CNN入门介绍(什么是CNN)-Neuron Version Story
CNN
1.Image Classification
CNN常常被用于影像辨识。也就是一张图片然后去分类,决定里面有什么。在文章当中假设模型输入的图片大小固定。固定是100*100。实际图片有大有小而且不是所有图片都是正方形的啊,有长方形的怎么办。

今天常见的处理方式,丢进影像辨识系统处理方式就是,把所有图片都先 Rescale 成大小一样,再丢到影像的辨识系统里面。最终我们需要输出类别,所以用one-hot独热编码。目标叫做![]()
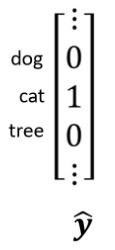
在这个 One-Hot 的 Vector 裡面,假设我们现在类别是一个猫的话,那猫所对应的 Dimension(维度),它的数值就是 1,
其他的东西所对的 Dimension 的数值就是 0那这个 Dimension 的长度就决定了,你现在的模型可以辨识出多少不同种类的东西,如果你向量的长度是
2000,就代表说你这个模型,可以辨识出 2000 种不同的东西,那今天比较强的影像辨识系统,往往可以辨识出1000 种以上的东西,甚至到上万种不同的 Object,那如果你今天希望你的影像辨识系统,它可以辨识上万种Object,那你的 Label 就会是一个上万维,维度是上万的 One-Hot Vector。
当很大的时候就是稍微有点多了

我的模型的输出通过 Softmax 以后,输出是 ,然后我们希望 和的 Cross Entropy 越小越好,接下来的问题是怎麼把一张影像当做一个模型的输入
其实对於一个 Machine 来说,一张图片其实是一个三维的 Tensor
tensor 即“张量”(翻译的真难理解,破概念)。实际上跟numpy数组、向量、矩阵的格式基本一样。但是是专门针对GPU来设计的,可以运行在GPU上来加快计算效率,不要被吓到。
在PyTorch中,张量Tensor是最基础的运算单位,与NumPy中的NDArray类似,张量表示的是一个多维矩阵。不同的是,PyTorch中的Tensor可以运行在GPU上,而NumPy的NDArray只能运行在CPU上。由于Tensor能在GPU上运行,因此大大加快了运算速度。
一句话总结:一个可以运行在gpu上的多维数据而已

一张图片它是一个三维的 Tensor,其中一维代表图片的宽,另外一维代表图片的高,还有一维代表图片的Channel 的数目。
一张彩色的图片,今天它每一个 Pixel,都是由 R G B 三个顏色所组成的,所以这三个 Channel 就代表了 R G B 三个顏色,那长跟宽就代表了今天这张图片的解析度,代表这张图片裡面有的 Pixel,有的像素的数目。
那接下来我们就要把这一个三维的 Tensor拉直,拉成一个向量,然后再丢到一个 Network 裡面去
到目前為止我们所讲的 Network,它的输入其实都是一个向量,所以我们只要能够把一张图片变成一个向量,我们就可以把它当做是 Network 的输入,但是怎麼把这个三维的 Tensor 变成一个向量呢,那最直觉的方法就是直接拉直它。
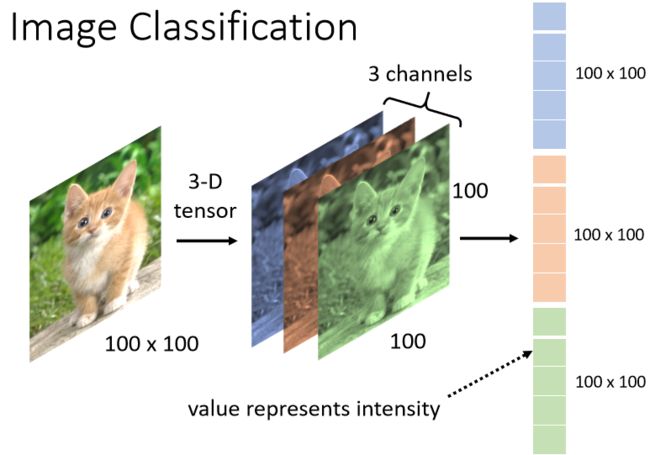
一个三维的 Tensor 裡面有几个数字呢
在这个例子裡面有 100 × 100×3 个数字,把这些数字通通拿出来排成一排,就是一个巨大的向量,这个向量可以作為 Network 的输入
而这个向量裡面,每一维它裡面存的数值,其实就是某一个 Pixel某一个顏色的强度,每一个 Pixel 有 RGB 三个顏色所组成。
对于这个向量,如果使用FCN(Fully Connected Network)把这个当成Network的输入,input这边的Feature Vector,长度就是100*100*3。此时如果第一层的(如果有好几层的话),每一个Neuron和每一个向量都会有一个数值,都会有一个Weight,所以说现在的Weight旧货用3*10的7次方那么多个。
虽然参数变多可以增加弹性,但是也会造成Overfitting的可能性。弹性越大就越可能Overfitting。
所以就会用到CNN。不需要每一个Neuron 和每一个input 的特征都要有一个Weight
Observation1
我们现在有一张图片,我们想知道里面这个到底是什么动物。也许对一个影像辨识的系统而言,对一个影像辨识的 Neuron,对一个影像辨识的类神经网路裡面的神经而言,它要做的就是侦测说现在这张图片裡面,有没有出现一些特别重要的 Pattern

比如说鸟喙,鸟眼,和鸟足。
举例来说 如果现在
1有某一个 Neuron ,它看到鸟嘴这个 Pattern
2有某个 Neuron 又说,它看到眼睛这个 Pattern
3又有某个 Neuron 说,它看到鸟爪这个 Pattern
也许看到这些 Pattern 综合起来就代表说,我们看到了一隻鸟,类神经网路就可以告诉你说,因為看到了这些Pattern,所以它看到了一隻鸟,通过多个Pattern综合起来。
于是说,我们其实不需要每一个Neuron去看一整张完整的图片。因为我们都是通过部分的pattern去判断一整个图片。所以这些 Neuron 也许根本就不需要,把整张图片当作输入,它们只需要把图片的一小部分当作输入,就足以让它们侦测某些特别关键的 Pattern有没有出现了这是第一个观察,根据这个观察,我们就可以做第一个简化 怎麼简化呢。
Simplification 1
在CNN里面有一个这样的做法,我们设定一个区域叫做Receptive Field,每一个 Neuron 都只关心自己的Receptive Field 裡面发生的事情就好了
举例来说 你会先定义说这个蓝色的 Neuron,它的守备范围就是这一个 Receptive Field,那这个 Receptive Field 裡面有 3×3×3 个数值,那对蓝色的 Neuron 来说,它只需要关心这一个小范围就好了,不需要在意整张图片裡面有什麼东西。那这个 Neuron,怎麼考虑这个 Receptive Field 裡,有没有发生什麼样的事情

Receptive field 感受野。
它要做的事情就是
1.把这 3×3×3 的数值拉直,变成一个长度是 3×3×3 也就是 27 维的向量,再把这 27 维的向量作為这个 Neuron 的输入
2.这个 Neuron 会给 27 维的向量的,每一个 Dimension 一个 Weight,所以这个 Neuron 有 3×3×3 27个Weight
3.再加上 Bias 得到的输出,这个输出再送给下一层的 Neuron 当作输入。

所以每一个 Neuron,它只考虑自己的 Receptive Field,那这个 Receptive Field 要怎麼决定出来呢,那这个就要问你自己了!!!但是说实话,怎么确认感受野还真的是一个问题

1. 你可以说这边有个蓝色的 Neuron,它就看左上角这个范围,这是它的 Receptive Field
2.另外又有另外一个黄色的 Neuron,它是看右下角这个 3×3×3 的范围
3.那 Receptive Field 彼此之间也可以是重叠的,比如说我现在画一个 Receptive Field,那这个地方它是绿色的 Neuron 的守备范围,它跟蓝色的跟黄色的都有一些重叠的空间
4.那你甚至可以两个不同的 Neuron,它们守备看到的范围是一样的,也许一个范围使用一个 Neuron 来守备,你没有办法侦测所有的 Pattern,所以同个范围可以有多个不同的 Neuron,所以同Receptive Field,它们可以有多个Neuron一起来,但是每一个专注的是不同的特征

那接下来,那举例来说。
1.那我可不可以 Receptive Field 有大有小呢?因為毕竟 Pattern 有的比较小 有的比较大,有的 Pattern 也许在 3×3 的范围内,就可以被侦测出来,有的 Pattern 也许要 11×11 的范围,才能被侦测出来,可以,这个算是常见的招式了
2.我可不可以 Receptive Field,只考虑某些 Channel 呢,我们这边看起来我们的 Receptive Field,是 R G B三个 Channel 都考虑,但也许有些 Pattern,只在红色的 Channel 会出现,也许有些 Pattern,只在蓝色的Channel 会出现啊,我可不可以有的 Neuron 只考虑一个 Channel 呢?可以,其实之后在讲到 Network Compression的时候,会讲到这种 Network 的架构,在一般 CNN 裡面你不常这样子的考虑,但是有这样子的做法
3.那有人会问说这边的 Receptive Field,通通都是正方形的,你刚才举的例子裡面,3×3 11×11 也都是正方形的,可不可以是长方形?可以!可以是长方形的,这完全都是你自己设计的,Receptive Field 是你自己定义的,你完全可以根据你对这个问题的理解,决定你觉得 Receptive Field 应该要长什麼样子
4.你可能会说 Receptive Field 一定要相连吗?我们可不可以说有一个 Neuron,它的 Receptive Field 就是影像的左上角,跟右上角。理论上可以,但是你就要想看為什麼你要这麼做嘛,会不会有什麼 Pattern 是会,也要看一个图片的左上角,跟右下角才能够找到的,也许没有 如果没有的话,这种 Receptive Field 就没什麼用,我们之所以 Receptive Field 都是,一个相连的领地,就是我们觉得要侦测一个 Pattern,那这个Pattern,它就出现在整个图片裡面的某一个位置,而不是出现,而不是分成好几部分,出现在图片裡面的不同的位置,所以 Receptive Field 呢 它都是相,通常见到的都是相连的领地。
如果你说你要设计很奇怪的Receptive Field, 去解决很 特别的问题,也是可以的。
Simplification 1 – Typical Setting
这里将介绍非常常见的,非常经典Receptive Field的安排方式
1. 看所有的 Channel

一般在做影像辨识的时候我们可能,你可能不会觉得有些 Pattern 只出现某一个 Channel 裡面,所以会看全部的 Channel,所以既然会看全部的 Channel
我们在描述一个 Receptive Field 的时候,只要讲它的高跟宽就好了,就不用讲它的深度,反正深度一定是考虑全部的 Channel,而这个高跟宽合起来叫做 Kernel Size(卷积核的size)
举例来说在这个例子裡面,我们的 Kernel Size 就是 3×3,那一般我们 Kernel Size 其实不会设太大,你在影像辨识裡面,往往做个 3×3 的 Kernel Size 就足够了,如果你说你设个 7×7 9×9,那这算是蛮大的 Kernel Size,一般往往都做 3×3
可能会有人疑问那如果 Kernel Size 都是 3×3,意味著说我们觉得在做影像辨识的时候,重要的 Pattern 都只在3×3 这麼小的范围内,就可以被侦测出来了,听起来好像怪怪的,有些 Pattern 也许很大啊,也许 3×3 的范围没办法侦测出来啊
等一下我们会再回答这个问题,那我现在先告诉你说,常见的 Receptive Field 设定方式,就是 Kernel Size 3×3,然后一般同一个 Receptive Field,不会只有一个 Neuron 去关照它,往往会有一组 一排 Neuron 去守备它,比如说 64 个 或者是 128 个 Neuron 去守备一个 Receptive Field 的范围,
2.到目前為止我们讲的都是一个 Receptive Field(感受野),那各个不同 Receptive Field 之间的关係,是怎麼样呢,你会把你在最左上角的这个 Receptive Field,往右移一点,然后製造一个另外一个 Receptive Field,这个移动的量叫做 Stride,即为步长。但是说实话,不同个特征到底怎么样决定搜查哪里我还是弄不灵清嘎。

Stride也是一个超参数,一般不会设置太大,一般都在一或者二。那 Stride 是一个你自己决定的 Hyperparameter。
因為你希望这些 Receptive Field,跟 Receptive Field 之间是有重叠的,因為假设 Receptive Field 完全没有重叠,那有一个 Pattern 就正好出现,在两个 Receptive Field 的交界上面,那就会变成没有任何 Neuron 去侦测它,那你也可能就会 Miss 掉这个 Pattern,所以我们希望 Receptive Field 彼此之间,有高度的重叠那假设我们设 Stride = 2,那第一个 Receptive Field 就在这边,那第二个就会在这边
3. 再往右移两格就放在这边,那这边就遇到一个问题了,它超出了影像这个像素的的范围怎麼办呢。
如果有一个Pattern正好在边角的范围,没有Neuron去观察守备那个Pattern,超出的地方就可以使用Padding(填充),就是补0,或者说补值,可以补全部的平均,或者边缘的数字
除了横值移动,还有直值移动,在垂直方向上的移动
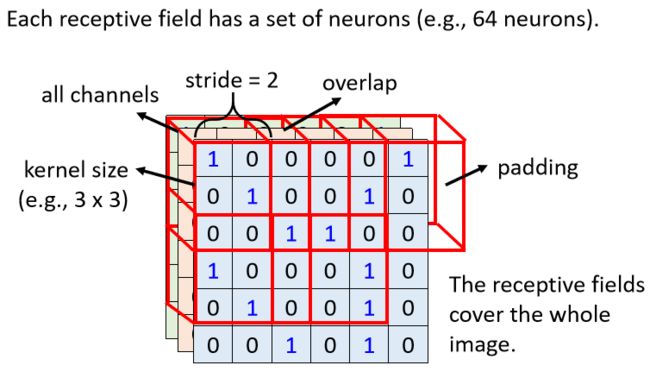
在这边呢 我们一样垂直方向 Stride 也是设 2,所以你有一个 Receptive Field 在这边,垂直方向移动两格,就有一个 Receptive Field 在这个地方,你就按照这个方式,扫过整张图片,所以整张图片裡面,每一吋土地都是有被某一个,Receptive Field 覆盖的,也就是图片裡面每一个位置,都有一群 Neuron 在侦测那个地方,有没有出现某些Pattern
好 那这个是第一个简化,Fully Connected Network 的方式