YOLOV5 训练自己的数据集
本文章的所有代码和相关文章, 仅用于经验技术交流分享,禁止将相关技术应用到不正当途径,滥用技术产生的风险与本人无关。
本文章是自己学习的一些记录。
开始
最近打算重新做一个目标检测的项目,将项目的模型训练好之后再进行模型部署以及落地的实时监测与开发。
之前做过ssd框架的目标检测和yolov3的目标检测,通过查阅资料发现yolov5不仅在检测效果好,而且权重“体积”很小,于是本篇博客主要介绍使用自己的数据集跑通进行训练。
在这里贴上yolov5 github的地址:
https://github.com/ultralytics/yolov5
直接down下来压缩包就行
准备数据
对于我们要做的目标检测需要对图像数据进行标注,我使用的labelImg标注工具,对自己的数据进行打标(这里labelImg的用法不会的可以去百度一下),图像数据我是自己写的爬虫程序,爬取的图像数据。
从github yolov5仓库解压后,在yolov5-master/data文件下新建以下文件夹:
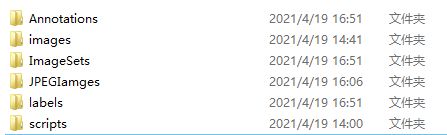
images文件夹放置图像文件(.jpg格式),Annotations文件夹放置标注好的xml文件,ImageSets文件夹放置生成的训练txt文件,labels放置生成的标签文件。
执行程序
完成标注文件后,在yolov5-master文件夹下新建split.py
#coding=utf-8
#@Time:2021/4/19 15:47
#@Author:csdn@hijacklei
#@File:split.py
#@Software:PyCharm
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'data/Annotations'
txtsavepath = 'data/ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('data/ImageSets/trainval.txt', 'w')
ftest = open('data/ImageSets/test.txt', 'w')
ftrain = open('data/ImageSets/train.txt', 'w')
fval = open('data/ImageSets/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
执行后在data/下的ImageSets文件夹下生成一下四个文件:

然后还是在yolov5-maste文件夹下新建voc_label.py文件
#coding=utf-8
#@Time:2021/4/19 15:52
#@Author:csdn@hijacklei
#@File:voc_label.py
#@Software:PyCharm
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test','val']
classes = ['你自己的类别']
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('data/Annotations/%s.xml' % (image_id))
out_file = open('data/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
print(wd)
for image_set in sets:
if not os.path.exists('data/labels/'):
os.makedirs('data/labels/')
image_ids = open('data/ImageSets/%s.txt' % (image_set)).read().strip().split()
list_file = open('data/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write('data/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
在classes = [‘你自己的类别’]这里换成你标注的时候的标签的类别
在执行这个voc_label.py文件的时候,可能有的人会出现这样的bug:
ZeroDivisionError: float division by zero
这是由于我们在标注的时候出现的问题,使得我们的标注的xml文件出现width和height出现0
![]()
所以要排查出我们标注的数据出现的这个xml文件,将其去除或者重新标注,可以参考我之前的博客,写过关于这个bug:
https://blog.csdn.net/hijacklei/article/details/113752039
执行voc_label.py文件,会在labels文件夹下生成数据的文本信息:
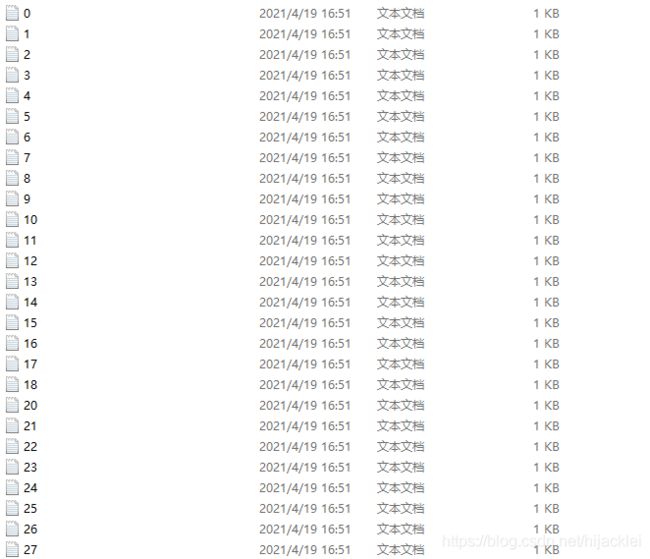
并且在data文件夹下会生成训练和验证、测试的文件:


修改配置文件
在准备好数据之后,准备训练,训练之前修改配置文件,在data文件夹下,找到coco.yaml文件:
![]()
复制一份,并且重命名为你的类别,yaml,比如你的类别是car,就写成car.yaml,在这个文件里面修改:
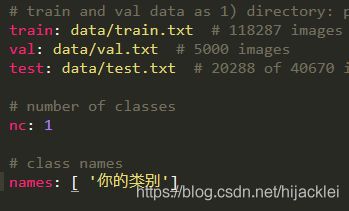
因为我的是一个类别,所以写成nc:1,上面的路径也写成你的路径
然后在models文件下找到yolov5s.yaml文件,进行修改,改成自己的类别;

此时需要下载yolov5的预权重文件,从官网下载较慢,这里我下好了直接百度网盘分享给你们:
链接:https://pan.baidu.com/s/1gKyOZ2Mjj2dJy_lrTxBzyQ
提取码:2s5s
复制这段内容后打开百度网盘手机App,操作更方便哦
下载后,将yolov5s.pt权重文件放到weights文件夹下
对train.py文件进行修改后,就可以训练了,打开改文件,修改这几处:
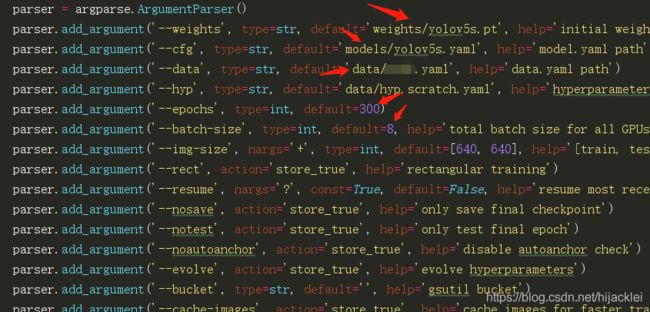
batch_size的设置取决于你的显卡的配置,显卡不好,设置的小一点。我先设置的8,其他的你自己改成对应的自己的路径即可。
开始训练
这里有个很重要的步骤,就是配置环境,可以根据yolov5-master文件下的requirements文件中的配置,进行手动和自动配置;
自动配置:
创建虚拟环境之后,执行:
pip install -U -r requirements.txt
由于我实在阿里云服务器上跑的,可以使用gpu跑,配置也较好配置,pytorch配置1.7.0以上就行
!pip3 install torch==1.7.0 -f https://download.pytorch.org/whl/torch_stable.html
![]()
配置好就可以训练了:执行train.py,我训练了300个epochs
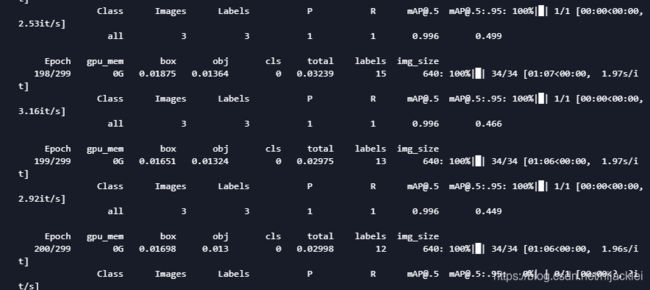
目前训练了200个epoch,从训练的情况来看,我的batch_size还可以设置的再大些
主要是配置还算给力:

目前训练了四个小时了:接下来就等训练完看测试和训练的指标
结束
训练的话会遇到的bug主要是cuda和torch的版本匹配,这里的cuda是10.0,torch是1.7.0
等跑完了,下一篇博客做测试
有什么问题评论区大家讨论