Spark DataFrame之创建DataFrame
创建DataFrame的各种例子代码,主要是用来构造测试用例,方便快速测试方法、UDF之类。
参考spark官方文档
总共15个例子,每个例子分别使用了scala和python语言code,两种语言的例子是一一对应的,序号相同的就是同一个例子。
包括Array、Seq数据格式存储的数据,包括稀疏向量、稠密向量的特征列,包括含有缺失值的列等,看完就再也不怕用各种奇形怪状的数据类型来创建DataFrame了。
一、In Scala
1、常规情况
val dataset = spark.createDataFrame(Seq(
(2.2, true, "1", "foo"),
(3.3, false, "2", "bar"),
(4.4, false, "3", "baz"),
(5.5, false, "4", "foo")
)).toDF("real", "bool", "stringNum", "string")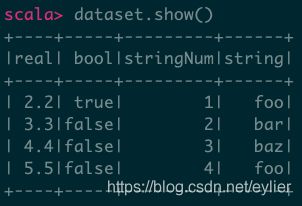
2、文本列
//in scala
val sentenceData = spark.createDataFrame(Seq(
(0.0, "Hi I heard about Spark"),
(0.0, "I wish Java could use case classes"),
(1.0, "Logistic regression models are neat")
)).toDF("label", "sentence")3、Array作为列 - split()函数
// Input data: Each row is a bag of words from a sentence or document.
val documentDF = spark.createDataFrame(Seq(
"Hi I heard about Spark".split(" "),
"I wish Java could use case classes".split(" "),
"Logistic regression models are neat".split(" ")
).map(Tuple1.apply)).toDF("text")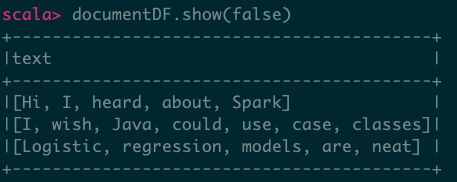
4、Array作为列 -Array()
val df = spark.createDataFrame(Seq(
(0, Array("a", "b", "c")),
(1, Array("a", "b", "b", "c", "a"))
)).toDF("id", "words")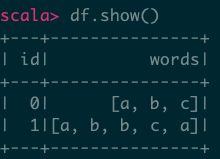
5、Array声明的列
val data = Array((0, 0.1), (1, 0.8), (2, 0.2))
val dataFrame = spark.createDataFrame(data).toDF("id", "feature")
6、Seq声明的列
val dataSet = spark.createDataFrame(Seq(
(0, Seq("I", "saw", "the", "red", "balloon")),
(1, Seq("Mary", "had", "a", "little", "lamb"))
)).toDF("id", "raw")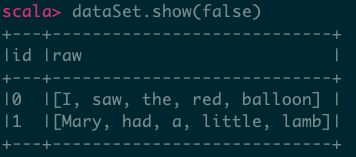
7、稀疏向量、稠密向量作为列
import org.apache.spark.ml.linalg.Vectors
val data = Array(
Vectors.sparse(5, Seq((1, 1.0), (3, 7.0))),
Vectors.dense(2.0, 0.0, 3.0, 4.0, 5.0),
Vectors.dense(4.0, 0.0, 0.0, 6.0, 7.0)
)
val df = spark.createDataFrame(data.map(Tuple1.apply)).toDF("features")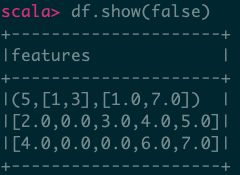
8、稠密向量作为列- Array存储
import org.apache.spark.ml.linalg.Vectors
val data = Array(
Vectors.dense(2.0, 1.0),
Vectors.dense(0.0, 0.0),
Vectors.dense(3.0, -1.0)
)
val df = spark.createDataFrame(data.map(Tuple1.apply)).toDF("features")
df.show(false)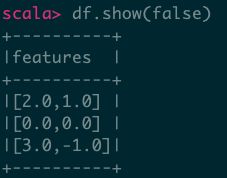
9.1、稠密向量作为列- Seq存储
val data = Seq(
(7, Vectors.dense(0.0, 0.0, 18.0, 1.0), 1.0),
(8, Vectors.dense(0.0, 1.0, 12.0, 0.0), 0.0),
(9, Vectors.dense(1.0, 0.0, 15.0, 0.1), 0.0)
)
val df = spark.createDataset(data).toDF("id", "features", "clicked")
df.show(false)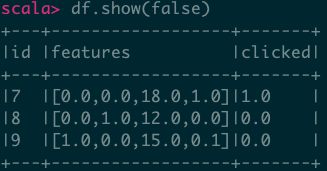
9.2、稠密向量作为列- Seq存储
import org.apache.spark.ml.linalg.Vectors
val data = Seq(
Vectors.dense(0.0, 1.0, -2.0, 3.0),
Vectors.dense(-1.0, 2.0, 4.0, -7.0),
Vectors.dense(14.0, -2.0, -5.0, 1.0))
val df = spark.createDataFrame(data.map(Tuple1.apply)).toDF("features")
df.show(false)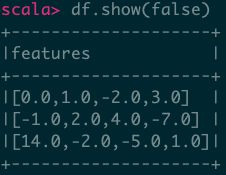
10、
val data = Array(-999.9, -0.5, -0.3, 0.0, 0.2, 999.9)
val df = spark.createDataFrame(data.map(Tuple1.apply)).toDF("features")
df.show(false)11、
val data = Array((0, 18.0), (1, 19.0), (2, 8.0), (3, 5.0), (4, 2.2))
val df = spark.createDataFrame(data).toDF("id", "hour")
df.show(false)12、有缺失值的列
val df = spark.createDataFrame(Seq(
(1.0, Double.NaN),
(2.0, Double.NaN),
(Double.NaN, 3.0),
(4.0, 4.0),
(5.0, 5.0)
)).toDF("a", "b")
df.show(false)13、稀疏和稠密向量混合的DF
import java.util.Arrays
import org.apache.spark.ml.attribute.{Attribute, AttributeGroup, NumericAttribute}
import org.apache.spark.ml.feature.VectorSlicer
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.types.StructType
val data = Arrays.asList(
Row(Vectors.sparse(3, Seq((0, -2.0), (1, 2.3)))),
Row(Vectors.dense(-2.0, 2.3, 0.0))
)
val defaultAttr = NumericAttribute.defaultAttr
val attrs = Array("f1", "f2", "f3").map(defaultAttr.withName)
val attrGroup = new AttributeGroup("userFeatures", attrs.asInstanceOf[Array[Attribute]])
val dataset = spark.createDataFrame(data, StructType(Array(attrGroup.toStructField())))
dataset.show(false)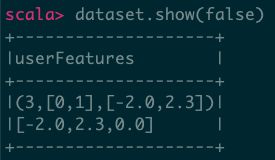
15、稀疏向量作为列
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.col
val dfA = spark.createDataFrame(Seq(
(0, Vectors.sparse(6, Seq((0, 1.0), (1, 1.0), (2, 1.0)))),
(1, Vectors.sparse(6, Seq((2, 1.0), (3, 1.0), (4, 1.0)))),
(2, Vectors.sparse(6, Seq((0, 1.0), (2, 1.0), (4, 1.0))))
)).toDF("id", "features")
val dfB = spark.createDataFrame(Seq(
(3, Vectors.sparse(6, Seq((1, 1.0), (3, 1.0), (5, 1.0)))),
(4, Vectors.sparse(6, Seq((2, 1.0), (3, 1.0), (5, 1.0)))),
(5, Vectors.sparse(6, Seq((1, 1.0), (2, 1.0), (4, 1.0))))
)).toDF("id", "features")
dfA.show(false)
dfB.show(false)
以下的例子跟上面Scala的例子是一一对应的,只不过使用python版本写的。
二、In Python
1、
dataset = spark.createDataFrame([
(2.2, True, "1", "foo"),
(3.3, False, "2", "bar"),
(4.4, False, "3", "baz"),
(5.5, False, "4", "foo")
], ["real", "bool", "stringNum", "string"])2、
#in python
sentenceData = spark.createDataFrame([
(0.0, "Hi I heard about Spark"),
(0.0, "I wish Java could use case classes"),
(1.0, "Logistic regression models are neat")
], ["label", "sentence"])3、
# Input data: Each row is a bag of words from a sentence or document.
documentDF = spark.createDataFrame([
("Hi I heard about Spark".split(" "), ),
("I wish Java could use case classes".split(" "), ),
("Logistic regression models are neat".split(" "), )
], ["text"])4、
# Input data: Each row is a bag of words with a ID.
df = spark.createDataFrame([
(0, "a b c".split(" ")),
(1, "a b b c a".split(" "))
], ["id", "words"])5、
sentenceData = spark.createDataFrame([
(0, ["I", "saw", "the", "red", "balloon"]),
(1, ["Mary", "had", "a", "little", "lamb"])
], ["id", "raw"])6、
continuousDataFrame = spark.createDataFrame([
(0, 0.1),
(1, 0.8),
(2, 0.2)
], ["id", "feature"])7、
from pyspark.ml.linalg import Vectors
data = [(Vectors.sparse(5, [(1, 1.0), (3, 7.0)]),),
(Vectors.dense([2.0, 0.0, 3.0, 4.0, 5.0]),),
(Vectors.dense([4.0, 0.0, 0.0, 6.0, 7.0]),)]
df = spark.createDataFrame(data, ["features"])8、
from pyspark.ml.linalg import Vectors
df = spark.createDataFrame([
(Vectors.dense([2.0, 1.0]),),
(Vectors.dense([0.0, 0.0]),),
(Vectors.dense([3.0, -1.0]),)
], ["features"])9.1
from pyspark.ml.linalg import Vectors
df = spark.createDataFrame([
(Vectors.dense([0.0, 1.0, -2.0, 3.0]),),
(Vectors.dense([-1.0, 2.0, 4.0, -7.0]),),
(Vectors.dense([14.0, -2.0, -5.0, 1.0]),)], ["features"])9.2
from pyspark.ml.linalg import Vectors
df = spark.createDataFrame([
(7, Vectors.dense([0.0, 0.0, 18.0, 1.0]), 1.0,),
(8, Vectors.dense([0.0, 1.0, 12.0, 0.0]), 0.0,),
(9, Vectors.dense([1.0, 0.0, 15.0, 0.1]), 0.0,)], ["id", "features", "clicked"])10、
data = [(-999.9,), (-0.5,), (-0.3,), (0.0,), (0.2,), (999.9,)]
dataFrame = spark.createDataFrame(data, ["features"])11、
data = [(0, 18.0), (1, 19.0), (2, 8.0), (3, 5.0), (4, 2.2)]
df = spark.createDataFrame(data, ["id", "hour"])12、缺失值
df = spark.createDataFrame([
(1.0, float("nan")),
(2.0, float("nan")),
(float("nan"), 3.0),
(4.0, 4.0),
(5.0, 5.0)
], ["a", "b"])13、
from pyspark.ml.feature import VectorSlicer
from pyspark.ml.linalg import Vectors
from pyspark.sql.types import Row
df = spark.createDataFrame([
Row(userFeatures=Vectors.sparse(3, {0: -2.0, 1: 2.3})),
Row(userFeatures=Vectors.dense([-2.0, 2.3, 0.0]))])14、
from pyspark.ml.linalg import Vectors
from pyspark.sql.functions import col
dataA = [(0, Vectors.sparse(6, [0, 1, 2], [1.0, 1.0, 1.0]),),
(1, Vectors.sparse(6, [2, 3, 4], [1.0, 1.0, 1.0]),),
(2, Vectors.sparse(6, [0, 2, 4], [1.0, 1.0, 1.0]),)]
dfA = spark.createDataFrame(dataA, ["id", "features"])
dataB = [(3, Vectors.sparse(6, [1, 3, 5], [1.0, 1.0, 1.0]),),
(4, Vectors.sparse(6, [2, 3, 5], [1.0, 1.0, 1.0]),),
(5, Vectors.sparse(6, [1, 2, 4], [1.0, 1.0, 1.0]),)]
dfB = spark.createDataFrame(dataB, ["id", "features"])