极智AI | 谈谈 caffe 的 conv 算子
欢迎关注我的公众号 [极智视界],获取我的更多笔记分享
O_o >_< o_O O_o ~_~ o_O
本文主要聊一下 caffe 框架中的 conv 算子。
caffe 中的卷积主要有两种实现:一种是 img2col + gemm + bias,另一种是调用 cudnn_conv,关于 img2col 加速卷积计算的原理可以参考我之前写的这篇 《【模型推理】一文看懂Img2Col卷积加速算法》,这篇文章里写的比较清楚了。下面进行 caffe 中 conv 实现的介绍。
文章目录
-
- 1、caffe conv img2col + gemm + bias
-
- 1.1 conv forward
- 1.2 gemm forward
- 1.3 bias forward
- 2、caffe cudnn conv
1、caffe conv img2col + gemm + bias
跟 caffe conv img2col + gemm + bias 相关的几个 cpp 有:conv_layer.cpp、base_conv_layer.cpp、im2col.cpp、math_functions.cpp,以 forward_cpu 为例,这个时候的 conv 调用流程如下:

可以看到如上调用过程其实是单卷积算子,不是算子融合的情况,把 gemm 和 bias 的计算分开了,简单来看一下原理(下面的这组图在我的这篇文章里有《【模型推理】谈谈为什么卷积加速更喜欢 NHWC Layout》):
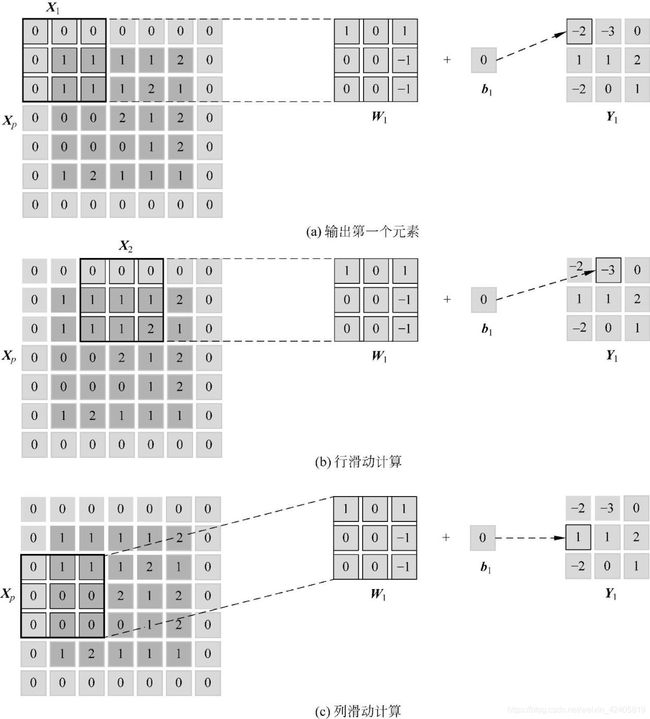
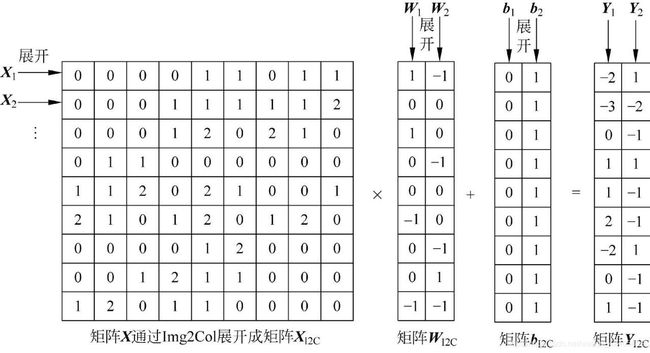
原理过程很清晰,下面来看实现,逻辑按照上面的调用图。
1.1 conv forward
这是 caffe conv 算子最顶层实现,主要看 include/caffe/layers/conv_layer.hpp 头 和 src/caffe/layers/conv_layer.cpp 实现。让我们先来看一下头:
/// conv_layer.hpp
template
class ConvolutionLayer : public BaseConvolutionLayer {
public:
explicit ConvolutionLayer(const LayerParameter& param)
: BaseConvolutionLayer(param) {}
virtual inline const char* type() const { return "Convolution"; }
protected:
virtual void Forward_cpu(const vector*>& bottom,
const vector*>& top);
virtual void Forward_gpu(const vector*>& bottom,
const vector*>& top);
virtual void Backward_cpu(const vector*>& top,
const vector& propagate_down, const vector*>& bottom);
virtual void Backward_gpu(const vector*>& top,
const vector& propagate_down, const vector*>& bottom);
virtual inline bool reverse_dimensions() { return false; }
virtual void compute_output_shape();
};
可以看到前向推理几个关键的函数:Forward_cpu、Forward_gpu。先看 Forward_cpu 的实现:
template
void ConvolutionLayer::Forward_cpu(const vector*>& bottom,
const vector*>& top) {
const Dtype* weight = this->blobs_[0]->cpu_data();
for (int i = 0; i < bottom.size(); ++i) {
const Dtype* bottom_data = bottom[i]->cpu_data();
Dtype* top_data = top[i]->mutable_cpu_data();
for (int n = 0; n < this->num_; ++n) {
/// compute gemm
this->forward_cpu_gemm(bottom_data + n * this->bottom_dim_, weight,
top_data + n * this->top_dim_);
/// compute bias
if (this->bias_term_) { /// 有 bias 的话
const Dtype* bias = this->blobs_[1]->cpu_data();
this->forward_cpu_bias(top_data + n * this->top_dim_, bias);
}
}
}
}
这里两个关键的操作是 this->forward_cpu_gemm、this->forward_cpu_bias。关于 this 指针有一个比较经典的回答,当你进入一个房子后,你可以看见桌子、椅子、电视等,但是房子这个整体你却看不完整,对于一个类的实例来说,你可以看到它的成员函数、成员变量,但是实例本身呢?this 是一个指针,它时刻指向你这个示例本身。所以,拿 this->forward_cpu_gemm 来说,咋一看找不到 forward_cpu_gemm 的实现在哪里,结合对 this 指针的理解,然后再看一下ConvolutionLayer 类的声明:
class ConvolutionLayer : public BaseConvolutionLayer {...}
可以看到 ConvolutionLayer 类为 BaseConvolutionLayer 类的派生类,继承方式为 public,公有继承时基类的公有成员和保护成员被继承到派生类中仍作为派生类的公有成员和保护成员,看到这里可能就豁然开朗了,若 BaseConvolutionLayer 类中有 forward_cpu_gemm,这样就捋顺了。来看下 BaseConvolutionLayer 的声明:
template
class BaseConvolutionLayer : public Layer {
public:
...
protected:
void forward_cpu_gemm(const Dtype* input, const Dtype* weights,
Dtype* output, bool skip_im2col = false);
void forward_cpu_bias(Dtype* output, const Dtype* bias);
...
}
可以看到如我们所愿,确实有 forward_cpu_gemm、forward_cpu_bias,这里已经跳转到了 include/caffe/layers/base_conv_layer.hpp,这个我们下面再看。
以上我们看了 conv_forward_cpu 的实现,再来看看 conv_forward_gpu 的实现:
template
void ConvolutionLayer::Forward_gpu(const vector*>& bottom,
const vector*>& top) {
const Dtype* weight = this->blobs_[0]->gpu_data();
for (int i = 0; i < bottom.size(); ++i) {
const Dtype* bottom_data = bottom[i]->gpu_data();
Dtype* top_data = top[i]->mutable_gpu_data();
for (int n = 0; n < this->num_; ++n) {
this->forward_gpu_gemm(bottom_data + n * this->bottom_dim_, weight,
top_data + n * this->top_dim_);
if (this->bias_term_) {
const Dtype* bias = this->blobs_[1]->gpu_data();
this->forward_gpu_bias(top_data + n * this->top_dim_, bias);
}
}
}
}
已经封装的和 conv_forward_cpu 看起来差不多了,主要是 this->forward_gpu_gemm、this->forward_gpu_bias,这个同样指向了 include/caffe/layers/base_conv_layer.hpp,下一节见分晓。
在 ConvolutionLayer 类的声明中注意到还有个接口 compute_output_shape,这个函数主要用于计算输出特征的 shape,其实现如下:
template
void ConvolutionLayer::compute_output_shape() {
const int* kernel_shape_data = this->kernel_shape_.cpu_data();
const int* stride_data = this->stride_.cpu_data();
const int* pad_data = this->pad_.cpu_data();
const int* dilation_data = this->dilation_.cpu_data();
this->output_shape_.clear();
for (int i = 0; i < this->num_spatial_axes_; ++i) {
// i + 1 to skip channel axis
const int input_dim = this->input_shape(i + 1);
const int kernel_extent = dilation_data[i] * (kernel_shape_data[i] - 1) + 1;
const int output_dim = (input_dim + 2 * pad_data[i] - kernel_extent)
/ stride_data[i] + 1;
this->output_shape_.push_back(output_dim);
}
}
以上主要通过一些卷积算子的参数来计算卷积后的尺寸,包括 kernel_size、stride、pad、dilation(空洞卷积的配置)。
1.2 gemm forward
这里我们主要来看一下上面提到的 this->forward_cpu_gemm:
template
void BaseConvolutionLayer::forward_cpu_gemm(const Dtype* input,
const Dtype* weights, Dtype* output, bool skip_im2col) {
const Dtype* col_buff = input;
if (!is_1x1_) {
if (!skip_im2col) {
conv_im2col_cpu(input, col_buffer_.mutable_cpu_data());
}
col_buff = col_buffer_.cpu_data();
}
for (int g = 0; g < group_; ++g) {
caffe_cpu_gemm(CblasNoTrans, CblasNoTrans, conv_out_channels_ /
group_, conv_out_spatial_dim_, kernel_dim_,
(Dtype)1., weights + weight_offset_ * g, col_buff + col_offset_ * g,
(Dtype)0., output + output_offset_ * g);
}
}
可以看到 forward_cpu_gemm 有两个过程,先做 im2col 的展开,然后做 gemm 矩阵乘,这比较理所当然。看代码还可以知道,除 1 x 1 卷积 和 手动指定不要做 im2col 外,其余都需要做 im2col,其中 1 x 1 卷积是没有必要做展开,也比较好理解。下面顺序来看这两个过程,首先是 im2col。看下 conv_im2col_cpu 的声明:
inline void conv_im2col_cpu(const Dtype* data, Dtype* col_buff) {
if (!force_nd_im2col_ && num_spatial_axes_ == 2) {
im2col_cpu(data, conv_in_channels_,
conv_input_shape_.cpu_data()[1], conv_input_shape_.cpu_data()[2],
kernel_shape_.cpu_data()[0], kernel_shape_.cpu_data()[1],
pad_.cpu_data()[0], pad_.cpu_data()[1],
stride_.cpu_data()[0], stride_.cpu_data()[1],
dilation_.cpu_data()[0], dilation_.cpu_data()[1], col_buff);
} else {
im2col_nd_cpu(data, num_spatial_axes_, conv_input_shape_.cpu_data(),
col_buffer_shape_.data(), kernel_shape_.cpu_data(),
pad_.cpu_data(), stride_.cpu_data(), dilation_.cpu_data(), col_buff);
}
}
主要看 im2col_cpu() 的实现,实现在 src/caffe/util/im2col.cpp,下面结合图例进行说明。
如下图,黑实线为 feature map,虚线为填充 0,红色虚线框为 3 x 3 卷积核作用区域,步长和 dilation 都为 1。
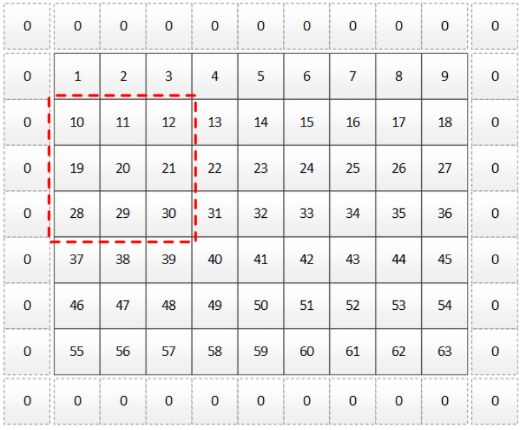
把如上卷积过程展开后得到如下示意图:

其中 output_rows 的 for 循环对应上图中的蓝色箭头范围,output_col 的 for 循环对应上图中的橙色半框范围,用代码实现如下:
template
void im2col_cpu(const Dtype* data_im, const int channels,
const int height, const int width, const int kernel_h, const int kernel_w,
const int pad_h, const int pad_w,
const int stride_h, const int stride_w,
const int dilation_h, const int dilation_w,
Dtype* data_col) {
const int output_h = (height + 2 * pad_h -
(dilation_h * (kernel_h - 1) + 1)) / stride_h + 1;
const int output_w = (width + 2 * pad_w -
(dilation_w * (kernel_w - 1) + 1)) / stride_w + 1;
const int channel_size = height * width;
for (int channel = channels; channel--; data_im += channel_size) {
for (int kernel_row = 0; kernel_row < kernel_h; kernel_row++) {
for (int kernel_col = 0; kernel_col < kernel_w; kernel_col++) {
int input_row = -pad_h + kernel_row * dilation_h;
for (int output_rows = output_h; output_rows; output_rows--) {
if (!is_a_ge_zero_and_a_lt_b(input_row, height)) {
for (int output_cols = output_w; output_cols; output_cols--) {
*(data_col++) = 0;
}
} else {
int input_col = -pad_w + kernel_col * dilation_w;
for (int output_col = output_w; output_col; output_col--) {
if (is_a_ge_zero_and_a_lt_b(input_col, width)) {
*(data_col++) = data_im[input_row * width + input_col];
} else {
*(data_col++) = 0;
}
input_col += stride_w;
}
}
input_row += stride_h;
}
}
}
}
}
如上就完成了 im2col 的过程,下面进入 gemm,主要由 caffe_cpu_gemm() 接口实现,这个实现在 src/caffe/util/math_functions.cpp:
template<>
void caffe_cpu_gemm(const CBLAS_TRANSPOSE TransA,
const CBLAS_TRANSPOSE TransB, const int M, const int N, const int K,
const float alpha, const float* A, const float* B, const float beta,
float* C) {
int lda = (TransA == CblasNoTrans) ? K : M;
int ldb = (TransB == CblasNoTrans) ? N : K;
cblas_sgemm(CblasRowMajor, TransA, TransB, M, N, K, alpha, A, lda, B,
ldb, beta, C, N);
}
这里主要调用了 Intel 数学内核库 MKL 中的 cblas_sgemm 来实现高性能的矩阵乘,函数接口为:
void cblas_sgemm(const CBLAS_LAYOUT Layout, const CBLAS_TRANSPOSE transa, const CBLAS_TRANSPOSE transb, const MKL_INT m, const MKL_INT n, const MKL_INT k, const float alpha, const float *a, const MKL_INT lda, const float *b, const MKL_INT ldb, const float beta, float *c, const MKL_INT ldc);
计算方式为 c := alpha * op(a) * op(b) + beta * c,参数:
- Layeout:表示二维矩阵存储是按行优先(CblasRowMajor)还是列优先(CblasColMajor), C++ 里是行优先存储的,fortran 是列优先存储数据;
- transa、transb:可为 CblasNoTrans、CblasTrans、CblasConjTrans;
- m:矩阵 a 和 c 的行数;
- n:矩阵 b 和 c 的列数;
- k:矩阵 a 的列数,矩阵 c 的行数;
- lda:行优先 & 不转置时, lda >= max(1, k);行优先 & 转置时,lda >= max(1, m);
- ldb:行优先 & 不转置时, ldb x k 的矩阵, b 矩阵左上角包含 n x k 的 B 矩阵;行优先 & 转置时,ldb x n 的矩阵, b 矩阵左上角包含 k x n 的 B 矩阵;
- ldc:行优先时, ldc >= max(1, n);
再来看一下 this->forward_gpu_gemm:
template
void BaseConvolutionLayer::forward_gpu_gemm(const Dtype* input,
const Dtype* weights, Dtype* output, bool skip_im2col) {
const Dtype* col_buff = input;
if (!is_1x1_) {
if (!skip_im2col) {
conv_im2col_gpu(input, col_buffer_.mutable_gpu_data());
}
col_buff = col_buffer_.gpu_data();
}
for (int g = 0; g < group_; ++g) {
caffe_gpu_gemm(CblasNoTrans, CblasNoTrans, conv_out_channels_ /
group_, conv_out_spatial_dim_, kernel_dim_,
(Dtype)1., weights + weight_offset_ * g, col_buff + col_offset_ * g,
(Dtype)0., output + output_offset_ * g);
}
}
同样看一下 conv_im2col_gpu 声明:
inline void conv_im2col_gpu(const Dtype* data, Dtype* col_buff) {
if (!force_nd_im2col_ && num_spatial_axes_ == 2) {
im2col_gpu(data, conv_in_channels_,
conv_input_shape_.cpu_data()[1], conv_input_shape_.cpu_data()[2],
kernel_shape_.cpu_data()[0], kernel_shape_.cpu_data()[1],
pad_.cpu_data()[0], pad_.cpu_data()[1],
stride_.cpu_data()[0], stride_.cpu_data()[1],
dilation_.cpu_data()[0], dilation_.cpu_data()[1], col_buff);
} else {
im2col_nd_gpu(data, num_spatial_axes_, num_kernels_im2col_,
conv_input_shape_.gpu_data(), col_buffer_.gpu_shape(),
kernel_shape_.gpu_data(), pad_.gpu_data(),
stride_.gpu_data(), dilation_.gpu_data(), col_buff);
}
}
来看 im2col_gpu(),这个实现在 src/caffe/util/im2col.cu:
template
void im2col_gpu(const Dtype* data_im, const int channels,
const int height, const int width, const int kernel_h, const int kernel_w,
const int pad_h, const int pad_w,
const int stride_h, const int stride_w,
const int dilation_h, const int dilation_w,
Dtype* data_col) {
// We are going to launch channels * height_col * width_col kernels, each
// kernel responsible for copying a single-channel grid.
int height_col = (height + 2 * pad_h -
(dilation_h * (kernel_h - 1) + 1)) / stride_h + 1;
int width_col = (width + 2 * pad_w -
(dilation_w * (kernel_w - 1) + 1)) / stride_w + 1;
int num_kernels = channels * height_col * width_col;
// NOLINT_NEXT_LINE(whitespace/operators)
im2col_gpu_kernel<<>>(
num_kernels, data_im, height, width, kernel_h, kernel_w, pad_h,
pad_w, stride_h, stride_w, dilation_h, dilation_w, height_col,
width_col, data_col);
CUDA_POST_KERNEL_CHECK;
}
来看 im2col_gpu_kernel 这个核函数:
template
__global__ void im2col_gpu_kernel(const int n, const Dtype* data_im,
const int height, const int width, const int kernel_h, const int kernel_w,
const int pad_h, const int pad_w,
const int stride_h, const int stride_w,
const int dilation_h, const int dilation_w,
const int height_col, const int width_col,
Dtype* data_col) {
CUDA_KERNEL_LOOP(index, n) {
const int h_index = index / width_col;
const int h_col = h_index % height_col;
const int w_col = index % width_col;
const int c_im = h_index / height_col;
const int c_col = c_im * kernel_h * kernel_w;
const int h_offset = h_col * stride_h - pad_h;
const int w_offset = w_col * stride_w - pad_w;
Dtype* data_col_ptr = data_col;
data_col_ptr += (c_col * height_col + h_col) * width_col + w_col;
const Dtype* data_im_ptr = data_im;
data_im_ptr += (c_im * height + h_offset) * width + w_offset;
for (int i = 0; i < kernel_h; ++i) {
for (int j = 0; j < kernel_w; ++j) {
int h_im = h_offset + i * dilation_h;
int w_im = w_offset + j * dilation_w;
*data_col_ptr =
(h_im >= 0 && w_im >= 0 && h_im < height && w_im < width) ?
data_im_ptr[i * dilation_h * width + j * dilation_w] : 0;
data_col_ptr += height_col * width_col;
}
}
}
}
以上完成了 gpu 版的 im2col 的过程,接下来是 gpu 版的 gemm。
template
void caffe_gpu_gemm(const CBLAS_TRANSPOSE TransA,
const CBLAS_TRANSPOSE TransB, const int M, const int N, const int K,
const Dtype alpha, const Dtype* A, const Dtype* B, const Dtype beta,
Dtype* C);
其实现在 src/caffe/util/math_functions.cu 中:
template <>
void caffe_gpu_gemm(const CBLAS_TRANSPOSE TransA,
const CBLAS_TRANSPOSE TransB, const int M, const int N, const int K,
const float alpha, const float* A, const float* B, const float beta,
float* C) {
// Note that cublas follows fortran order.
int lda = (TransA == CblasNoTrans) ? K : M;
int ldb = (TransB == CblasNoTrans) ? N : K;
cublasOperation_t cuTransA =
(TransA == CblasNoTrans) ? CUBLAS_OP_N : CUBLAS_OP_T;
cublasOperation_t cuTransB =
(TransB == CblasNoTrans) ? CUBLAS_OP_N : CUBLAS_OP_T;
CUBLAS_CHECK(cublasSgemm(Caffe::cublas_handle(), cuTransB, cuTransA,
N, M, K, &alpha, B, ldb, A, lda, &beta, C, N));
}
可以看到和 gemm_cpu 不同的是 gemm_gpu 调用了 cublas 中的高效矩阵乘方法 cublasSgemm。
1.3 bias forward
一般的卷积带有偏置 bias,上面已经谈了谈 im2col + gemm 的实现了,下面再说一下 bias 的实现。
forward_cpu_bias 的实现在 src/caffe/layers/base_conv_layer.cpp:
template
void BaseConvolutionLayer::forward_cpu_bias(Dtype* output,
const Dtype* bias) {
caffe_cpu_gemm(CblasNoTrans, CblasNoTrans, num_output_,
out_spatial_dim_, 1, (Dtype)1., bias, bias_multiplier_.cpu_data(),
(Dtype)1., output);
}
同样是调用了 caffe_cpu_gemm,前面介绍过这个接口里又调用了 cblas_sgemm,区别是通过传参控制 bias 计算为 矩阵加,而 gemm 为 矩阵乘,所以不多说了。
forward_gpu_bias 的实现在 src/caffe/layers/base_conv_layer.cpp:
template
void BaseConvolutionLayer::forward_gpu_bias(Dtype* output,
const Dtype* bias) {
caffe_gpu_gemm(CblasNoTrans, CblasNoTrans, num_output_,
out_spatial_dim_, 1, (Dtype)1., bias, bias_multiplier_.gpu_data(),
(Dtype)1., output);
}
里面调用了 caffe_gpu_gemm,最终调用了 cublas 中的矩阵运算操作。
以上介绍了 caffe conv img2col + gemm + bias 的整个实现过程。下面介绍一下 caffe cudnn_conv 的实现。
2、caffe cudnn conv
caffe 框架源码中除了有 img2col + gemm +bias 的卷积高效实现方法,还有 cudnn conv 的实现可供选择,下面对 caffe cudnn conv 进行介绍。
还是先来看一下头,在 include/caffe/layers/cudnn_conv_layer.hpp:
#ifdef USE_CUDNN
template
class CuDNNConvolutionLayer : public ConvolutionLayer {
public:
explicit CuDNNConvolutionLayer(const LayerParameter& param)
: ConvolutionLayer(param), handles_setup_(false) {}
virtual void LayerSetUp(const vector*>& bottom,
const vector*>& top);
virtual void Reshape(const vector*>& bottom,
const vector*>& top);
virtual ~CuDNNConvolutionLayer();
protected:
virtual void Forward_gpu(const vector*>& bottom,
const vector*>& top);
virtual void Backward_gpu(const vector*>& top,
const vector& propagate_down, const vector*>& bottom);
bool handles_setup_;
cudnnHandle_t* handle_;
cudaStream_t* stream_;
// algorithms for forward and backwards convolutions
cudnnConvolutionFwdAlgo_t *fwd_algo_;
cudnnConvolutionBwdFilterAlgo_t *bwd_filter_algo_;
cudnnConvolutionBwdDataAlgo_t *bwd_data_algo_;
vector bottom_descs_, top_descs_;
cudnnTensorDescriptor_t bias_desc_;
cudnnFilterDescriptor_t filter_desc_;
vector conv_descs_;
int bottom_offset_, top_offset_, bias_offset_;
size_t *workspace_fwd_sizes_;
size_t *workspace_bwd_data_sizes_;
size_t *workspace_bwd_filter_sizes_;
size_t workspaceSizeInBytes; // size of underlying storage
void *workspaceData; // underlying storage
void **workspace; // aliases into workspaceData
};
#endif
可以看到 cudnn conv 必须是在构建与 caffe_cudnn 的基础上,这里理所当然的,所以也只有 Forward_gpu,没有 cpu 版本了。其实现在 src/caffe/layers/cudnn_conv_layer.cu:
template
void CuDNNConvolutionLayer::Forward_gpu(
const vector*>& bottom, const vector*>& top) {
const Dtype* weight = this->blobs_[0]->gpu_data();
for (int i = 0; i < bottom.size(); ++i) {
const Dtype* bottom_data = bottom[i]->gpu_data();
Dtype* top_data = top[i]->mutable_gpu_data();
// Forward through cuDNN in parallel over groups.
for (int g = 0; g < this->group_; g++) {
// Filters.
CUDNN_CHECK(cudnnConvolutionForward(handle_[g],
cudnn::dataType::one,
bottom_descs_[i], bottom_data + bottom_offset_ * g,
filter_desc_, weight + this->weight_offset_ * g,
conv_descs_[i],
fwd_algo_[i], workspace[g], workspace_fwd_sizes_[i],
cudnn::dataType::zero,
top_descs_[i], top_data + top_offset_ * g));
// Bias.
if (this->bias_term_) {
const Dtype* bias_data = this->blobs_[1]->gpu_data();
CUDNN_CHECK(cudnnAddTensor(handle_[g],
cudnn::dataType::one,
bias_desc_, bias_data + bias_offset_ * g,
cudnn::dataType::one,
top_descs_[i], top_data + top_offset_ * g));
}
}
// Synchronize the work across groups, each of which went into its own
// stream, by launching an empty kernel into the default (null) stream.
// NOLINT_NEXT_LINE(whitespace/operators)
sync_conv_groups<<<1, 1>>>();
}
}
由于卷积的计算方式为 y = w * x + b,所以这里的实现也是有两个过程,即 乘w 和 加b。其中乘 w 调用了 cudnn 中的 cudnnConvolutionForward 接口来实现;加 b 调用了 cudnn 中的 cudnnAddTensor 接口来实现。
小结一下,以上介绍了 caffe 中关于 conv 前向推理的两个实现方式,可以看到到最后其实都是调用了高性能的推理库:
(1) img2col + gemm + bias:先做 img2col 展开为并行计算做基础,gemm 和 bias 的计算在 cpu 时最后都调用了 MKL 中的 cblas_sgemm 接口,gpu 时最后都调用了 cublas 中的 cublasSgemm 接口;
(2) cudnn conv:权重矩阵乘调用了 cudnn 中的 cudnnConvolutionForward 接口来实现,加偏置调用了 cudnn 中的 cudnnAddTensor 来实现。
关于 caffe conv 的介绍就这样了,有问题欢迎讨论~
【公众号传送】
《【模型推理】谈谈 caffe 的 conv 算子》
扫描下方二维码即可关注我的微信公众号【极智视界】,获取更多AI经验分享,让我们用极致+极客的心态来迎接AI !
