又一篇视觉Transformer综述来了!
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达
最近 Transformer在CV领域真的"杀疯了",很多CV垂直方向出现了不少工作。其中非常有代表性就是:DETR、ViT等。
CVer上周第一时间推送了:华为&北大等联合最新提出的视觉Transformer综述,这周又来了一篇视觉Transformer新综述!内容和参考文献相对更加丰富一点。
注:文末附综述PDF下载和Transformer交流群
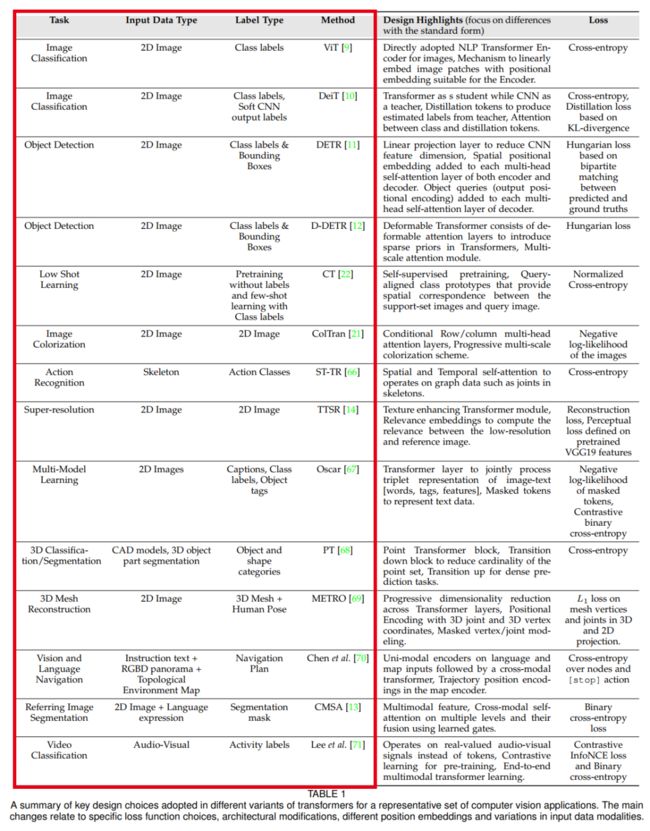
24页综述,共计170篇参考文献!本综述将视觉Transformer模型根据不同的任务进行分类和介绍(如分类、检测、行为识别、分割、GAN、low-level视觉、3D点云等)。
Transformers in Vision: A Survey

作者单位:人工智能大学(MBZUAI), IIAI等
论文下载链接:https://arxiv.org/abs/2101.01169
Transformer 模型在自然语言任务方面的惊人结果吸引了视觉界研究其在计算机视觉问题中的应用。
由下图可见BERT、自注意力和Transformer相关论文数量近年来增长的情况

这项调研旨在提供计算机视觉学科中的transformer 模型的全面概述,并且假设该领域的背景知识很少甚至没有。

我们从介绍transformer 模型成功背后的基本概念开始,即自监督(Self-supervision
)和自注意力(Self-Attention )。
Transformer 体系结构利用自注意力机制在输入域中对远程依赖项进行编码,从而使其具有较高的表达力。


由于他们假定对问题的结构缺乏先验知识,因此将使用前置任务的自监督应用于大规模(未标记)数据集上的预训练transformer 模型。然后,在下游任务上对学习到的表示进行微调,由于编码特征的泛化和表现力,通常可导致出色的性能。
视觉中的Transformer和自注意力
本综述涵盖了transformer 在视觉领域的广泛应用,包括流行的识别任务(例如图像分类,目标检测,动作识别和分割),生成模型,多模式任务(例如视觉问题解答和视觉推理),视频处理(例如活动识别,视频预测),low-level视觉(例如图像超分辨率和彩色化)和3D分析(例如点云分类和分割)。
一、用于图像识别的Transformer
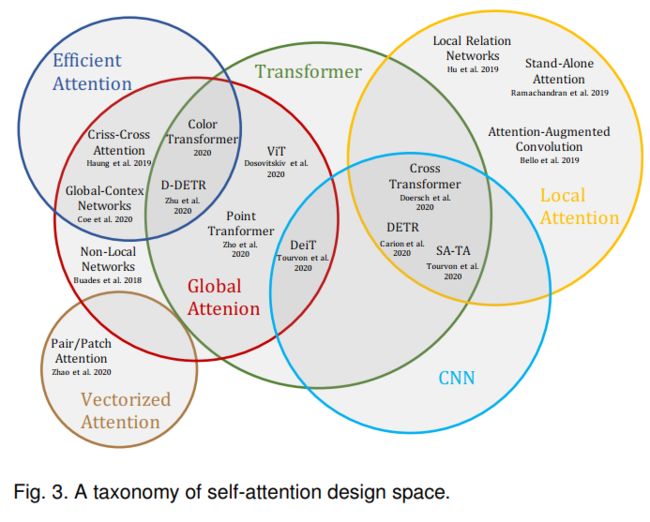
1. Non-local Neural Networks
2. Criss-cross Attention

推荐阅读:
视觉注意力机制 | Non-local模块与Self-attention的之间的关系与区别?
视觉注意力机制 | Non-local模块如何改进?来看CCNet、ANN
3. Stand-alone Self-Attention
4. Local Relation Networks

5. Attention Augmented Convolutional Networks
6. Vectorized Self-Attention

7. Vision Transformer

推荐阅读:
用Transformer完全替代CNN
8. Data-efficient Image Transformers

推荐阅读:
媲美CNN!Facebook提出DeiT:高效图像Transformer,在ImageNet上达84.4%准确率!
二、用于目标检测的Transformer
1. DETR

推荐阅读:
目标检测新坑来了!对标Faster R-CNN!FAIR提出DETR:用Transformers来进行端到端的目标检测
2. Deformable - DETR

推荐阅读:
训练加快10倍!性能更强!商汤等提出可变形DETR目标检测网络
三、用于分割的Transformer
1. Axial-attention for Panoptic Segmentation

推荐阅读:
ECCV 2020 实例分割+全景分割论文大盘点(14篇论文,10篇已开源)
2. CMSA: Cross-modal Self-Attention
四、用于图像生成的Transformer
1. Image GPT
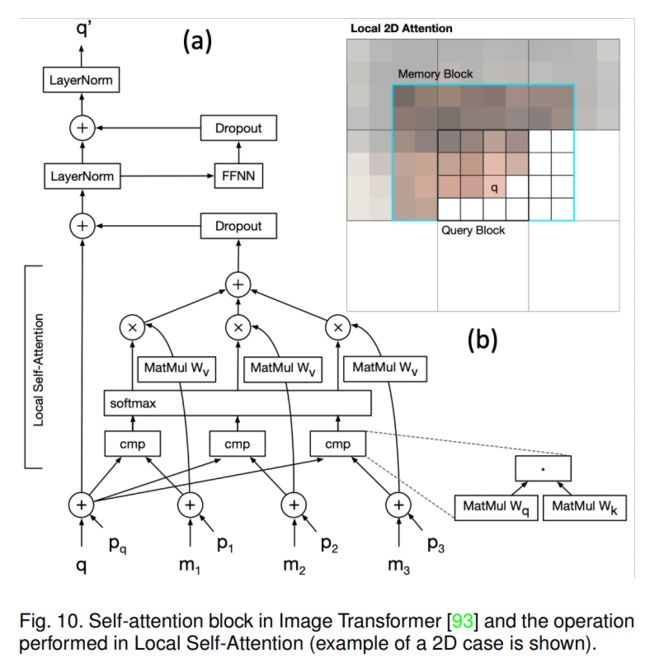
2. Image Transformer
3 High-resolution Image Synthesis
4. SceneFormer
五、用于low-level视觉的Transformer
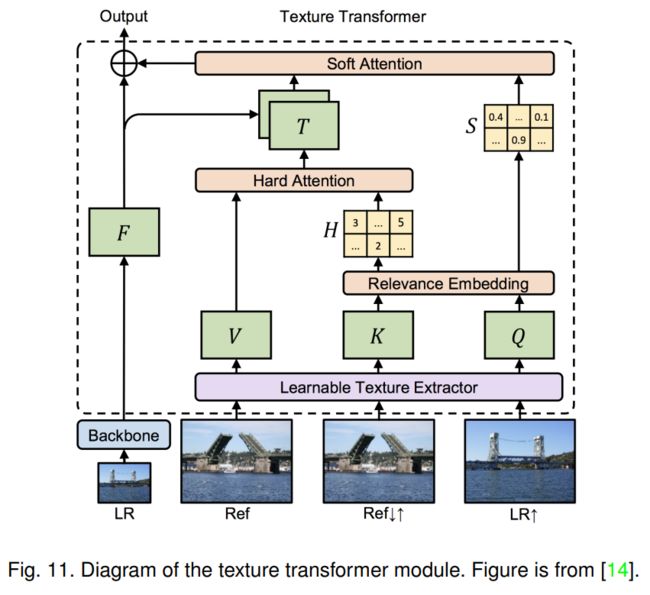
1. Transformers for super-resolution
2. Transformers for Image Enhancement Tasks

推荐阅读:
Transformer再下一城!low-level多个任务榜首被占领,北大华为等联合提出预训练模型IPT
3 Colorization Transformer

六、用于多模态任务的Transformer
1. ViLBERT: Vision and Language BERT
2. LXMERT
3. VisualBERT
4. VL-BERT
5. Unicoder-VL
6. UNITER
7. Oscar: Object-Semantics Aligned Pre-training
8. Vokenization
9. Vision-and-Language Navigation

七、用于视频理解的Transformer
1. VideoBERT: Joint Video and Language Modeling
2. Parameter Efficient Multi-modal Transformers
3. Video Action Transformer
4. Skeleton-based Action Recognition

八、用于Low-shot学习的Transformer
1. Cross-transformer
2. FEAT: Few-shot Embedding Adaptation

九、用于聚类的Transformer
十、用于3D分析的Transformer
1. Point Transformer

2. Point-cloud Transformer
3. Pose and Mesh Reconstruction

推荐阅读
清华大学提出点云Transformer!在3D点云分类、分割上表现优秀,核心代码已开源!
一图快速回顾上述精彩内容:
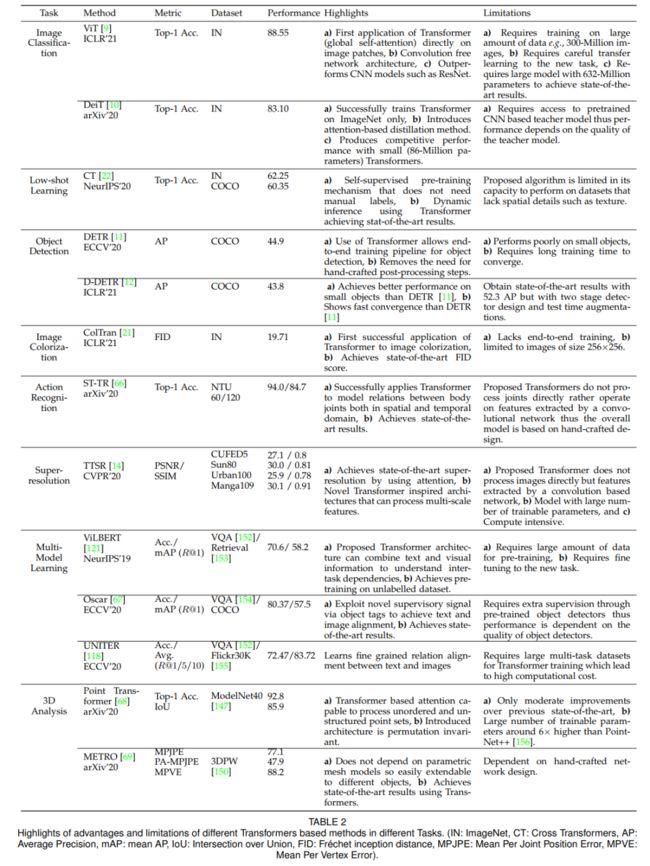
综述PDF下载
后台回复:Transformer综述2,即可下载论文PDF
重磅!Transformer大法 微信交流群已成立
扫码添加CVer小助手,可申请加入CVer-Transformer 微信交流群
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
整理不易,请给CVer点赞和在看!