Pandas读取CSV文件
Pandas读取CSV文件
-
- 准备工作
- CSV文件自带列标题
-
- 直接读出不更改列标题名
- 把原列标题替换成自已的列标题
- CSV文件无自带列标题
-
- 读出数据系统自动给编号
- 给列添加标题
- 总结
准备工作
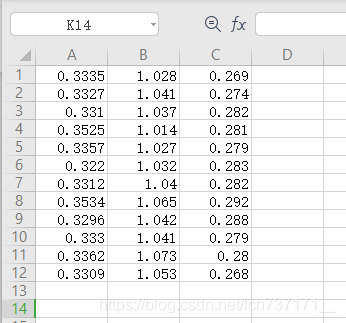
在任意文件夹下建一个CSV文件,如图下所示。
导入pandas
import pandas as pd
CSV文件自带列标题
直接读出不更改列标题名
data=pd.read_csv('c:\\mypatent\\ensemble1E0669\\IE6690pl.csv')
‘c:\mypatent\ensemble1E0669\IE6690pl.csv’,是CSV文件所在的文件夹路径及文件名
或者:
data=pd.read_csv('c:\\mypatent\\ensemble1E0669\\IE6690.csv',header=0)
data
显示结果
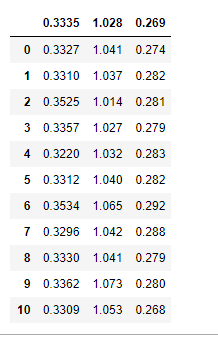
可以看出默认的第一行就是列标题名称。
也可以直接看列标题名和行索引。
先看行
data.index
显示结果:
RangeIndex(start=0, stop=11, step=1)
再看下列标题
data.columns
显示结果:
Index([‘0.3335’, ‘1.028’, ‘0.269’], dtype=‘object’)
把原列标题替换成自已的列标题
data=pd.read_csv('c:\\mypatent\\ensemble1E0669\\IE6690pl.csv')
data.columns=['A','B','C']
data
输出结果:
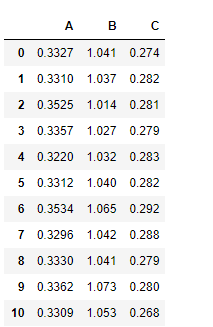
或者采用如下方式:
data=pd.read_csv('c:\\mypatent\\ensemble1E0669\\IE6690pl.csv',names=['A','B','C'])
data
输出结果是一样的。
注意:有列标题名和无列标题要搞清楚,否则有可能第一行实际数据被当成了列标题而不参与运算。
又或者
data=pd.read_csv('c:\\mypatent\\ensemble1E0669\\IE6690pl.csv',header=0,names=['A','B','C'])
上面三种方法效果是一样的。
CSV文件无自带列标题
csv文件没有列标题,从第一行就直接开始是数据了。
读出数据系统自动给编号
data=pd.read_csv('c:\\mypatent\\ensemble1E0669\\IE6690pl.csv',header=None)
data
输出结果如下:
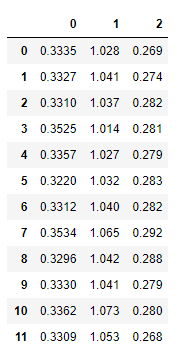 注意:一定要加’header=None’, 这样读进来的列名就是系统默认的0,1,2… 序列号
注意:一定要加’header=None’, 这样读进来的列名就是系统默认的0,1,2… 序列号
此时可以用系统给的序号进行操作,例如:
A=data[0]
B=data[1]
C=A+B
C
输出结果:

给列添加标题
data=pd.read_csv('c:\\mypatent\\ensemble1E0669\\IE6690pl.csv',header=None)
data.columns=['A','B','C']
data
输出结果
可看出列添加了新的标题。
或者采用如下方式。
data=pd.read_csv('c:\\mypatent\\ensemble1E0669\\IE6690pl.csv',header=None,names=['A','B','C'])
结果是一样。
注意:此处不可以用’header=0’, 用了会默认第一行数据是列名,然后又被重命名覆盖,结果是第一行的数据丢失。
总结
本节讲了Pandas读取CSV文件的方法,希望您能喜欢。