基于 pytorch模型猫狗图片识别
一步步带你敲卷积网络识别猫狗图片算法,步骤详细思路清晰。本文章利用 模块化模型解决猫狗图片识别问题。
构建一个网络模型基本由这四个步骤逐步搭建:
- 构建网络模型
- 准备及处理数据集
- 定义损失函数和优化器
- 训练和测试
文章还会对训练好的模型进行测试使用,延伸利用图像的函数做训练过程数据的可视化,分享数据训练的情况。
1、构建网络模型
首先先构建Alex Net网络模型,我把网络模型写在一个独立的文件上,模块化,我后期可以替换模型来训练数据集。
Alex Net :
这是Alex Net模型的结构图,没有复杂的结构,就是CONV卷积层和Max pool最大池化的堆叠,最后连到全连接层并做Softmax的分类,网络输出的是1000,但是我们做的是猫狗的分类只需要2个答案,所以1000的输出在做一层线性转换为2输出即可。
tips:每次卷积后要做Rule激活
| 网络模型结构细分步骤(依次往下走): |
|---|
| Conv(输入:3,输出:96,卷积核:11*11,步数:4) |
| Max pool(卷积核:3*3,步数:2) |
| Relu |
| Conv(输入:96,输出:256,卷积核:5*5,padding:2) |
| Max pool(卷积核:3*3,步数:2) |
| Relu |
| Conv(输入:256,输出:384,卷积核:3*3,padding:1) |
| Relu |
| Conv(输入:384,输出:384,卷积核:3*3,padding:1) |
| Relu |
| Conv(输入:384,输出:256,卷积核:3*3,padding:1) |
| Max pool(卷积核:3*3,步数:2) |
| Relu |
| Linear(输入:4096,输出:4096) |
| Linear(输入:4096,输出:2048) |
| Linear(输入:2048,输出:1000) |
| Linear(输入:1000,输出:2) |
第一层Linear的输入是通过卷积后的数据变形成一维的数据得到的,可以先不填让系统报错得到:

这里把网络模型另外写出了一个文件net.py:
import torch
import torch.nn.functional as f
'''Alex net '''
class MyAlexNet(torch.nn.Module):
def __init__(self):
'''定义子类和参数'''
super(MyAlexNet, self).__init__()
self.conv1 = torch.nn.Conv2d(3,96,kernel_size=11,stride=4)
self.mp = torch.nn.MaxPool2d(kernel_size=3,stride=2)
self.conv2 = torch.nn.Conv2d(96,256,kernel_size=5,padding=2)
self.conv3 = torch.nn.Conv2d(256,384,kernel_size=3,padding=1)
self.conv4 = torch.nn.Conv2d(384,384,kernel_size=3,padding=1)
self.conv5 = torch.nn.Conv2d(384,256,kernel_size=3)
self.Linear1 = torch.nn.Linear(1,4096)
self.Linear2 = torch.nn.Linear(4096,2048)
self.Linear3 = torch.nn.Linear(2048,1000)
self.Linear4 = torch.nn.Linear(1000,2)
def forward(self,x):
'''网络构建'''
batch_size =x.size(0)#x.Size([1, 3, 224, 224])
x = f.relu(self.mp(self.conv1(x)))
x = f.relu(self.mp(self.conv2(x)))
x = f.relu(self.conv3(x))
x = f.relu(self.conv4(x))
x = f.relu(self.conv5(x))
x = self.mp(x)
x = x.view(batch_size,-1)#(数据维度,数据长度)-1是指让电脑自动运算数据得到
x = self.Linear1(x)
x = f.dropout(x, p=0.5) # 防止过拟合,有50%的数据随机失效
x = self.Linear2(x)
x = f.dropout(x,p=0.5)
x = self.Linear3(x)
x = f.dropout(x, p=0.5)
x = self.Linear4(x)
return x
model = MyAlexNet()
2、准备及处理数据集
数据集链接: https://pan.baidu.com/s/1CTPq-ttZXX_MJsXaRz3vDg
提取码: cofr

拿到的数据集是只有两个Cat和Dog文件,文件需要做些预处理:
1.建立train训练的数据集和val验证的数据集并存入数据
2.载入数据,并利用transform图像预处理包,对图像进行预处理:大小统一设置为224*224、数据类型转换为Pytorch可处理的tensor形式。读取图像数据,将可视化的图像处理为数字信息用于计算。
建立train和val数据文件,train存入80%数据val存入20%,我们直接用python的os模块来分块,代码主要功能分为三步,第一步检测是否,没有就生成,第二步创建train和val文件夹,第三步把区分好的数据传入train和val文件中。
流程图:
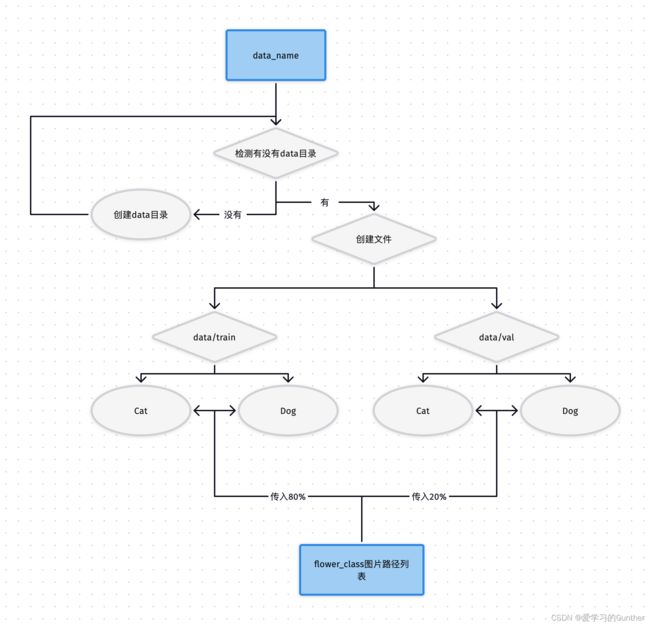
建立和划分数据的代码split_data.py:
import os
from shutil import copy
import random
def mkfile(file):
if not os.path.exists(file):
os.makedirs(file)#如果没有file文件就创建一个
# 获取data文件夹下所有文件夹名(即需要分类的类名)
file_path = '/Users/aixuexi_pro/PycharmProjects/pytorch/torch/Alex net 猫狗识别/data_name'
flower_class = [cla for cla in os.listdir(file_path)]
# 创建 训练集train 文件夹,并由类名在其目录下创建5个子目录
mkfile('data/train')
for cla in flower_class:
mkfile('data/train/' + cla)
# 创建 验证集val 文件夹,并由类名在其目录下创建子目录
mkfile('data/val')
for cla in flower_class:
mkfile('data/val/' + cla)
# 划分比例,训练集 : 验证集 = 8 : 2
split_rate = 0.2
# 遍历所有类别的全部图像并按比例分成训练集和验证集
for cla in flower_class:
cla_path = file_path + '/' + cla + '/' # 某一类别的子目录
images = os.listdir(cla_path) # iamges 列表存储了该目录下所有图像的名称
num = len(images)
eval_index = random.sample(images, k=int(num * split_rate)) # 从images列表中随机抽取 k 个图像名称
for index, image in enumerate(images):
'''保存图像进文件中'''
# eval_index 中保存验证集val的图像名称
if image in eval_index:
image_path = cla_path + image
new_path = 'data/val/' + cla
copy(image_path, new_path) # 将选中的图像复制到新路径
# 其余的图像保存在训练集train中
else:
image_path = cla_path + image
new_path = 'data/train/' + cla
copy(image_path, new_path)
print("\r[{}] processing [{}/{}]".format(cla, index + 1, num), end="") # processing bar
print("processing done!")
运行后会得到下图样子:

文件分好类处理好后还需要对图片做预处理,把图片,归一化和转为张量数据,这一步直接写到统一写到train.py文件里。
train.py里面包含,数据处理,损失和优化的定义,训练代码,验证代码,画图代码,保存最优模型代码还添加一个训练进度条。
train.py
导入训练时代码需要的库:
import torch
from net import MyAlexNet # 导入写好的网络模型
from torch.optim import lr_scheduler # 优化器
import os#文件处理
# 处理数据集的库
from torchvision import transforms
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt#画图
import time#时间
from tqdm import tqdm#进度条
数据处理还没有做完,还需要把数据做统一形状,把图片转为张量数据和做归一化,归一化是把数据统一降到[0,1]之间,这样的好处是降低代码的运输量。这些操作都是包括在transform函数里,可以说transform就是个工具箱的名字,我们定义这个工具箱里面添加统一形状,归一化等工具
train的transform操作里多加了一个数据增强的操作
# 做数据归一化, 让图像的数据归一化到[0,1]之间
normalize = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
# 把图像做数据处理
train_transforms = transforms.Compose([
transforms.Resize((224, 224)), # 把所有图像统一定义一个大小,论文里是224*224
transforms.RandomVerticalFlip(), # 随机垂直旋转,让数据更多做数据增强
transforms.ToTensor(), # 把图片转换为张量数据
normalize # 归一化
])
测试集也需要做同样的操作,但是不需要做数据增强,测试集需要保证测试的数据的真实性
val_transforms = transforms.Compose([
transforms.Resize((224, 224)), # 把所有图像统一定义层一个大小,论文里是224*224
transforms.ToTensor(), # 把图片转换为张量数据
normalize # 归一化
])
定义好transfroms工具,就要用。
使用把图片用特定的格式存进函数里,并使用前面定义的transfroms工具来处理成相应的数据
train_dataset = ImageFolder(ROOT_train, transform=train_transforms)
val_dataset = ImageFolder(ROOT_test, transform=val_transforms)
使用把数据用DataLoader打包起来,把数据在分割成mini-batch,train的数据需要shuffle打乱处理,这才是最终模型能处理的数据。
# 把数据分批次bacth,shuffle=True 打乱数据集
train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=32, shuffle=False)
数据处理最终保存在train_dataloader 和val_dataloader里
总结一下:
刚拿到数据的时候需要对文件进行分割一般就是分为训练和验证两个文件,两个文件数据的比例我选择的是8:2(按需调整),然后对文件做预处理的操作,预处理操作,对这些图片做统一大小,转换张量,数据增强,归一化。做完这一系列操作后用DataLoader统一打包分割成mini-batch的数据。
利用GPU训练
推荐利用GPU来训练这个模型,数据集非常大猫狗的照片有大概2万张,我用cup训练10轮需要9个小时,用1650显卡训练20轮只需要47分钟,差距巨大。
导入显卡的代码:
device = 'cuda' if torch.cuda.is_available() else 'cpu'
导入网络模型
网络模型是另一写的一个文件net.py,在开头已经导入,这里可以直接调用。
model = MyAlexNet()
3、定义损失函数和优化器
损失函数用的是交叉熵CEL,优化函数用的是SGD。
criterion = torch.nn.CrossEntropyLoss() # 交叉熵
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9) #model.parameters()把模型参数传入
lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.5)# 学习率每隔10轮变为原来的0.5
4、训练和验证
训练就是把数据放进模型里进行训练使得梯度达到最低点的过程,训练过程都是一个统一的流程,按照这个流程准没错
- 取数据
- 梯度清零
- 计算模型
- 算损失
- 反向传播
- 优化梯度
除此之外我还加入了计算每批次的准确率,还有损失值并返回,利于分析模型的优度,方便后期对模型进行调整。
训练的代码:
def train(dataloader, model, loss_fn, optimizer):
loss_sum, current, n = 0.0, 0.0, 0
for batch_idx, data in enumerate(tqdm(dataloader,desc='train:')):
input, target = data
optimizer.zero_grad() # 梯度清零
output = model(input) # 训练
loss = loss_fn(output, target) # 算损失
_, prad = torch.max(output, dim=1) # 去最高值
cur_acc = torch.sum(target == prad) / output.shape[0] # 算精确率
loss.backward() # 反向传播
optimizer.step() # 优化梯度
n = n + 1 # 总轮次
loss_sum += loss.item() # 每批次总的损失值
current += cur_acc.item() # 每批次总的精确率
train_loss = loss_sum / n # 计算每批次平均损失值
train_acc = current / n # 计算每批次平均精确度
print(train_acc)
print("train_loss:{0},train_acc:{1}%".format(train_loss, train_acc * 100))
end1 = time.time()
print("训练结束 运行时间:{:.3f}分钟".format((end1 - start) / 60))
return train_loss, train_acc
每轮训练后进行一次对模型的验证。验证集基本是在每个epoch完成后,用来测试一下当前模型的准确率。因为验证集跟训练集没有交集,因此这个准确率是可靠的。
所以我只需要把验证集val的数据放进模型计算验证,并记录准确率和损失值,不需要再去计算梯度和优化梯度。
验证代码:
def val(dataloader, model, loss_fn):
loss_sum, current, n = 0.0, 0.0, 0
model.eval()#将模型转化为验证模式
with torch.no_grad():
for i, data in enumerate(tqdm(dataloader,desc='val:')):
input, target = data
output = model(input) # 训练
loss = loss_fn(output, target) # 算损失
_, prad = torch.max(output, dim=1) # 去最高值
cur_acc = torch.sum(target == prad) / output.shape[0] # 算精确率
loss_sum += loss.item() # 每批次总的损失值
current += cur_acc.item() # 每批次总的精确率
n = n + 1 # 总轮次
val_loss = loss_sum / n # 计算每批次平均损失值
val_acc = current / n # 计算每批次平均精确度
end3 = time.time()
print("预测结束 运行时间:{:.3f}分钟".format((end3 - start) / 60))
print("val_loss:{0},val_acc:{1}%".format(val_loss, val_acc * 100))
return val_loss, val_acc
再设计一个主函数让代码跑起来,并且保存最优的的模型代码
t_loss = []
t_acc = []
v_loss = []
v_acc = []
# 开始训练
min_acc = 0
epoch = 10
for i in tqdm(range(epoch),desc='训练:'):
lr_scheduler.step()
print(f"第{i+1}轮,开始训练>>>>>")
train_loss, train_acc = train(train_dataloader, model, criterion, optimizer)
val_loss, val_acc = val(val_dataloader, model, criterion)
# 存入列表
t_loss.append(train_loss)
t_acc.append(train_acc)
v_loss.append(val_loss)
v_acc.append(val_acc)
# 保存最好的模型文件
if val_acc > min_acc:
print(val_acc)
foload="save_model"
if not os.path.exists(foload):
os.mkdir("save_model")
min_acc = val_acc#把最新的精度更新进去
print(f"save bset model,第{i + 1}轮")
torch.save(model.state_dict(), 'save_model/best_model.pth')
# 保存最后一轮权重文件
if i == epoch - 1:
torch.save(model.state_dict(), "save_model/last_model.pth")
训练模型的整体代码:
train.py
'''训练模型'''
import torch
from net import MyAlexNet # 导入写好的网络模型
from torch.optim import lr_scheduler # 优化器
import os#文件处理
# 处理数据集的库
from torchvision import transforms
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt#画图
import time#时间
from tqdm import tqdm#进度条
start = time.time()
# 解决中文现实问题
plt.rcParams["font.sans-serif"] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
'''1、数据处理'''
# 数据集的路径
ROOT_train = r'/Users/aixuexi_pro/PycharmProjects/pytorch/torch/Alex net 猫狗识别/data/train'
ROOT_test = r"/Users/aixuexi_pro/PycharmProjects/pytorch/torch/Alex net 猫狗识别/data/val"
# 做数据归一化, 让图像的数据归一化到[0,1]之间
normalize = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
# 把图像做数据处理
train_transforms = transforms.Compose([
transforms.Resize((224, 224)), # 把所有图像统一定义一个大小,论文里是224*224
transforms.RandomVerticalFlip(), # 随机垂直旋转,让数据更多做数据增强
transforms.ToTensor(), # 把图片转换为张量数据
normalize # 归一化
])
# 测试集也需要做同样的操作,但是不需要做数据增强,测试集需要保证测试的数据的真实性
val_transforms = transforms.Compose([
transforms.Resize((224, 224)), # 把所有图像统一定义层一个大小,论文里是224*224
transforms.ToTensor(), # 把图片转换为张量数据
normalize # 归一化
])
# 数据最终处理
train_dataset = ImageFolder(ROOT_train, transform=train_transforms)
val_dataset = ImageFolder(ROOT_test, transform=val_transforms)
# 把数据分批次bacth,shuffle=True 打乱数据集
train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=32, shuffle=False)
# 导入GPU寻训练,N卡需要安装cuda,我苹果电脑没有
device = 'cuda' if torch.cuda.is_available() else 'cpu'
'''2、导入模型'''
model = MyAlexNet().to(device)
'''3、损失和优化'''
criterion = torch.nn.CrossEntropyLoss() # 交叉熵
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9) # model.parameters()把模型参数传入
# 学习率每隔10轮变为原来的0.5
lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.5)
'''4、训练'''
# 定义训练函数
def train(dataloader, model, loss_fn, optimizer):
loss_sum, current, n = 0.0, 0.0, 0
for batch_idx, data in enumerate(tqdm(dataloader,desc='train:')):
input, target = data.to(device)
optimizer.zero_grad() # 梯度清零
output = model(input) # 训练
loss = loss_fn(output, target) # 算损失
_, prad = torch.max(output, dim=1) # 去最高值
cur_acc = torch.sum(target == prad) / output.shape[0] # 算精确率
loss.backward() # 反向传播
optimizer.step() # 优化梯度
n = n + 1 # 总轮次
loss_sum += loss.item() # 每批次总的损失值
current += cur_acc.item() # 每批次总的精确率
train_loss = loss_sum / n # 计算每批次平均损失值
train_acc = current / n # 计算每批次平均精确度
print(train_acc)
print("train_loss:{0},train_acc:{1}%".format(train_loss, train_acc * 100))
end1 = time.time()
print("训练结束 运行时间:{:.3f}分钟".format((end1 - start) / 60))
return train_loss, train_acc
# 定义验证函数
def val(dataloader, model, loss_fn):
loss_sum, current, n = 0.0, 0.0, 0
model.eval()#将模型转化为验证模式
with torch.no_grad():
for i, data in enumerate(tqdm(dataloader,desc='val:')):
input, target = data.to(device)
output = model(input) # 训练
loss = loss_fn(output, target) # 算损失
_, prad = torch.max(output, dim=1) # 去最高值
cur_acc = torch.sum(target == prad) / output.shape[0] # 算精确率
loss_sum += loss.item() # 每批次总的损失值
current += cur_acc.item() # 每批次总的精确率
n = n + 1 # 总轮次
val_loss = loss_sum / n # 计算每批次平均损失值
val_acc = current / n # 计算每批次平均精确度
end3 = time.time()
print("预测结束 运行时间:{:.3f}分钟".format((end3 - start) / 60))
print("val_loss:{0},val_acc:{1}%".format(val_loss, val_acc * 100))
return val_loss, val_acc
'''定义画图函数'''
def matplot_loss(train_loss, val_loss):
plt.plot(train_loss, label="train_loss")
plt.plot(val_loss, label="val_loss")
plt.legend(loc='best')
plt.ylabel('loss')
plt.xlabel("epoch")
plt.title("训练集和测试集loss对比图")
plt.show()
def matplot_acc(train_acc, val_acc):
plt.plot(train_acc, label="train_acc")
plt.plot(val_acc, label="val_acc")
plt.legend(loc='best')
plt.ylabel('acc')
plt.xlabel("epoch")
plt.title("训练集和测试集acc对比图")
plt.show()
# 定义列表接收数据,画图需要用
t_loss = []
t_acc = []
v_loss = []
v_acc = []
# 开始训练
min_acc = 0
epoch = 10
for i in tqdm(range(epoch),desc='训练:'):
lr_scheduler.step()
print(f"第{i+1}轮,开始训练>>>>>")
train_loss, train_acc = train(train_dataloader, model, criterion, optimizer)
val_loss, val_acc = val(val_dataloader, model, criterion)
# 存入列表
t_loss.append(train_loss)
t_acc.append(train_acc)
v_loss.append(val_loss)
v_acc.append(val_acc)
# 保存最好的模型文件
if val_acc > min_acc:
print(val_acc)
foload="save_model"
if not os.path.exists(foload):
os.mkdir("save_model")
min_acc = val_acc#把最新的精度更新进去
print(f"save bset model,第{i + 1}轮")
torch.save(model.state_dict(), 'save_model/best_model.pth')
# 保存最后一轮权重文件
if i == epoch - 1:
torch.save(model.state_dict(), "save_model/last_model.pth")
matplot_loss(t_loss, v_loss)
matplot_acc(t_acc, v_acc)
end2 = time.time()
print("程序结束,程序运行时间:{:.3f}分钟".format((end2 - start) / 60))
训练结果:
代码运行20轮准确率到达91%我忘记截图
下面是代码运行的过程:
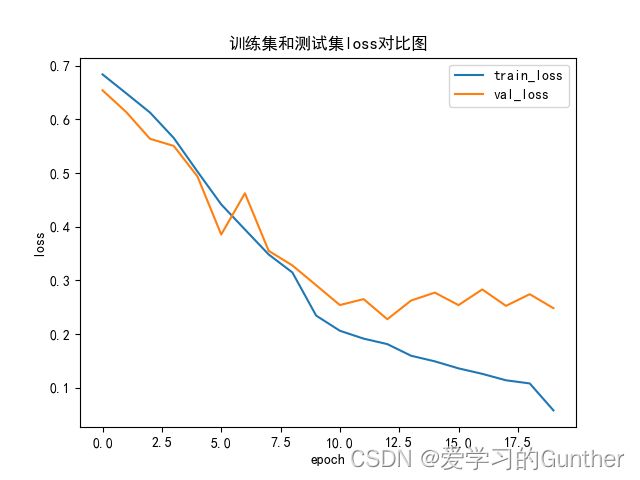
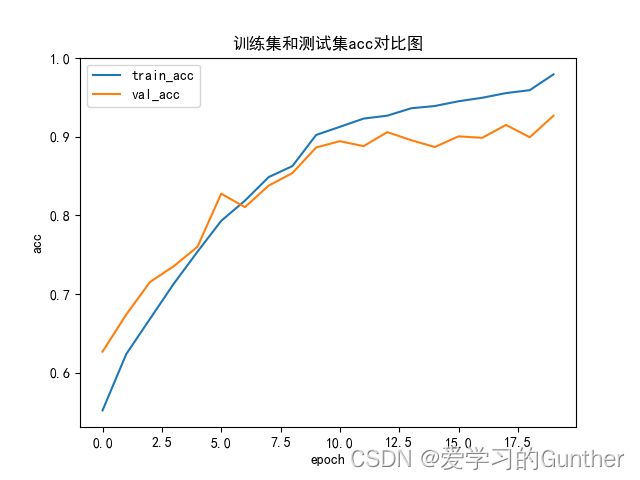
从loss图看出train的曲线平滑拟合的很好,但是从val的曲线看模型的噪声还很很多,到第九轮时模型时最优点,九轮以后开始过拟合。验证的准确率到达了90%多。
测试模型
单单做了验证还不够,模型训练出来了要用没有经过模型的图片来测试模型的准确性。也是对训练出来的模型进行运用,看看模型是否能真正的识别出猫狗。
test.py测试的步骤:
- 载入数据
- 载入模型
- 数据进入模型测试
载入数据:
步骤和前面一样,对数据的Totensor处理不能少
ROOT_test = ("./data/test")
transform = transforms.Compose([
transforms.Resize((224,224)),#统一大小
transforms.ToTensor(),#转换数据
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])#归一化
])
Val_dataset = ImageFolder(ROOT_test,transform=transform)
Val_dataloder = DataLoader(Val_dataset)
导入模型:
导入模型的时候有个问题,我的模型是导入到GPU训练的,但是我测试的时候我的电脑没有显卡怎么办要用cpu做测试,这个时候会报错。导入是加入此代码即可map_location=torch.device(‘cpu’)用个异常处理结构写,这样不论我是用GPU还是CPU都能正常导入模型。
model = MyAlexNet()
'''这里我用了个异常处理结构'''
try:
model.load_state_dict(torch.load('./save_model/best_model.pth'))
except :
'''如果模型是导入GPU训练的你需要把模型再导入回cpu'''
model.load_state_dict(torch.load('./save_model/best_model.pth',map_location=torch.device('cpu')))
数据进入测试:
建立了个classes列表存放答案,需要注意里面答案排列的顺序需要和你训练时输入的猫狗训练集先后顺序一致,否则测试会有问题,测试的过程和验证差不多看代码:
classes = [
'猫', '狗']#这里的答案顺序要和训练文件名字顺序一致
def prediect():
model.eval()
epoch=0
for x,y in Val_dataloder:
with torch.no_grad():
outputs = model(x)
outputs = torch.softmax(outputs,dim=1)#用softmax的特性在对数据进行一个标准化的概率预测值
_, predicted = torch.max(outputs, 1)#取出数据最大值和最大值的标签
epoch+=1
print(f'epoch:{epoch} this picture maybe :{classes[predicted[0]]},pred:{_.item()*100}%')
前面几步都清楚取数据,数据经过模型训练,这时候返回的outputs是个tensor数据里面有两个数有负数有正数,
![]()
可以看出这两值的区别很大,只要取最大值的下标就可以预测出它是猫还是狗,但是我想得到它在tensor概率,我把数据放进softmax里做运算,
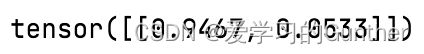
利用softmax的特性,我就可以的到它在这个tensor里的占比就的到里概率值。
只要取出最大值的标准放进classes列表里取值就可以判断出是猫是狗
max_pred, predicted = torch.max(outputs, 1)#取出数据最大值’max_pred’和最大值的标签’predicted’
print(f'epoch:{epoch} this picture maybe :{classes[predicted[0]]},pred:{max_pred.item()*100}%')
整体代码test.py:
import torch
from PIL import Image
from torchvision import transforms
from net import MyAlexNet
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
import os
ROOT_test = ("./data/test")
model = MyAlexNet()
'''这里我用了个异常处理结构'''
try:
model.load_state_dict(torch.load('./save_model/best_model.pth'))
except :
'''如果模型是导入GPU训练的你需要把模型再导入回cpu'''
model.load_state_dict(torch.load('./save_model/best_model.pth',map_location=torch.device('cpu')))
transform = transforms.Compose([
transforms.Resize((224,224)),#统一大小
transforms.ToTensor(),#转换数据
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])#归一化
])
Val_dataset = ImageFolder(ROOT_test,transform=transform)
Val_dataloder = DataLoader(Val_dataset)
#取文件路径
all_files = []
file_list = os.walk(ROOT_test) # 获取当前路径下的所有文件和目录
for dirpath, dirnames, filenames in file_list: # 从file_list中获得三个元素
for file in filenames:
all_files.append(os.path.join(dirpath, file)) # 用os.path.join链接文件名和路径,跟新进all_files列表里
classes = [
'猫', '狗']#这里的答案顺序要和训练文件名字顺序一致
def prediect():
model.eval()
epoch=0
for x,y in Val_dataloder:
with torch.no_grad():
outputs = model(x)
outputs = torch.softmax(outputs,dim=1)#用softmax的特性在对数据进行一个标准化的概率预测值
max_pred, predicted = torch.max(outputs, 1)#取出数据最大值和最大值的标签
epoch+=1
print(f'epoch:{epoch} this picture maybe :{classes[predicted[0]]},pred:{max_pred.item()*100:.3f}%')
if __name__ == '__main__':
prediect()
运行结果:

彩蛋
猫猫送花

这张我最喜欢的猫猫送花图片模型预测是狗…

参考:https://www.bilibili.com/video/BV18L4y167jr?p=5&spm_id_from=333.880.my_history.page.click感谢炮哥