆盖了其他信息对象,如人和自行车。由于掩码是通过在全局和局部级别应用注意力机制生成的,因此在本文中,我们将所提议的掩码称为全局和局部注意力掩码( GLAM )。通过提出的GLAM,我们的方法联合考虑了来自背景和前景的详细信息。
3 methods
传统的全局注意力机制 只在乎了某一个区域,这是因为全局注意力mask突出单个spot,忽略其他局部细节,本文提出 一个新颖的mask,它反映 全局-局部 特征,如图二所示,可用于future和head蒸馏。
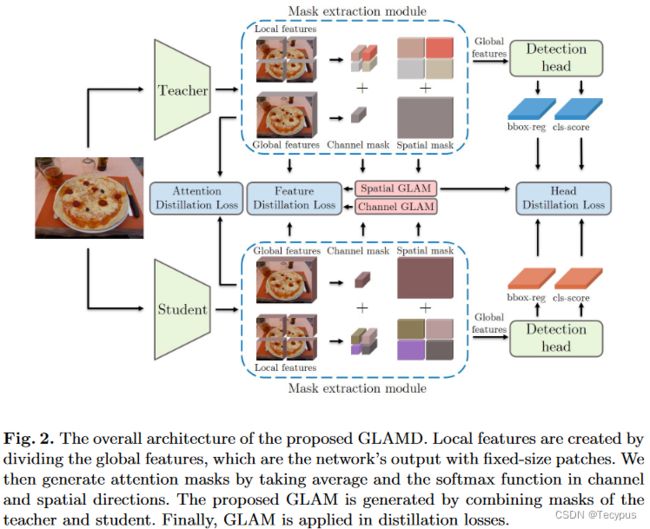
图2 局部特征通过分割全局特征来创建,这些特征是具有固定大小的patch的网络输出。然后,通过在channel和spatial方向上取平均值和softmax函数来生成注意力掩码。提议的GLAM是由教师和学生的masks组合生成。最后,将GLAM应用于蒸馏损失中。
3.1 Global and Local Attention Mask (GLAM)
GLAMD的核心组成部分GLAM,其中使用的注意力方法是通道+空间注意力方法,记为 ![]() 。为了获得channel注意力mask,在通道维度上的 softmax操作中 使用 绝对特征元素
。为了获得channel注意力mask,在通道维度上的 softmax操作中 使用 绝对特征元素 ![]() 的spatial-wise 平均。
的spatial-wise 平均。

其中τ和σ ( · )分别表示temperature参数和softmax操作,H和W分别表示输入特征的高度和宽度。
为了获得空间注意力掩码,在宽度和高度维度上的softmax操作中使用绝对特征元素![]() 的通道平均,如下所示:
的通道平均,如下所示:

C为输入特征的维度。
为考虑全局和局部视角的GLAM,将FPN的每个输出特征 split 为 N个局部特征,![]() ,其中,p是patch大小,n属于1到N,局部channel mask
,其中,p是patch大小,n属于1到N,局部channel mask ![]() 和局部spatial mask
和局部spatial mask ![]() 设定如下:
设定如下:
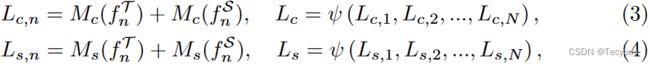
其中T和S分别表示教师和学生,ψ表示concatenation操作。
类似地,给定一个全局特征![]() ,global channel mask Gc 和 global spatial mask Gs 计算如下:
,global channel mask Gc 和 global spatial mask Gs 计算如下:
![]()
通过合并局部掩码和全局掩码,我们的最终通道和空间注意力掩码(分别记为Tc和Ts )构造如下:

3.2 Feature Distillation
从FPN中提取中间特征来提高学生 成绩,每个stage中的特征与相应的 通道和空间 注意力mask 相乘,以选择性的提取感兴趣的区域,特征蒸馏损失定义为:

其中L为FPN stage number,函数![]() 为1 × 1卷积适应层,将学生特征尺寸与教师特征尺寸相匹配(L2 距离)。并且,
为1 × 1卷积适应层,将学生特征尺寸与教师特征尺寸相匹配(L2 距离)。并且,![]() 分别表示第L stage 的 空间和通道 masks。
分别表示第L stage 的 空间和通道 masks。
又 提取了attention特征来鼓励学生产生更有效的GLAM。因此,通道和空间注意力特征的提取过程可以表示为![]() 和
和![]() 。channel注意力损失计算:通过提取全局和局部通道注意力特征。
。channel注意力损失计算:通过提取全局和局部通道注意力特征。
全局和局部空间注意力特征等价,因为局部特征是通过将全局特征划分到空间域而形成的。因此,与通道注意损失相比,空间注意损失只利用了全局空间注意特征。因此,我们提出的通道注意力损失Lcat和空间注意力损失Lsat可以表示如下:
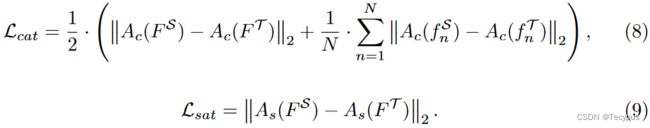
最后,整体特征注意力损失由通道和空间注意力损失之和来表示,具体如下![]()
3.3 Head Distillation
response-based 的蒸馏鼓励学生的输出模仿老师的输出。然而,由于目标检测任务中前景和背景之间的不平衡,直接提取教师的头部输出会对学生的表现造成不利影响。因此,我们在执行基于响应的蒸馏时应用了 spatial attention masks。特别地,我们使用来自方程6( )中相同FPN阶段的the spatial attention masks 进行the masked head distillation。分类头损失
)中相同FPN阶段的the spatial attention masks 进行the masked head distillation。分类头损失![]() 可以定义如下:
可以定义如下:

其中,![]() 分别表示学生和教师分类头的输出,
分别表示学生和教师分类头的输出,![]() 表示二元交叉熵损失。 l是FPN的 stage。Ts,l 的s是 spatial,l是FPN的stage。
表示二元交叉熵损失。 l是FPN的 stage。Ts,l 的s是 spatial,l是FPN的stage。
为了避免 教师的某些无界输出会为学生模型提供不正确的指导,使用IoU损失来蒸馏localization head。对于localization head distillation,我们使用IoU损失来设定其损失如下:
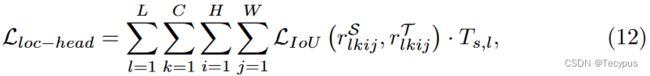
其中r是 the localization head output
总结:
蒸馏分特征蒸馏和 head蒸馏。
首先定义了GLAM,即全局-局部下的注意力mask。 Mc 和 Ms。
考虑全局和局部
首先看局部,Ls,n Lc,n
全局, Gs, Gc
综合起来,就是Ts,Tc
介绍完构造,再看两种蒸馏:
特征蒸馏:
定义为公式7所示,FPN每一阶段的特征提出来, L2距离*Ts*Tc 开根号。
继续引入注意力,
L (c at) =
L (s at) =
最后 Lat =
Head蒸馏:
同公式6
Lcls-head
Lloc-head
本质创新上就是提出了GLAM,结合了FPN+注意力,提出了两种方式的蒸馏结合