【15】Attentional Feature Fusion
最近看到一篇比较不错的特征融合方法,基于注意力机制的 AAF ,与此前的 SENet 、SKNet 等很相似,但 AFF 性能优于它们,并且适用于更广泛的场景,包括短和长跳连接以及在 Inception 层内引起的特征融合。AFF 是由南航提出的注意力特征融合,即插即用!
1、特征融合
1.1、什么是特征融合
特征融合是模式识别领域的一种重要方法,计算机视觉领域的图像识别问题作为一种特殊的模式分类问题,仍存在很多挑战,特征融合方法能够中和利用多种图像特征,实现多特征的优势互补,获得更加鲁棒和准确的识别结果。
1.2、特征融合的分类
(1)早融合(Early Fusion):在特征上进行融合,进行不同特征的连接,输入到一个模型中进行训练(先融合多层的特征,然后在融合后的特征上训练预测器,只有在完全融合之后,才进行检测)。这类方法也被称为skip connection,即采用concat、add操作,例如:DenseNet和ResNet。
skip connection的初衷是为了解决梯度消失的问题。在学习深度神经网络的参数时,通常都是通过梯度下降的方式,即从网络的输出层开始由后向输入层计算每一层的梯度。由于梯度通常是小于1的数值,当层数很多的时候,梯度就会变的越来越小。最终出现梯度消失的问题。当梯度无限接近于0,网络就没有办法更新学习了。所以就有了skip connection这个思路,简言之,在深度网络的中间层额外加入浅层的input,使得梯度的“路径”不再那么长。类似提供一个复合路径,在原来的“长路径”的基础上,现在额外添加一个“捷径”。Skip connection在本质上就是额外提供一个计算梯度的“捷径”。
(2)晚融合(Late Fusion):在预测分数上进行融合,做法就是训练多个模型,每个模型都会有一个预测分数,我们对所有模型的结果进行融合,得到最后的预测结果。(通过结合不同层的检测结果改进检测性能,尚未完成最终融合之前,在部分融合的层上酒开始检测,会有多层的检测,最终将多个检测结果进行融合)。这一思路的代表是feature不融合和feature进行金字塔融合,融合后进行预测。
2、注意特征融合
特征融合是指来自不同层次或分支的特征的组合,是现代神经网络体系结构中无所不在的一部分。它通常通过简单线性的操作(例如:求和或者串联来实现),但这可能不是最佳的选择。本文提出了一个统一的通用方案,即注意力特征融合( AFF ),该方案适用于大多数常见场景,包括短和长跳连接以及在 Inception 层内引起的特征融合。
为了更好地融合语义和尺度不一致的特征,我们提出了多尺度通道注意力模块 ( MS-CAM ),该模块解决了融合不同尺度特征时出现的问题。我们还证明了初始特征融合可能会成为瓶颈,并提出了迭代注意力特征融合模块(iAFF )来缓解此问题。
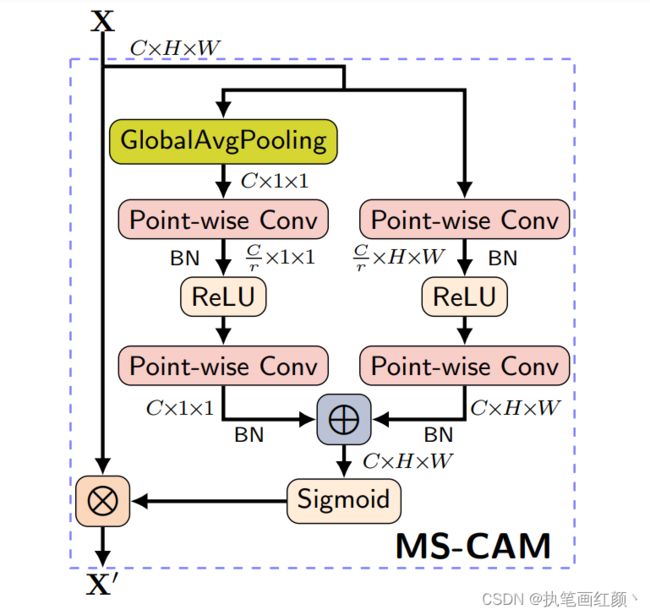
2.1、MS-CAM
(1)引入多尺度通道注意力模块(MSCAM),通过尺度不同的两个分支来提取通道注意力。
MS-CAM 主要是延续 SENet 的想法,再于 CNN 上结合 Local / Global 的特征,并在空间上用 Attention 来 融合多尺度信息 。MS-CAM 有 2 个较大的不同:
MS-CAM通过逐点卷积(1x1卷积)来关注通道的尺度问题,而不是大小不同的卷积核,使用点卷积,为了让MS-CAM尽可能的轻量化。MS-CAM不是在主干网中,而是在通道注意力模块中局部本地和全局的特征上下文特征。
(2)代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import torch
from torch import nn
import torch.nn.functional as F
import torchvision
class MS_CAM(nn.Module):
'''
单特征进行通道注意力加权,作用类似SE模块
'''
def __init__(self, channels=64, r=4):
super(MS_CAM, self).__init__()
inter_channels = int(channels // r)
# 局部注意力
self.local_att = nn.Sequential(
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
# 全局注意力
self.global_att = nn.Sequential(
nn.AdaptiveAvgPool2d(1), # senet中池化
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
xl = self.local_att(x)
xg = self.global_att(x)
xlg = xl + xg
wei = self.sigmoid(xlg)
return x * wei
inputs = torch.rand(10, 64, 100, 100)
layer = MS_CAM(64, 4)
out = layer(inputs)
print(out.shape)
2.2、AFF
(1)注意特征融合模块(AFF),适用于大多数常见场景,包括由short and long skip connections以及在Inception层内引起的特征融合。
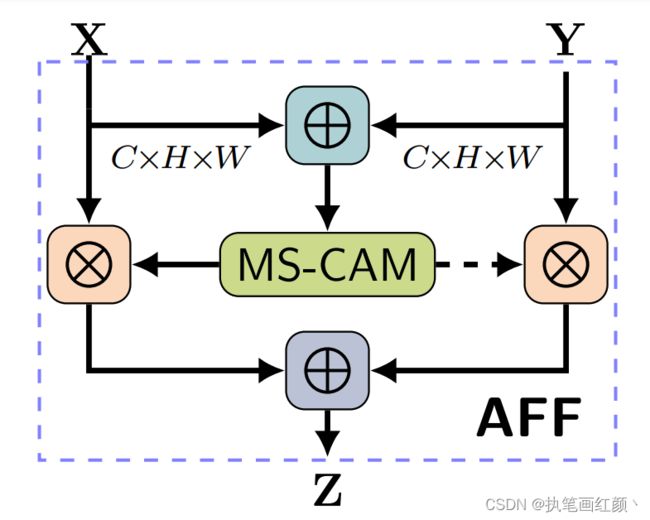
给定两个特征 X, Y 进行特征融合( Y 代表感受野更大的特征)。对输入的两个特征 X , Y 先做初始特征融合,再将得到的初始特征经过 MS-CAM 模块,经过 sigmod 激活函数,输出值为 0~1 之间,作者希望对 X 、Y 做加权平均,就用 1 减去这组 Fusion weight ,可以作到 Soft selection ,通过训练,让网络确定各自的权重。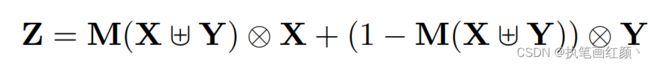
(2)代码
class AFF(nn.Module):
'''
多特征融合 AFF
'''
def __init__(self, channels=64, r=4):
super(AFF, self).__init__()
inter_channels = int(channels // r)
# 局部注意力
self.local_att = nn.Sequential(
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
# 全局注意力
self.global_att = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
self.sigmoid = nn.Sigmoid()
def forward(self, x, residual):
xa = x + residual
xl = self.local_att(xa)
xg = self.global_att(xa)
xlg = xl + xg
wei = self.sigmoid(xlg)
xo = x * wei + residual * (1 - wei)
return xo
2.3、IAFF
(1)迭代注意特征融合模块(IAFF),将初始特征融合与另一个注意力模块交替集成。
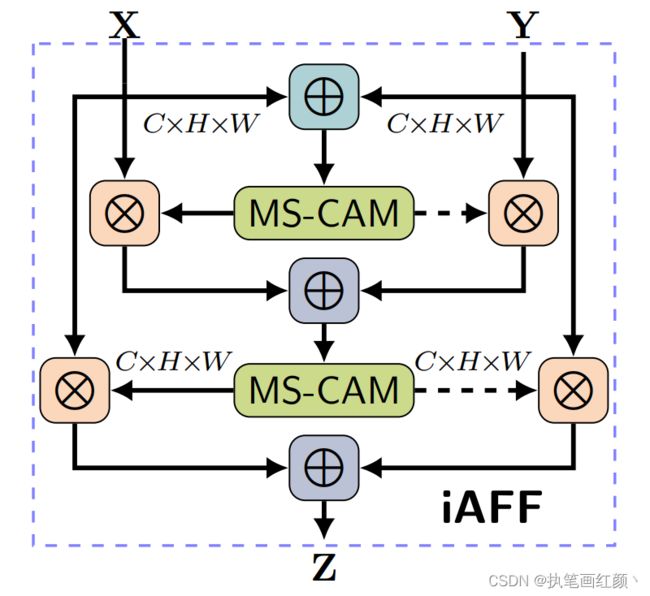
在注意力特征融合模块中,X , Y 初始特征的融合仅是简单对应元素相加,然后作为注意力模块的输入会对最终融合权重产生影响。作者认为如果想要对输入的特征图有完整的感知,只有将初始特征融合也采用注意力融合的机制,一种直观的方法是使用另一个 attention 模块来融合输入的特征。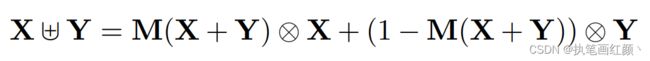
(2)代码
class iAFF(nn.Module):
'''
多特征融合 iAFF
'''
def __init__(self, channels=64, r=4):
super(iAFF, self).__init__()
inter_channels = int(channels // r)
# 局部注意力
self.local_att = nn.Sequential(
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
# 全局注意力
self.global_att = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
# 第二次局部注意力
self.local_att2 = nn.Sequential(
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
# 第二次全局注意力
self.global_att2 = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
self.sigmoid = nn.Sigmoid()
def forward(self, x, residual):
xa = x + residual
xl = self.local_att(xa)
xg = self.global_att(xa)
xlg = xl + xg
wei = self.sigmoid(xlg)
xi = x * wei + residual * (1 - wei)
xl2 = self.local_att2(xi)
xg2 = self.global_att(xi)
xlg2 = xl2 + xg2
wei2 = self.sigmoid(xlg2)
xo = x * wei2 + residual * (1 - wei2)
return xo
参考:
【WACV 2021】Attentional Feature Fusion - 知乎
Attentional Feature Fusion 注意力特征融合_总是提示已注册的博客-CSDN博客_attentional feature fusion
(学习笔记2)特征融合_DreamZ00的博客-CSDN博客_什么是特征融合