[Transformer]Mobile-Former:Bridging MobileNet and Transformer
Mobile-Former:连接MobileNet与Transformer form
- Abstract
- Section I Introduction
- Section II Related Work
-
- Light-weight convolutional neural networks
- CNN 与 ViT结合
- Section III Our Method: Mobile-Former
-
- Part 1 Overview
- Part 2 Mobile-Former Block
- Part 3 network specification
- Section IV Efficient End-to-End Object Detection
- Section V Experimental Results
-
- Part 1 ImageNet Classification
- Part 2 Ablations
- Part 3 Object Detection
- Section VI Limitations and Discussions
- Section VII Conclusion
- Appendix
-
- Appendix A
- Appendix C Visualization
CVPR2022
Microsoft & USTC
Abstract
本文提出的Mobile-Former是一种并行的将MobileNet与Transformer桥接在一起的结构,这种结构一方面利用MobileNet局部特征提取的优势另一方面利用Transformer在全局建模的优势,允许局部和全局特征的双向融合。而且不像近期的工作包含token数目很少,Mobile-Fromer计算效率很高,因为是一种轻量级网络,可以设置更多的token数目,因此表征能力更强。与MibileNetV3相比,在拥有更少FLOP基础上获得了更好的精度,在ImageNet数据集上,FLOP=294M时top-1精度为77.9%,与MobileNetV3相比节省了17%的算力,性能提升1.3%;并且通过将DETR中的encoder和decoder替换为本文的基准框架,比原始的DETR做目标检测性能提升1.1AP,同时计算成本减少了52%,参数量减少了36%。
Section I Introduction
近期ViT在提取全局依赖等方面超过了CNN,但是将FLOPs限制在1G以内ViT的优势就消失了,仍然是MobileNet的天下,尤其是在300M FLOPs量级,用于ImageNet分类,主要得益于MobileNet中采用的深度可分离卷积,自然就产生一个问题:
如何设计高效的网络可以有效同时处理局部和全局的交互关系?
一种可行的办法就是将卷积与ViT相结合,也有一些工作验证了将二者串行在一起的有效性。本文将串行连接变为并行,提出一种新的将并行的MobileNet和Transformer桥接的网络-Mobile-Former,具体结构参见Fig 1.
![[Transformer]Mobile-Former:Bridging MobileNet and Transformer_第1张图片](http://img.e-com-net.com/image/info8/da5ebbec172447e6a9fc8cf40c9f5b3f.jpg)
Mobile部分将输入通过深度可分离卷积处理来提取局部特征,Transformer设置一定数量的token,堆叠注意力模块和FFN模块来编码全局信息。
Mobile和Former之间通过一个双向桥接器进行通信,进行局部和全局的融合,这一步至关重要,这样将局部特征也作为Former的token输入,同时Former提取的全局特征也会加入到特征图谱的每一个像素中。本文提出一个轻量级的交叉注意力来建模这一双向桥接,在(a)通道数较少的瓶颈处计算交叉注意,并且(b)Mobile段删除Q-K-V的投影。
这种并行的结构同时利用了两种网络的优点,更重要的是局部-全局的信息交换是通过一个轻量级的稀疏Transformer实现,进展总计算成本的20%,但却能显著提升性能。
Mobile-Former在分类和目标检测任务中均取得了有益的性能。
分类: 294M flops时达到了77.9%的top-1精度,优于MobileNetV3和LeViT;并且在25M-500M flops范围内内Mobile-Former一直优于CNN和ViT模型。
目标检测任务中也优于MobileNetV3做backbone的RetinaNet,获得了8.2AP的性能提升,同时计算成本更低。与DETR相比,在同样的queries设置下获得了1.1AP的性能提升,同时FLOPs更少,模型规模更小。
本文想强调的是Mobile-Former的最优参数配置-如网络宽度、深度等并不是本文的目标,而是想阐明这种并行的设计是一种高效且有效的网络结构。
Section II Related Work
Light-weight convolutional neural networks
MobileNet通过堆叠深度可分离卷积来编码局部特征;ShuffleNet则通过组卷积和通道shuffle简化pointwise convolution;MicroNett提出使用微分解卷积的方法扩大网络宽度,降低阶段连接性来搭建FLOPs基底的情况。Dynamic operators则研究使用动态算子来提升MobileNet的性能,还有的其他优化提出使用butterfly transform,GhostNet提出使用简便的线性变换,AdderNet使用了加法来替代乘法;MixConv则看就混合卷积核大小的计算。
## Vision Transformer
近期ViT及其变体在诸多计算机视觉任务中取得了惊人的性能,最初的ViT需要在大规模数据集上预训练的结果,比如JFT-300M,DeiT提出在中小型数据集上有效训练的策略;随后Swin Transformer通过在移动局部窗口内计算自注意力使得可以处理高分辨率输入,CSWin则是使用cross-shaped window,T2T-ViT通过递归的聚合相邻的token,逐步将图像转换为标记;HaloNet则是通过注意力降采样和阻塞局部注意力提升速度、内存利用率等。
CNN 与 ViT结合
近期也有诸多工作研究如何将CNN与ViT结合,比如BoTNet通过将ResNet最后三层替换为自注意力有效提升了做实例分割和目标检测的精度;ConViT提出一种门控的位置相关的注意力来引入软性卷积偏置;CvT则是在多头注意力之前引入了深度可分离卷积;LeViT则使用卷积来替代自注意力之前的切patch方式。
本文提出一种不同的以并行的方式来结合MobileNet与Transformer,并且可以双向传递。最终以更低的FLOPs达到了超过CNN和ViT变体的性能。
Section III Our Method: Mobile-Former
![[Transformer]Mobile-Former:Bridging MobileNet and Transformer_第2张图片](http://img.e-com-net.com/image/info8/4600be5ce38f47b6893736ff95e63119.jpg)
Part 1 Overview
Fig 3展示了Mobile-Former的模块结构,Fig 1展示了Mobile-Former的整体框架。
Parallel structure:
MobileNet与Transformer是并行的,并且通过双向交叉注意将他们连接起来。Mobile将输入通过倒置模块来提取特征,Former以token作为输入,最开始是随机初始化的。与ViT不同的地方在于ViT使用线性投影,本文的token数目更少,每一块都代表图像的全局先验,这样计算成本更小。
Low cost rwo-way bridge:
Former和Mobile通过一个双向桥进行交互,二者是双向融合的,分别表示为Mobile->Former和Former->Mobile,本文使用一个轻量级的交叉注意力来建模,Mobile->Former计算过程如下:
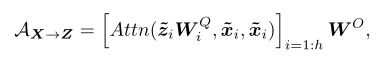
Former->Mobile计算过程如下:
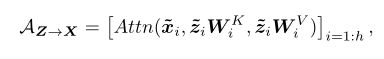
X代表局部特征,Z代表Former部分的token序列,交叉注意力计算的就是二者之间的关联。 可以看到key和value在Mobile端的计算中是移除的,只保留query矩阵;而Former端则是仅保留Mobile的key,value部分。
Part 2 Mobile-Former Block
Mobile-Former通过堆叠Mobile-Former模块组成,每一个模块包含四部分:Mobile子块,Former子块,两路交叉注意力:Mobile->Former和Former->Mobile
输入和输出:
Mobile->Former有两个输入:局部特征X(CxHxW)和全局序列Z(Mxd)。M和d对于所有模块都是一样的,模块的输出作为更新后的输入特征X’和全局序列Z’
Mobile sub-block
Mobile自块的输入是特征图谱,输出则作为Mobile->Former的输入,与原始的倒置瓶颈模块区别在于将ReLU激活替换为dynamic ReLU,参数是对特征图平均池化结果再经过两层MLP生成,块找那个卷积核大小为3x3.
Former sub-block:
Former子块则是标准的Transformer模块,包含MHSA和FFN,FFN中的扩展率为2,不是原始设置的4,并且在模块后使用层归一化。
Mobile -> Former
Mobile -> Former提出的轻量级交叉注意力负责将局部特征融合到全局标记序列中,与标准的注意力计算相比,移除了Wk和Wv这部分的投影矩阵,来降低计算量。
Former->Mobile
Former->Mobile负责将全局特征融合到局部特征图中,局部特征保留的是query矩阵,token保留的是key和value。
计算复杂度
对于输入特征图HW x C,token维度Mxd
Mobile部分计算量最大 为O(HWC^2)
Former计算量为O(M2d+Md2)
双向交叉注意力的计算量分别为O(MHWC+MdC)
Part 3 network specification
Architecture
Table 1展示了Mobile-Former的结构设定,294FLOPs,输入图像尺寸为224x224,共堆叠了11层Mobile-Former模块,每一个block包含6个token,维度为192.stage1是3x3卷积和一个bottleneckz block,stage2-5分别是逐渐降低分辨率的Mobile-Former模块,下采样使用的是均值池化,最后经过两层全连接层后作为输出。
![[Transformer]Mobile-Former:Bridging MobileNet and Transformer_第3张图片](http://img.e-com-net.com/image/info8/fb125eef2fa0456180a8adcf0dec11b9.jpg)
Mobile-Former变体:
通过灵活设定Mobile-Former的参数搭建不同规格的网络,从26M-508M,主要在于h,w不同。
Section IV Efficient End-to-End Object Detection
Mobile-Former的backbone和head都非常适合做目标检测,以更少的FLOPs数达到了超过DETR的效果。
Backbone-Head Architecture
Fig 4展示了用来目标检测的基准框架,主要包含6个global token,每一个注意力头包含100个query,与DETR类似,但是与DETR不同之处在于本文使用了多尺度的输入(1/32,1/16,1/8)这样使得FLOPs更少。上采样操作使用的是双线性插值,所有的query会逐渐从粗粒度到细粒度,其他的则遵循DETR的设定,如FFN,损失函数等。其中head从头训练,backbone采用ImageNet上预训练后的结果。
![[Transformer]Mobile-Former:Bridging MobileNet and Transformer_第4张图片](http://img.e-com-net.com/image/info8/bad23824a9924a879856415ef76f3e36.jpg)
最终搭建的Mobile-Former共41.4G FLOPs,大大少于DETR的86G FLOPs,但是却比DETR提升了1.1AP,Table 13展示了具体结构。
Spatial-aware dynamic ReLU in backbone
本文将所有global token参考在内,而不是只是用第一个token,这样从空间共享变成空间感知,因为每一个token关注的焦点都不同。可以看到spatial-aware dynamic ReLU对特征图每一个位置都计算一个参数,这样将所有token都考虑在内了。
α就代表的是位置i与tokenj之间的注意力关系
Adapting position embedding in head
DETR在decoder所有层共享query的位置嵌入,本文则更加精细的使用每一个head每一个block位置嵌入信息,取第k个模块的特这栋图和位置嵌入的和来计算注意力系数,其中g表示两层MLP+ReLU激活
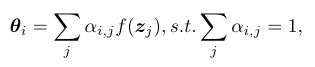
Section V Experimental Results
Part 1 ImageNet Classification
训练设置
输入图像分辨率224x224,优化器AdamW,训练450epochs,batch_size = 1024
数据增强:Mixup,auto-augmentation,random-erasing
Comparison with efficient CNNs
Table 2展示了与不同规格CNN网络的对比结果,分别是mobileNet和shufflenet,可以看到Mobile-Former一直优于对应CNN网络,并且计算量更少,虽然在150 M flops量级比shufflenet略大,但是性能获得了提升,75.2% vs 69.1%,这说明本文这种并行设计有效提升了表征能力。
Comparison with ViTs
Table 3展示的是与不同ViT的对比,分别是DeiT,T2T-ViT,ConViT,CoaT,Swin等,所有的都不借助teacher模型蒸馏的知识
![[Transformer]Mobile-Former:Bridging MobileNet and Transformer_第5张图片](http://img.e-com-net.com/image/info8/478e7148eb1240f9b938f35e87410303.jpg)
![[Transformer]Mobile-Former:Bridging MobileNet and Transformer_第6张图片](http://img.e-com-net.com/image/info8/d7db1bf17e95433a97e3f2fa540f30ec.jpg)
Mobile-Former在计算成本降低3-4倍的情况下取得了更高的精度,因为使用更少的token来建模全局关联,并且Mobie-Net可以有效提取局部特征;值得注意的是不经过teracher model蒸馏下训练450个epoch的结果比LeViT使用教师网络训练1000epoch性能更优,同时FLOPs也更少(294M vs 305M)
![[Transformer]Mobile-Former:Bridging MobileNet and Transformer_第7张图片](http://img.e-com-net.com/image/info8/d5a1dc966c9249a9b39dbcd5327314c1.jpg)
Accuracy-Flop plot
Fig 2对比了Mobile-Former与其他网络的精度-flops性能,可以看到Mobile-Former超过了CNN和ViT,说明并行设计的有效性,虽然Transformer在效率上不及CNN但本文的实验表明,基于Transformer的模型在适当的架构设计情况下也可以达到很低的FLOPs。
Part 2 Ablations
下面进行消融实验,所有模型训练300epoches,并且总结一些有趣的实验现象。
**Mobile-Former is effective.**
Mobile-Former比MobileNet更有效,因为通过Former结构编码了全局信息,参见Table 4,增加了Former连接后增加了12%的计算成本但是获得了2.6%的精度提升;此外使用dynamic ReLU也获得了1.0%的精度提升,本文还发现增大深度可分离卷积的卷积核只能带来细微提升,因为Mobile的感受野已经通过Former大大扩大了。
![[Transformer]Mobile-Former:Bridging MobileNet and Transformer_第8张图片](http://img.e-com-net.com/image/info8/850b95cc2bbc4e71820776f75556c619.jpg)
**Mobile-Former is efficient.**
实验结果显示Former只需要少量低纬度的global token就能带来性能提升,这种高效的并行设计也很稳定,将FFN移除、多头注意力替换为位置混合MLP都可以。
Table 5展示了不同token数目对性能的影响,token dimension=192,可以看到即使使用单头注意力都能达到77.1%的top-1精度,增加token数目会带来性能的提升,直到token数目增长到6.这种紧凑的设计时Mobile-Former高效的关键。
![[Transformer]Mobile-Former:Bridging MobileNet and Transformer_第9张图片](http://img.e-com-net.com/image/info8/0805e151acf64767995e7937fa790c95.jpg)
**Token dimension:**
Table 6展示了token length(或者说长度)对性能的影响,可以看到token dimension从64增长到192,性能从76.8%提升至77.8%,因此本文最终选用6个 维度192的global token,计算量只占总体网络的12%(35M vs 294M)
**FFN in Former:**
Table 7展示了移除FFN层对模型性能的影响,可以看到FFN对Mobile-Former的贡献跟梢,因为并不只有FFN能够进行通道融合,Mobile中的1X1卷积也有同样的功能,因此已经很好的融合了局部和全局特征。
Mulit-head Attention:
Table 7还展示了MHSA对模型性能的影响,可以看到用MLP替换MHSA后,精度从77.8%变为77.3%,因为MLP是静态的,不会随着输入变化。
Mobile-Former is explainable:
本文还观察到一些有趣的实验现象,首先从低到高global token的关注焦点逐渐从边角移动到前景和背景,最终聚焦于最显著的区域;其次交叉注意力在低层多样性更丰富;第三点是在Former->Mobile的中间层结果就能看到前景和背景的区别。详情参见附录C
![[Transformer]Mobile-Former:Bridging MobileNet and Transformer_第10张图片](http://img.e-com-net.com/image/info8/a9be0d0abb8e4515b80391555c6f6ec2.jpg)
Part 3 Object Detection
目标检测任务在COCO2017数据集上展开,COCO数据集包含118K训练图像和5K张验证图像,分别使用两种框架CNN框架-RetinaNet、Transformer框架-DETR。
RetinaNet将backbone替换为Mobile-Former,所有模块在ImageNet上训练12 epochs。
DETR上所有Mobile-Former模块训练300epoches,AdamW优化器、lr=1e-5(backbone)1e-4(head)
![[Transformer]Mobile-Former:Bridging MobileNet and Transformer_第11张图片](http://img.e-com-net.com/image/info8/db49f83d0779401086c697664c651e6f.jpg)
Efficient and Effective backbone in RetinaNet
Table 8展示了与CNN模型对比的结果,可以看到Mobile-Former比MobileNetV3和ShffleNetV2提升了8.2AP,计算成本接近;与ResNet以及Transformer变体相比在FLOPs更少的前提达到了更高的性能。
**Efficient and Effective end-to-end detector:**
Table 9展示了与DETR的对比结果,可以看到FLOPs减少48%,精度提升了1.1AP
Ablations of key components:
Table 10展示了本文的关键部件:Dynamic ReLU,multi-scale Mobile-Former head以及adaping position embnedding的效果,可以看到分别带来了1.2AP、0.9AP和1.7AP的性能提升。三者结合最终带来3.7AP的性能提升。
![[Transformer]Mobile-Former:Bridging MobileNet and Transformer_第12张图片](http://img.e-com-net.com/image/info8/e7f3a5e3c91c401188144a57e276eecc.jpg)
Section VI Limitations and Discussions
虽然Mobile-Former比MobileNet推理时间更短,二者FLOPs相近时还是Mobile-Former精度更高,但是随着图像越来越小其推理速度会变慢,这部分可以参考Fig 5。主要由于Former部分的位置嵌入和Mobile->Former、Former->Mobile都是与分辨率无关的,这一部分的pytorch实现就不如卷积那么搞笑;在图像较小时这部分的计算开销就凸显出来了。通过进一步优化这些组件可以进一步提升运行时的性能。
另一局限是在进行图像分类任务时的效率不是那么搞笑,主要是分类头部分参数量很大,比如在294M下占据了40%的参数量。当做目标检测任务时这一问题有所缓解。
Section VII Conclusion
本文提出的Mobile-Former是一种新的将MobileNet与Transformer融合的并行框架,有效利用了MobileNet高效提取局部特征和Transformer编码全局关联的优势,有效提升了计算效率和模型精度,超过了对应CNN和Transformer模型。本文希望Mobile-Former可以鼓励关于CNN和Transformer新的高效设计。
Appendix
Appendix A
Seven model variants
Table 11展示了6种Mobile-Former的变体,最小的FLOPs为26M,YU 52M的差距在于将所有的1x1卷积替换为组卷积,随着stage加深channel数目不断增加,expansion ratio从3增长到6,对于后面4个较大的网络模型,本文使用6个全局token,d = 192
![[Transformer]Mobile-Former:Bridging MobileNet and Transformer_第13张图片](http://img.e-com-net.com/image/info8/f78b440187be45d7bef1d6acb09eda0f.jpg)
Downsample Mobile-Former blocks
stage 2-5含有下采样的Mobile-Former block主要用于降低空间分辨率,核心就是包含4个卷积层(depthwise→pointwise→depthwise→pointwise),第一个深度卷积的步长为2,这样就起到了降分辨率的效果。以及每一次深度卷积都会扩张通道数,在逐点卷积在恢复回来,这样可以减少计算量。
Table 12是训练的超参数,随着网络规模的增大超参数会逐渐增大以免过拟合。
![[Transformer]Mobile-Former:Bridging MobileNet and Transformer_第14张图片](http://img.e-com-net.com/image/info8/81dcd815079b49cdb400e90ceb6ee73e.jpg)
## Appendix B More Experimental Results
Inference latency
Fig 5对比了Mobile-Former-214M和MobileNetV3 Large的推理延迟。在分辨率较小的时候(224X224)是Mobile-Former占优,随着分辨率增加,差距逐渐缩小,750x750后是MobileNet更快。
主要是因为Former和projection部分的计算与分辨率无关,以及这部分的pytorch实现不如卷积那么高效
![[Transformer]Mobile-Former:Bridging MobileNet and Transformer_第15张图片](http://img.e-com-net.com/image/info8/82e43bc922974b98802815e1c320752f.jpg)
Ablation of the kernel size in Mobile
Table 14展示了Mobile模块中深度卷积的卷积核尺寸对性能的影响。可以看到随着卷积核的提升模型性能没什么变化,主要是因为Former和bridge已经足够扩大了感受野,有效融合了全局特征,因此没必要使用大卷积核。
![[Transformer]Mobile-Former:Bridging MobileNet and Transformer_第16张图片](http://img.e-com-net.com/image/info8/841aef8e432b47aa90580fd647213076.jpg)
Appendix C Visualization
本文还可视化了两个bridge的特征图,分IE展示在Fig6-8.
Global tokens shift focus over levels
Fig 6展示的是Mobile-Former第一个global token的结果,可以看到这个token是专注于局部特征的token,比如边角处,以及会更多的关注像素连通的区域,并且聚焦区域会在前景和背景之间来回移动,最后聚焦到了最具鉴别性的区域(马的身体和头部)
![[Transformer]Mobile-Former:Bridging MobileNet and Transformer_第17张图片](http://img.e-com-net.com/image/info8/cf34a23042094d509fe3a348cc6056a0.jpg)
Foreground and background are separated in middle layers
Fig 7说明的是中间层的token结果可以明显的区分开前景和背景,比如block 8的个token ,说明global token学习到了有意义的相似像素特征。
![[Transformer]Mobile-Former:Bridging MobileNet and Transformer_第18张图片](http://img.e-com-net.com/image/info8/803a421297fb42809268c82aea156de2.jpg)
Attention dicersity across tokens diminishes
第三个想说的是在low level注意力的多样性优于high level,参见Fig 8,每一列代表一个token,每一行代表注意力头。可以清晰地看出,block 3和block 5的6个token的注意力模式都是不一样的,但是block 12的最后5个token其注意力模式几乎一样。
Fig 9展示了two-way bridge的所有block的注意力可视化结果。
![[Transformer]Mobile-Former:Bridging MobileNet and Transformer_第19张图片](http://img.e-com-net.com/image/info8/f019c11829184c789904409f53fac18f.jpg)
![[Transformer]Mobile-Former:Bridging MobileNet and Transformer_第20张图片](http://img.e-com-net.com/image/info8/58f07735bd4648e8bfea3d0fc7412779.jpg)