一文详解线性最小二乘与非线性最小二乘
一文详解线性最小二乘与非线性最小二乘
- 一、最小二乘法的引出
- 二、线性最小二乘法
-
- 1.线性最小二乘的描述
- 2.线性最小二乘特殊情况的求解
- 3.线性最小二乘一般情况的求解
- 三、非线性最小二乘法
-
- 1.非线性最小二乘的描述
- 2.非线性最小二乘的求解
-
- a. 最速下降法
- b.牛顿法
- c.高斯牛顿法
- d.LM法
一、最小二乘法的引出
我们考虑下面一个方程组的求解:
x 1 + x 2 = 5 x 1 − x 2 = 3 x 1 + x 2 = 4 x_1+x_2=5 \\ x_1-x_2=3 \\ x_1+x_2=4 \\ x1+x2=5x1−x2=3x1+x2=4
可以写成形如 A x = b Ax=b Ax=b的矩阵形式:
[ 1 1 1 − 1 1 1 ] [ x 1 x 2 ] = [ 5 3 4 ] \begin{bmatrix} 1 & 1\\ 1 & -1\\ 1 & 1 \end{bmatrix} \begin{bmatrix} x_1\\ x_2\\ \end{bmatrix} =\begin{bmatrix} 5\\ 3\\ 4 \end{bmatrix} ⎣ ⎡1111−11⎦ ⎤[x1x2]=⎣ ⎡534⎦ ⎤
由线性代数的知识可知,当方程个数m大于未知两个数n的时候,方程通常无解。但是对于 A x = b Ax=b Ax=b这个方程而言,我们仍然可以通过一些方法得到一个最接近解析解的一个向量,这个方法就是最小二乘法。
最小二乘法的抽象形式如下所示:
目标函数 = ∑ ( 观测值 − 理论值 ) 2 目标函数=\sum (观测值-理论值)^2 目标函数=∑(观测值−理论值)2
观测值指的就是我们的多组样本,而理论值就是我们假设的拟合函数。目标函数就是我们常说的损失函数。我们的目标是得到使目标函最小化时的拟合函数模型。
我们举一个简单的例子,假设有m个测试样本: ( x i , y i ) ( i = 1 , 2 , 3 , . . . . . . m ) (x_i,y_i)(i=1,2,3,......m) (xi,yi)(i=1,2,3,......m),我们需要找到一个n维的变量 x ∗ ∈ R x^* \in \mathbb{R} x∗∈R,使得损失函数 F ( x ) F(x) F(x)取得局部最小值:
F ( x ) = 1 2 ∑ i = 1 m ( f i ( x ) ) 2 F(x)=\frac{1}{2} \sum_{i=1}^m (f_i(x))^2 F(x)=21i=1∑m(fi(x))2
其中 f i f_i fi是残差函数,即测量值和预测值之间的差,且有 m > n m>n m>n。而局部最小值指任意的 ∣ ∣ x − x ∗ ∣ ∣ < δ ||x-x^*|| < \delta ∣∣x−x∗∣∣<δ 有 F ( x ∗ ) ≤ F ( x ) F(x^*) \leq F(x) F(x∗)≤F(x)。
二、线性最小二乘法
1.线性最小二乘的描述
对于 m m m个方程求解 n n n个未知数,有三种情况:
- m = n m=n m=n且A为非奇异,则有唯一解, x = A − 1 b x=A^{-1}b x=A−1b
- 当 m > n m>n m>n,约束的个数大于未知数的个数,称为超定方程(overdetermined)
- m < n m
m<n ,负定/欠定问题(underdetermind)
通常我们遇到的问题都是超定问题,此时 A x = b Ax=b Ax=b的解是不存在的,从而转向解最小二乘问题:
J ( x ) = m i n ∣ ∣ A x − b ∣ ∣ 2 2 J(x)=min||Ax-b||^2_2 J(x)=min∣∣Ax−b∣∣22
J ( x ) J(x) J(x)为凸函数,我们令一阶导数为0,可以得到:
x = ( A T A ) ( − 1 ) A T b x=(A^TA)^{(-1)}A^Tb x=(ATA)(−1)ATb
2.线性最小二乘特殊情况的求解
这时候我们考虑齐次方程 A x = 0 Ax=0 Ax=0,当A行数大于列数的特殊情况:
m i n ∣ ∣ A x ∣ ∣ min||Ax|| min∣∣Ax∣∣
此时的最小二乘解为 A T A A^TA ATA最小特征值对应的特征向量。我们可以通过以下方式进行求解;

3.线性最小二乘一般情况的求解
对于一个线性方程求解问题而言,最简单粗暴的方式是对 A T A A^TA ATA求逆,但是这种方式计算量极大,非常耗时,所以我们考虑用矩阵分解的方式加速线性最小二乘问题的求解。
矩阵分解是将矩阵拆解为数个矩阵的乘积,可分为三角分解、满秩分解、QR分解、Jordan分解、SVD(奇异值)分解等,常见的有三种:1)QR 分解法,2)Cholesky分解法,3)SVD分解法
- LU三角分解:三角分解法是将原正方 (square) 矩阵分解成一个上三角形矩阵和一个下三角形矩阵.
- QR分解:QR分解法是将矩阵分解成一个正规正交矩阵与上三角形矩阵,所以称为QR分解法。
- 奇异值分解:[U,S,V]=svd(A),其中U和V分别代表两个正交矩阵,而S代表一对角矩阵。SVD是最可靠的分解法,但是它比QR 分解法更加耗时。
- LLT分解:Cholesky 分解是把一个对称正定的矩阵表示成一个下三角矩阵L和其转置的乘积的分解。它要求矩阵的所有特征值必须大于零,故分解的下三角的对角元也是大于零的(LU三角分解法的变形)。
- LDLT分解法:其中L为下三角形单位矩阵,D为对角矩阵,L^T为L的转置矩阵。LDLT分解法实际上是Cholesky分解法的改进,因为Cholesky分解法虽然不需要选主元,但其运算过程中涉及到开方问题,而LDLT分解法则避免了这一问题。
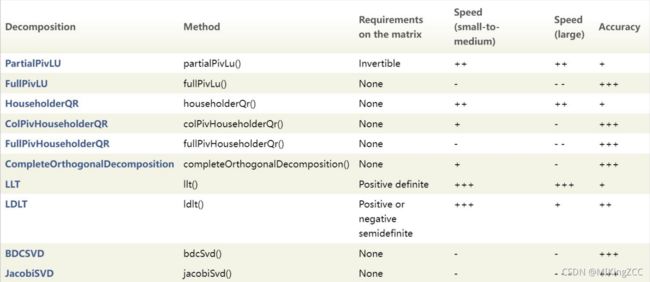
以下是eigen库中提供的矩阵分解求解线性最小二乘问题的方法,我们可以根据实际需求做出选择。
三、非线性最小二乘法
1.非线性最小二乘的描述
考虑一个非线性最小二乘模型如下:
F ( x ) = 1 2 ∑ i = 1 m ( f i ( x ) ) 2 F(x)=\frac{1}{2}\sum^m_{i=1} (f_i(x))^2 F(x)=21i=1∑m(fi(x))2
我们假设损失函数 F ( x ) F(x) F(x)是平滑可导的,所以我们在二阶泰勒展开有:
F ( x + Δ x ) = F ( x ) + J Δ x + 1 2 Δ x T H Δ x + O ( ∣ ∣ Δ ∣ ∣ 3 ) F(x+\Delta x)=F(x)+J\Delta x+\frac{1}{2}\Delta x^TH\Delta x+O(||\Delta||^3) F(x+Δx)=F(x)+JΔx+21ΔxTHΔx+O(∣∣Δ∣∣3)
其中 J J J和 H H H分别为损失函数 F F F对变量 x x x的一阶导和二阶导矩阵。
2.非线性最小二乘的求解
我们求解的思路是寻找一个下降方向使损失函数随 x x x的迭代逐渐减小,直到 x x x收敛到 x ∗ x^* x∗时有:
F ( x ∗ ) ≤ F ( x ) x ∈ ∀ F(x^*) \leq F(x) \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ x \in \forall F(x∗)≤F(x) x∈∀
所以我们需要寻找下降方向的单位向量 d d d和下降步长 α \alpha α。假设我们的 α \alpha α足够小,我们对损失函数 F ( x ) F(x) F(x)进行一阶泰勒展开:
F ( x + α d ) ≈ F ( x ) + α J d F(x+\alpha d) \approx F(x) +\alpha Jd F(x+αd)≈F(x)+αJd
我们的下降方向只要满足:
J d < 0 Jd < 0 Jd<0
而下降的步长可以通过线性搜索的方式寻找:
α ∗ = a r g m i n α > 0 F ( x + α d ) \alpha^*=argmin_{\alpha>0}{F(x+\alpha d)} α∗=argminα>0F(x+αd)
a. 最速下降法
从下降的方向条件可知: J d = ∣ ∣ J ∣ ∣ c o s θ Jd=||J||cos\theta Jd=∣∣J∣∣cosθ, θ \theta θ表示方向和梯度方向的夹角,当 θ = π \theta=\pi θ=π时:
d = − J T ∣ ∣ J ∣ ∣ d=\frac{-J^T}{||J||} d=∣∣J∣∣−JT
即梯度的负方向为最速下降方向,此时的缺点为最优值附件震荡,收敛慢。
b.牛顿法
在局部最优点 x ∗ x^* x∗附近时,若 x + Δ x x+\Delta x x+Δx是最优解,则损失函数对 Δ x \Delta x Δx的导数等于0:
∂ ∂ x ( F ( x ) + J Δ x + 1 2 Δ T H Δ x ) = J T + H Δ x = 0 \frac{\partial }{\partial x}(F(x)+J\Delta x+\frac{1}{2}\Delta^TH\Delta x)=J^T+H\Delta x=0 ∂x∂(F(x)+JΔx+21ΔTHΔx)=JT+HΔx=0
可以得到 : Δ x = − H − 1 J T \Delta x=-H^{-1}J^T Δx=−H−1JT,显然这种方法缺点非常明显,需要计算二阶导矩阵,计算比较复杂
c.高斯牛顿法
对残差函数 f ( x ) f(x) f(x)一阶泰勒展开:
f ( x + Δ x ) ≈ ζ ( Δ x ) = f ( x ) + J Δ x f(x+\Delta x) \approx \zeta(\Delta x)=f(x)+J\Delta x f(x+Δx)≈ζ(Δx)=f(x)+JΔx
需要注意的是这里的 J J J代表的是残差函数 f ( x ) f(x) f(x)的雅可比矩阵,我们带入损失函数有:
F ( x + Δ x ) ≈ L ( Δ x ) = 1 2 ζ ( Δ x ) T ζ ( Δ x ) = F ( x ) + Δ x T J T f + 1 2 Δ x T J T J Δ x F(x+\Delta x) \approx L(\Delta x) = \frac{1}{2}\zeta(\Delta x)^T\zeta(\Delta x) \\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ =F(x)+\Delta x^TJ^Tf+\frac{1}{2}\Delta x^TJ^TJ\Delta x F(x+Δx)≈L(Δx)=21ζ(Δx)Tζ(Δx) =F(x)+ΔxTJTf+21ΔxTJTJΔx
令上述公式的一阶导为0,我们可以得到:
( J T J ) Δ x g n = − J T f (J^TJ) \Delta x_{gn}=-J^Tf (JTJ)Δxgn=−JTf
常表述为: H Δ x g n = b H\Delta x_{gn}=b HΔxgn=b
d.LM法
LM法是高斯牛顿法和最速下降法的一种结合:
( J T J + u I ) Δ x l m = − J T f w i t h u ≥ 0 (J^TJ+uI)\Delta x_{lm} =-J^Tf \ \ \ \ \ \ \ \ \ with \ \ \ u\geq0 (JTJ+uI)Δxlm=−JTf with u≥0
相当于在求解过程中引入阻尼因子,其作用为:
- u > 0 u>0 u>0保证 ( J T J + u I ) (J^TJ+uI) (JTJ+uI)正定,迭代朝着下降的方向进行。
- u u u比较大时, Δ x l m = − 1 u J T f = − 1 u F ′ ( x ) T \Delta x_{lm}=-\frac{1}{u}J^Tf=-\frac{1}{u}F'(x)^T Δxlm=−u1JTf=−u1F′(x)T,接近最速下降法。
- u u u比较小时, Δ x l m ≈ Δ x g n \Delta x_{lm} \approx \Delta x_{gn} Δxlm≈Δxgn,接近高斯牛顿法。