R-VQA: Learning Visual Relation Facts with Semantic Attention for Visual Question Answering
博主水平有限,大部分为机翻
摘要:
最近,视觉问答(VQA)已经成为多模式学习中最重要的任务之一,因为它需要理解视觉和文本模式。现有方法主要依靠提取图像和问题特征来通过多模态融合或注意机制来学习它们的联合特征嵌入。最近的一些研究利用外部VQA独立模型来检测图像中的候选实体或属性,其作为与VQA任务互补的语义知识。但是,这些候选实体或属性可能与VQA任务无关,并且语义容量有限。为了更好地利用图像中的语义知识,我们提出了一种新的框架来学习VQA的视觉关联事实。具体来说,我们通过语义相似性模块建立基于Visual Genome数据集的Relation VQA(R-VQA)数据集,其中每个数据由图像,相应问题,正确答案和支持关联事实组成。然后采用明确定义的关系检测器来预测与视觉问题相关的关联事实。我们进一步提出了一个由视觉注意和语义关注组成的多步骤注意模型,以提取相关的视觉知识和语义知识。我们对两个基准数据集进行了全面的实验,证明我们的模型实现了最先进的性能并验证了考虑视觉关联事实的好处。
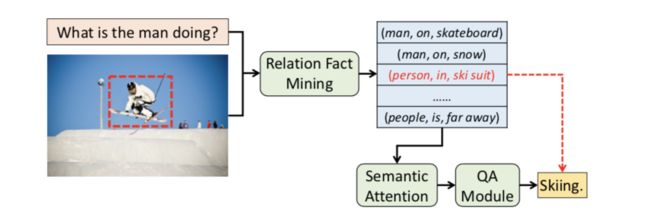
图1:我们提出的模型,它学习如何通过语义关注来挖掘关联事实以进行视觉问题回答。
1 介绍
随着自然语言处理,计算机视觉,知识嵌入和推理以及多模态表示学习的大发展,视觉问答已成为近年来的一个热门研究课题。 VQA任务需要为具有相应图像的问题提供正确答案,这被视为评估机器智能的重要图灵测试。 VQA问题可以轻松扩展到其他任务,并在各种应用程序中发挥重要作用,包括人机交互和医疗援助。 然而,很难解决这个问题,因为人工智能系统需要理解语言和视觉内容,提取和编码必要的常识和语义知识,然后进行推理以获得最终答案。 由于多模态嵌入方法和关注机制,研究人员在VQA开发方面取得了显着进展。
主流方法首先通过RNN模型提取语言特征嵌入,并通过预训练模型嵌入图像特征,然后通过多模式融合(如元素加法或乘法)学习它们的联合嵌入,最后将其馈送到顺序网络生成自由形式的答案或多类分类器,以预测最相关的答案。受图像字幕的启发,一些VQA方法[16,32,33]引入了语义概念,例如来自现成CV方法的实体和属性,这些方法为模型提供了各种语义信息。与实体和属性相比,关联事实具有更大的语义能力,因为它们由三个元素组成:主体实体,关系和对象实体,导致大量组合。例如,在图1中,给出问题“图中的人在做什么”和图像,关系事实如(man, standing on, skateboard),(man, on, ice), (person, in, ski suit)能够为问答提供重要的语义信息。
VQA面临的主要挑战在于从语言到图像的语义鸿沟。 为了处理语义鸿沟,现有的尝试有两种形式。 具体而言,一些方法提取高级语义信息[16,32,33],如实体,属性,甚至知识库[16]中的检索结果,如DBpedia [2]和Freebase [5]。 其他方法引入视觉关注[14,36,38]来选择对应于显着视觉信息的相关图像区域。 不幸的是,引入语义知识的这种方法仍然在两个方面受限。 一方面,他们使用实体或属性作为高级语义概念,这些概念是独立的,仅涵盖受限制的知识信息。 另一方面,当他们基于其他任务或数据集中的现成CV方法提取概念时,候选概念可能与VQA任务无关。
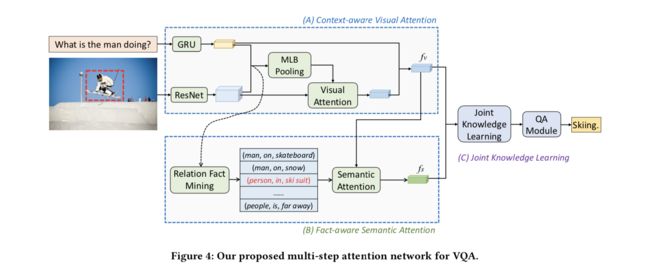
为了充分利用图像中的语义知识,我们提出了一种新的VQA语义关注模型。我们基于Visual Genome数据集构建了一个包含超过335k数据样本的大规模Relation-VQA(R-VQA)数据集。每个数据实例由图像,相关问题和在语义上类似于图像 - 问题对的关系事实组成。然后,我们采用关系检测器来预测给定图像和问题的最相关的视觉关系事实。我们进一步提出了一种新颖的多步骤关注模型,将视觉注意力和语义注意力结合到一个连续的注意力框架中。我们的模型由三个主要组成部分组成(见图4)。视觉关注模块(子部分5.1)用于提取图像特征表示。然后将视觉关注模块的输出馈入语义关注(5.2小节),其学习选择由关系检测器生成的重要关系事实(第4节)。最后,联合知识学习(5.3小节)应用于同时学习基于视觉和语义特征嵌入的视觉知识和语义知识。
我们的主要工作主要是以下的四个方面:
- 我们提出了一种新颖的VQA框架,它将学习视觉关系事实作为语义知识来帮助回答问题。
- 我们开发了多步骤语义保持网络(MSAN),它将视觉关注和语义关注相结合,同时学习视觉和语义知识表示。
- 为此,我们建立了一个有关关系事实的大规模VQA数据集,并设计了一个细粒度关系检测器模型。
- 我们在两个基准数据集上评估我们的模型,并获得了最优的性能。 我们还进行了大量实验来说明我们模型的有效性。
2 相关工作
2.1 视觉问答
作为自然语言处理,知识表达和推理以及计算机视觉的交叉研究方向,视觉问答的任务最近在多个研究领域引起了越来越多的关注。 目前已经构建了一系列大规模的相关数据集,包括VQA [1],COCO-QA [27]和Visual Genome [15]数据集。 一个常用的框架是首先使用长期短期记忆网络(LSTM)将每个问题编码为语义向量,并通过预先训练的卷积神经网络(CNN)提取图像特征,然后融合这两个特征来预测答案。 与[12,26,35]中使用简单特征融合(如元素操作或连接)的工作相比,有效的双线性池化方法在[4,8,14]中得到了很好的研究和发展。
2.2 关注机制
关注网络最近在知识挖掘和自然语言处理的许多应用中取得了显着的成功,例如神经机器翻译[3],推荐系统[30],广告[42],文档分类[39],情感分析[22],问题回答[17]和其他方面(Bahdanau等)。 [3]引入了一种关注机制,自动选择与预测目标词相关的源句中的部分词,从而提高了基本编码器 - 解码器架构的性能。Long 等人 [22]提出了一种基于认知的注意力(CBA)层,用于神经情感分析,以帮助捕捉源句中单词的注意。与上述不同的是,他的做法不是从词级关注,句子级[39]和文档级关注[30]入手而是更全面地关注整个文本内容。关注机制也已成功应用于计算机视觉任务,如图像字幕[40],图像检索[21],图像分类[34],图像流行度预测[43]等。
受自然语言处理和计算机视觉关注机制取得的巨大成功的启发,许多VQA方法使用关注机制以提高模型性能。 针对VQA的当前关注方法[36,38]主要进行视觉关注以学习与问题相关的图像区域。 最近的一些作品[8,9,13,14]将有效的多模态特征嵌入与视觉关注相结合,以进一步提高VQA性能( 最近由Lu等人发表)。 [24]设计了一种新颖的双重关注网络,它引入了两种类型的视觉特征,并使学习问题相关的自由形式和基于检测的图像区域成为可能。 与这些研究不同,我们提出了一种新颖的连续关注机制,可以无缝地结合VQA的视觉和语义线索。
2.3 语义事实
关联事实,代表两个实体之间的关系,在知识图中的表示和推理中起着重要作用。关联事实的编码和应用已经在知识表示的多个任务中得到了广泛的研究[6,29]。视觉关系检测是一项新兴的任务,旨在产生关联事实[19,23],例如(男人,骑,自行车)和(男人,推,自行车),捕捉图像中的实体对之间的各种相互作用。
现有的相关VQA方法涉及使用知识信息来获得实体和属性的检索结果[16,32,33],或者根据问题查询检测图像中的高级概念[31]。然而,通过简单地将图像中的语义知识视为实体和属性来利用问题和图像之间的复杂语义关系是不够有效的。据我们所知,在VQA中引入关联事实以提供丰富的语义知识仍然很少见。为了在VQA任务中利用关联事实,我们提出有效地学习关联事实并通过语义关注选择相关事实。
引入
在本节中,我们首先阐述本文中提到的VQA问题,然后阐明该问题的主要框架。
3.1 问题形式化
给定问题 Q Q Q和相关图像 I I I,VQA算法被设计为基于语言和图像内容预测最可能的答案 a ^ \hat{a} a^。 主要方法将VQA定义为候选答案短语空间中的多类分类问题,这些问题来自训练数据中最常见的答案。 这可以表述为
(1) a ^ = a r g m a x a ∈ Ω p ( a ∣ Q , I : Θ ) , \hat{a}=\underset{a\in\Omega}{argmax}\;p(a|Q,I:\Theta)\tag{1}, a^=a∈Ωargmaxp(a∣Q,I:Θ),(1)
其中 Θ \Theta Θ表示模型的参数, Ω \Omega Ω表示候选答案的集合。
3.2 通用框架
VQA的通用框架由三个主要部分组成:图像嵌入模型,问题嵌入模型和联合特征学习模型。 像[10,28]这样的CNN模型用于图像模型中以提取图像特征表示。 例如,典型的深度残差网络ResNet-152 [10]可以从汇集层之前的最后一个卷积层中提取图像特征映射v,其由下式给出:
(2) v = C N N ( I ) , v=CNN(I)\tag{2}, v=CNN(I),(2)
在馈入CNN模型之前,输入图像的大小从原图像调整为448×448像素。 从CNN模型提取的卷积特征图规模为2048×14×14,其中14×14是其对应于不同图像区域的空间大小,2048表示每个区域的特征嵌入维度的数量。
对于问题模型,利用长期短期记忆(LSTM)[11]和门控递归单位(GRU)[7]等递归神经网络来获得问题语义表示,其由下式给出:
(3) q = R N N ( Q ) . q=RNN(Q).\tag{3} q=RNN(Q).(3)
具体而言,给定T字的问题,每个问题字的嵌入被顺序地馈送到RNN模型中。 将RNN模型的最终隐藏状态 h T h_T hT作为问题嵌入。
然后通过多模式汇集将问题和图像表示共同嵌入到同一空间中,包括元素乘积或和,或是这些操作的串联
(4) h = Φ ( v , q ) , h=\Phi(v,q),\tag{4} h=Φ(v,q),(4)
其中 Φ \Phi Φ是多模式池化模块。 然后将联合表示h馈送到预测最终答案的分类器。
大量的近期作品结合了视觉关注机制,以实现更有效的视觉特征嵌入。 通常,引入语义相似性层来计算问题和图像区域之间的相关性,定义为:
(5) m i = s i g m o i d ( ψ ( q , v i ) ) , m_i=sigmoid(\psi(q,v_i)),\tag{5} mi=sigmoid(ψ(q,vi)),(5)
其中 ψ \psi ψ是语义相似度的模块,sigmoid是一种sigmoid类型的函数,如softmax,用于将语义结果映射到值区间[0,1], m i m_i mi是一个图像区域的语义权重。 最后,通过所有图像区域的加权和更新图像的视觉表示:
(6) v ~ = ∑ i = 1 14 × 14 m i v i , \tilde v=\sum_{i=1}^{14\times14}m_iv_i,\tag{6} v~=i=1∑14×14mivi,(6)
这能够突出显示与输入问题最相关的图像区域的表示。
4 关联事实检测
在本节中,我们将描述收集Relation-VQA(R-VQA)数据集的过程,以及4.1小节中的数据分析。 然后,我们在4.2小节中基于R-VQA设计关联事实检测器,以预测与给定问题和图像相关的视觉关联事实,并在第5节中进一步纳入我们的VQA模型。
4.1 Relation-VQA数据收集
对现有数据集的调查 现有的VQA数据集如VQA [1]和COCO-QA [27]由图像,问题和已标记的答案组成,不涉及支持语义关联事实。 虽然Visual Genome Dataset [15]提供了语义知识信息,例如关于图像部分的对象,属性和视觉关系,但它们与相应的问答对不一致。 因此,我们基于语义相似性扩展Visual Genome并构建Relation-VQA数据集,该数据集由问题,图像,答案和对齐的语义知识组成。 该数据集将在https://github.com/lupantech/rvqa上发布。
数据收集 我们首先定义本文中使用的关联事实,如表1所示。关联事实被分类为三种类型之一:实体概念,实体属性和实体关系,基于概念,属性和关系的语义数据分别在Visual Genome中。 为简单起见,实体属性中的属性可以是形容词,名词或介词短语。 对于Visual Genome,大多数图像都提供了相关的问答配对,图像的一部分用语义知识注释。 因此,我们保留包含问答配对和语义知识的图像,并以上述模板的形式将这些语义知识视为候选事实。

然后采用响应排序,[37]中提出的语义相似性排序方法来计算每个QA对与其候选事实之间的相关性。应该注意的是,如图2所示:R-VQA数据集上的示例。对于每个图像 - 问题 - 答案对,数据集提供其对齐的关联事实。算法在我们的框架中兼容,我们只采用最先进的排名方法之一,如响应排名。我们在未来的工作中留下更好的排名算法的选择或设计。从响应排名模块获得的相关性匹配分数的范围从0到1,值0表示候选事实与给定的QA数据完全无关,而值1表示完全相关。最后,在删除低于特定阈值匹配分数的候选事实之后,选择具有最高分数的事实作为基础事实。我们将生成的数据随机分为训练集(60%),开发集(20%)和测试集(20%)。表2显示了具有不同匹配分数阈值的R-VQA的数据大小。
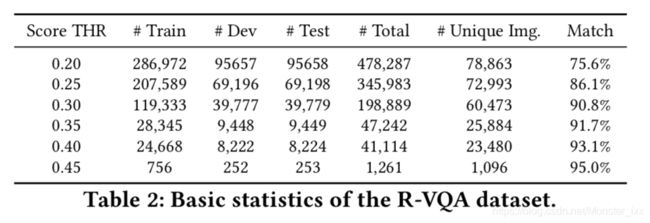
人力评估 为了确保匹配事实的质量,我们雇用众包工作者来标记所产生的事实是否与给定的QA对密切相关。 对于具有特定阈值分数的每个生成的数据集,我们随机抽样1,000个用于人类标记的示例,并要求三个工作人员对其进行标记。 每个数据集的最终准确度是三名工人获得的平均准确度。 此外,鼓励工作人员在三秒钟以上标记每个问题 - 答案 - 事实元组。 正如我们在表2中所看到的,随着相关性得分阈值的增加,R-VQA数据集具有更高的匹配精度以及更小的数据大小。 图2显示了R-VQA数据集中的两个示例,其得分阈值为0.30。
数据分析 为了平衡匹配事实的质量和数据样本的数量,我们通过选择匹配得分阈值0.30进行折衷,得出198,889个样本的数据集,所有问题 - 答案 - 事实的三元组平均匹配准确度为90.8%元组。 共有5,833,2,608和6,914个独特主题,关系和对象,涵盖了广泛的语义主题。 在表3中,我们可以看到生成的R-VQA数据集上最常见的主题,关系,对象和事实的分布。


4.2 关联事实检测器
Relation-VQA数据集提供198,889图像 - 问题 - 答案 - 事实,匹配分数为0.30。 也就是说,对于数据集中的每个图像,提供了与图像内容相对应的问题和正确答案,以及良好支持问答数据的关联事实。 如前所述,关联事实描述了语义知识信息,这有利于VQA模型,具有更好的图像理解。 由于这些原因,我们开发了一个关联事实检测器来获得与问题和图像语义内容相关的关联事实。 事实检测器将在我们的基于事实的关系VQA模型中进一步扩展,如第5节所示。
检测器建模 给定输入图像和问题,我们将事实预测表示为[19,20]之后的多任务分类。 对于图像嵌入层,我们将调整大小的图像提供给预先训练的ResNet-152 [10],并将最后一个卷积层的输出作为输入图像内容的空间表示。 然后我们添加一个空间平均池图层来提取密集图像表示 v ∈ R 2048 v\in R^{2048} v∈R2048为
(7) v = M e a n p o o l i n g ( C N N ( I ) ) . v=Meanpooling(CNN(I)).\tag{7} v=Meanpooling(CNN(I)).(7)
采用门控递归单元(GRU)网络将输入问题语义特征编码为 q ∈ R 2400 q∈R^{2400} q∈R2400
(8) q = G R U ( Q ) . q=GRU(Q).\tag{8} q=GRU(Q).(8)
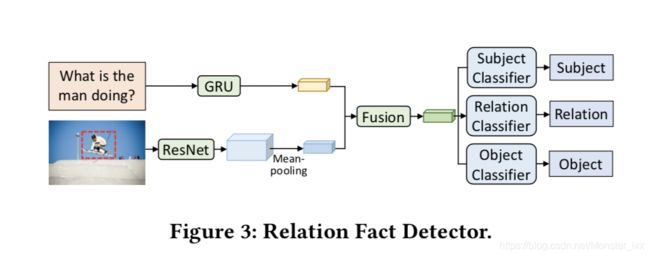
为了在共享语义空间中对图像和问题进行编码,将特征表示v和q分别馈送到线性变换层,然后是非线性激活函数,如下面的等式,
(9) f v = t a n h ( W v v + b v ) , f q = t a n h ( W q q + b q ) , f_v=tanh(W_vv+b_v),f_q=tanh(W_qq+b_q),\tag{9} fv=tanh(Wvv+bv),fq=tanh(Wqq+bq),(9)
其中 W v W_v Wv, W b W_b Wb, b v b_v bv, b q b_q bq是线性变换的可变参数,而 t a n h tanh tanh是双曲正切函数。
(10) h = t a n h ( W v h f v + W q h f q + b h ) . h=tanh(W_{vh}f_v+W_{qh}f_q+b_h).\tag{10} h=tanh(Wvhfv+Wqhfq+bh).(10)
其中元素加法用于两种方式的融合策略。 在融合图像和问题表示之后,学习一组线性分类器来预测关联事实中的主体,关系和对象,
(11) p s u b = s o f t m a x ( W h s h + b s ) , p_{sub}=softmax(W_{hs}h+b_s),\tag{11} psub=softmax(Whsh+bs),(11)
(12) p r e l = s o f t m a x ( W h r h + b r ) , p_{rel}=softmax(W_{hr}h+b_r),\tag{12} prel=softmax(Whrh+br),(12)
(13) p o b j = s o f t m a x ( W h o h + b o ) , p_{obj}=softmax(W_{ho}h+b_o),\tag{13} pobj=softmax(Whoh+bo),(13)
其中 p s u b p_{sub} psub, p r e l p_{rel} prel, p o b j p_{obj} pobj分别表示主体,关系和对象的分类在预先特定的候选者中的概率。 我们的损失函数将组分类器组合为
(14) L t = λ s L ( s , s ^ ) + λ r L ( r , r ^ ) + λ o L ( o , o ^ ) + λ w ∣ ∣ W ∣ ∣ 2 , L_t=\lambda_sL(s,\hat{s})+\lambda_rL(r,\hat{r})+\lambda_oL(o,\hat{o})+\lambda_w||W||_2,\tag{14} Lt=λsL(s,s^)+λrL(r,r^)+λoL(o,o^)+λw∣∣W∣∣2,(14)
其中s,r,o是目标主体,关系和对象, s ^ , r ^ , o ^ \hat{s},\hat{r},\hat{o} s^,r^,o^是预测结果。 λ s = 1.0 λ_s= 1.0 λs=1.0, λ r = 0.8 λ_r= 0.8 λr=0.8, λ o = 1.2 λ_o= 1.2 λo=1.2是通过验证集上的网格搜索获得的超参数。 L表示用于多类分类的交叉熵准则函数。 添加L2正则化项以防止过拟合,并且在我们的实验中正则化权重 λ w λ_w λw被设置为 1 × 1 0 − 7 1\times10^{-7} 1×10−7。
实验 给定输入图像和问题,所提出的关系检测器的目标是生成一组关联事实主体,关系,与图像和问题的语义内容相关的对象。 预测事实的可能性是方程11-13中主体,关系和对象的概率之和。 我们在学习的训练和验证集以及评估测试集上进行实验。
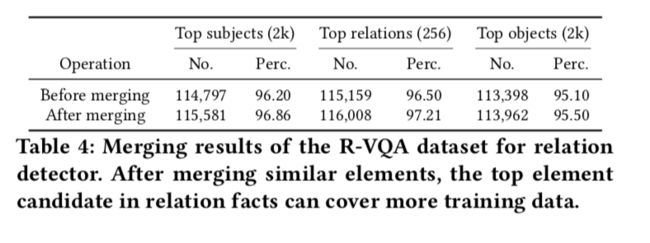
在进行实验之前,执行数据预处理的一些基本操作。 据观察,在R-VQA上存在一些相似且同义的事实要素,这可能会混淆事实检测的训练。 例如,“on”与“on the top of”与“on”,“tree”与“trees”等等。因此,我们将这些不明确的元素合并为基于别名概念词典的最简单形式。 [15],例如,“on the top of”和“is on”被简化为“on”。 合并结果如表4所示。我们从训练数据中的所有独特候选者中获取最频繁的主题,关系和对象,分别导致2,000个主题,256个关系和2,000个对象,更多细节如表4所示。
我们报告的评估指标是Recall@ 1,Recall@ 5,Recall@ 10,类似于[23]。Recall@ k被定义为在排名前k的预测事实中预测正确关联事实的数字分数。采用RMSProp学习方法训练探测器,初始学习率为 3 × 1 0 − 4 3\times10^{-4} 3×10−4,动量为0.98,权重衰减为0.01。批量大小设置为100,并且在每个线性转换层之前应用退出策略。
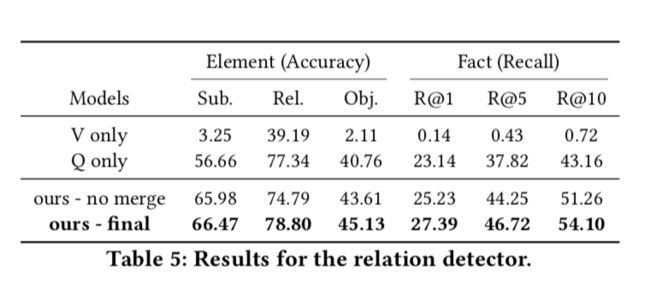
结果 表5显示了R-VQA测试集的实验结果。表5的第一部分报告了两个基线模型,它们完全支持图像和问题语义信息都有利于关联事实预测。一方面,没有问题内容的模型(仅表示为V)表明预测事实的准确性急剧下降。这种现象很直观,因为语义事实和问题都来自文本形态,而图像来自视觉形态。为了改善关联事实的语义空间,我们将事实预测表述为一个多目标分类问题,候选事实是三个要素的组合,即主语,关系和对象。因此,提供问题语义信息以减少候选事实的空间是很重要的。另一方面,没有图像内容的模型(仅表示为Q)遭受有限的预测性能,指示图像还包含一些有用的语义知识。
表5的第二部分说明了基于合并的R-VQA数据(表示为Ours-final)的模型比基于初始R-VQA数据的模型(表示为Ours-no merge)工作得更好。 尽管现有方法在视觉检测方面取得了良好进展,但对于视觉事实,在Visual Genome上实现Rec @ 100准确度为10-15%,这些方法不适合预测与问题相关的视觉事实。 与这些作品相比,我们的模型结合了事实预测的问题特征,并且通过较小的候选数量k实现了更高的准确度,以及更简单的框架。 在未来的工作中,设计细粒度模型以获得更好的预测性能仍然是有意义的。
5 基于事实的视觉问答
我们提出的VQA多步骤注意网络的总体框架如图4所示,它将语义问题和图像作为输入,并依次学习视觉和语义知识以推断出正确的答案。 我们提出的网络包括三个主要组成部分:(A)上下文感知视觉关注,(B)事实感知语义关注,和(C)联合知识嵌入学习。 设置上下文感知视觉注意力以选择与输入问题相关联的图像区域并获得这些区域的视觉语义表示。 事实感知语义注意力旨在通过学习的视觉语义表示来权衡检测到的相关关联事实,并学习语义知识。 最后,联合知识嵌入学习模型能够联合编码视觉和语义知识并推断出最可能的答案。
5.1 上下文感知视觉关注
与之前的许多VQA方法类似[8,36,41],我们采用问题感知的视觉注意机制来选择相关的图像区域。
图像编码 我们应用ResNet-152网络[10]来提取输入图像的图像特征嵌入。将来自最后卷积层的2048×14×14特征图作为图像视觉特征v,其对应于具有2048个特征通道的14×14图像区域。
问题编码 门复用单元(GRU)[7]用于编码问题嵌入,这在NLP和多模式任务中被广泛采用[17,22,41]。具体来说,给定一个含有T个单词的问题 Q = [ q 1 , . . . , q t , . . . , q T ] Q=[q_1,...,q_t,...,q_T] Q=[q1,...,qt,...,qT],其中qt是位置t的问题词的一个热矢量,我们首先将它们嵌入密集通过线性变换表示 x t = W e q t x_t = W_eq_t xt=Weqt。在每个时间t,我们顺序地将单词嵌入xt馈送到GRU层,并且GRU递归地用输入 x t x_t xt和先前隐藏状态 h t − 1 h_{t-1} ht−1更新当前隐藏状态 h t = G R U ( h t − 1 , x t ) ht = GRU(h_{t-1},x_t) ht=GRU(ht−1,xt)。最后,我们将最后隐藏状态 h T h_T hT作为问题表示。
视觉关注 采用视觉关注机制来突出与问题语义信息相关的图像区域,并在文本和视觉语义信息之间学习更有效的多模态特征。 首先,我们应用多模式低秩双线性池化(MLB)方法[14]将问题和图像的两种模态合并为
(15) c = M L B ( q , v ) , c=MLB(q,v),\tag{15} c=MLB(q,v),(15)
其中上下文向量c包含问题和图像语义内容。 我们通过线性变换层跟随softmax层将上下文向量映射到注意力权重,
(16) m = s o f t m a x ( W c c + b c ) , m=softmax(W_cc+b_c),\tag{16} m=softmax(Wcc+bc),(16)
其中权重m的大小为 14 × 14 14\times14 14×14,每个维度的值表示相应图像区域和输入问题之间的语义相关性。 上下文感知视觉特征被计算为所有图像区域上的表示的加权和,其由下式给出:
(17) v ~ = ∑ i = 1 14 × 14 m ( i ) v ( i ) , \tilde v=\sum_{i=1}^{14\times14}m(i)v(i),\tag{17} v~=i=1∑14×14m(i)v(i),(17)
我们进一步将上下文感知视觉特征与问题特征相结合,以获得最终的视觉表示
(18) f v = v ~ ∘ t a n h ( W q q + b q ) , f_v=\tilde{v} \ \circ\ tanh(W_qq+b_q),\tag{18} fv=v~ ∘ tanh(Wqq+bq),(18)
其中 ∘ \circ ∘表示逐元素乘法。
5.2 事实感知语义关注
视觉关注使得能够挖掘视觉上下文感知知识,例如对象和空间信息,这有利于主要关注对象检测的问题。然而,当需要更多关系推理时,仅具有视觉注意力的模型可能遭受有限的性能。因此,我们将关联事实列表作为语义线索,并提出语义关注模型来权衡不同的关联事实以获得更好的答案预测。一些现有的研究将语义概念或属性挖掘为语义知识以辅助VQA模型。我们提出的模型在两个方面与这些工作不同。一方面,现有方法仅挖掘概念或属性,而我们的模型提取包含概念和属性的关联事实,显然增加了所使用的语义知识的语义能力。另一方面,先前作品中的概念或属性可能与VQA无关,因为它们仅考虑图像内容并基于数据或预先训练的CNN模型来提取来自其他任务,如字幕和对象识别[41]。相比之下,我们建立了Relation-VQA数据集来训练关联事实检测器,直接关注输入图像和问题。
事实检测 首先,我们将先前在第4节中引入的事实检测器合并到我们的VQA模型中。给定输入图像和问题,事实检测器用于生成最可能的K关联事实作为候选集 T = [ t 1 ; t 2 ; . . . ; t K ] T = [t_1; t_2; ...; t_K] T=[t1;t2;...;tK]。对于事件 t i = ( s i , r i , o i ) t_i =(s_i,r_i,o_i) ti=(si,ri,oi),我们将事实的每个元素嵌入到一个公共语义空间Rn中,并将这三个嵌入连接为事实嵌入,如下所示:
(19) f t i = [ W s h s i , W r h r i , W o h o i ] ∈ R 3 n . f_{t_i}=[W_{sh}s_i,W_{rh}r_i,W_{oh}o_i]\in R^{3n}.\tag{19} fti=[Wshsi,Wrhri,Wohoi]∈R3n.(19)
然后我们可以得到K事实候选的表示,表示为 f T = [ f t 1 ; f t 2 ; . . . ; f t K ] ∈ R K × 3 n f_T = [f_{t_1}; f_{t_2}; ...; f_{t_K}]\in R^{K\times3n} fT=[ft1;ft2;...;ftK]∈RK×3n
语义关注 其次,我们开发语义注意力,在考虑输入图像和问题的情况下找出重要的事实。 具体地说,我们使用上下文感知的可视化表示作为查询来选择候选集中的重要事实。 类似于上下文感知视觉注意,给定上下文感知视觉嵌入 f v f_v fv和事实嵌入 f T f_T fT,我们首先获得联合上下文表示 c t c_t ct然后计算注意权重向量 m t m_t mt如下:
(20) c t = M L B ( f v , f T ) , c_t=MLB(f_v,f_T),\tag{20} ct=MLB(fv,fT),(20)
(21) m t = s o f t m a x ( W c t c t + b c t ) . m_t=softmax(W_{c_t}c_t+b_{c_t}).\tag{21} mt=softmax(Wctct+bct).(21)
候选人事实的最终出席事实陈述计算为
(22) f s = ∑ i = 1 K m t ( i ) f r ( i ) , f_s=\sum_{i=1}^K m_t(i)f_r(i),\tag{22} fs=i=1∑Kmt(i)fr(i),(22)
它用作回答视觉问题的语义知识信息。
5.3 联合知识嵌入学习
我们提出的多步骤注意模型由两个关注组件组成。 一个是视觉注意力,旨在选择相关的图像区域和输出上下文视觉知识表示 f v f_v fv。 另一个是语义关注,侧重于选择相关关联事实和输出事实-语义知识表示 f s f_s fs。 我们通过元素加法与线性变换和非线性激活函数合并这两种表示,共同学习视觉和语义知识,
(23) h = t a n h ( W v h f v + b v ) + t a n h ( W s h f s + b s ) . h=tanh(W_{vh}f_v +b_v)+tanh(W_{sh}f_s +b_s).\tag{23} h=tanh(Wvhfv+bv)+tanh(Wshfs+bs).(23)
当我们将VQA表示为多类分类任务时,训练线性分类器来推断最终答案,
(24) p a n s = s o f t m a x ( W a h + b a ) , p_{ans}=softmax(W_ah+b_a),\tag{24} pans=softmax(Wah+ba),(24)
6 实验
6.1 数据集和评估指标
由于大数据量和各种问题类型,我们在两个流行的基准数据集上评估我们提出的模型,即VQA数据集[1]和COCO-QA数据集[27]。
VQA数据集由Amazon Mechanical Turk(AMT)注释,包含248,349个训练实例,121,512个验证实例和244,302个基于123,287个独特自然图像的测试实例。数据集由三个问题类别组成,包括是/否,数字和其他。对于每个问题,不同的注释器提供十个答案。在之前的工作[14]之后,我们将最常见的2,000个答案作为候选答案输出,覆盖了培训和验证集中90.45%的答案。为了测试,我们在train + val 集上训练我们的模型,并在由[1]维护的VQA评估服务器上的test-dev集上报告测试结果。有两个不同的任务,一个开放式任务和一个多项任务。对于开放式任务,我们从候选答案集中选择最可能的答案,而对于多选任务,我们选择给定选项中具有最高激活分数的答案。
COCO-QA数据集是另一个基准数据集,包括78,736个培训问题和38,948个测试问题。有四种问题类型,对象,数字,颜色和位置,分别占问答总数的70%,7%,17%和6%。数据集中的所有答案都是单个单词。由于COCO-QA数据集较小,我们选择所有唯一答案作为可能的答案,这导致候选集的大小为430。
评估指标对于VQA数据集,我们按照数据集作者提供的评估指标报告结果,其中只有当三个以上的注释者为该答案投票时,预测的答案才被认为是正确的,也就是说,
(25) A c c ( a n s ) = m i n ( 1 , # h u m a n v o t e f o r a n s 3 ) . Acc(ans)=min(1,\frac{\#human\ vote\ for\ ans}{3}).\tag{25} Acc(ans)=min(1,3#human vote for ans).(25)
对于COCO-QA数据集,如果预测答案与数据集中的标记答案相同,则视为正确答案。
6.2 实现细节
对于编码问题,每个单词的嵌入大小设置为620。对于VQA模型中的编码事实,生成前十个事实,并且元素嵌入大小m的大小设置为900。所有其他视觉和文本表示为维度为2400的向量。
我们使用Torch计算框架实现我们的模型,这是最近最流行的深度学习库之一。 在我们的实验中,我们使用RMSProp方法进行训练, m i n i b a n c h minibanch minibanch为200,初始学习率为 3 × 1 0 − 4 3\times10^{-4} 3×10−4,动量为0.99,权重衰减为 1 0 − 8 10^{-8} 10−8。 每10000次迭代将会对模型进行一次评估,若连续的5次评估准确率没有提升那么训练会提早停止。
我们在每个线性变换层使用概率为0.5的下降策略来减少过度拟合。
6.3 与现有技术的比较
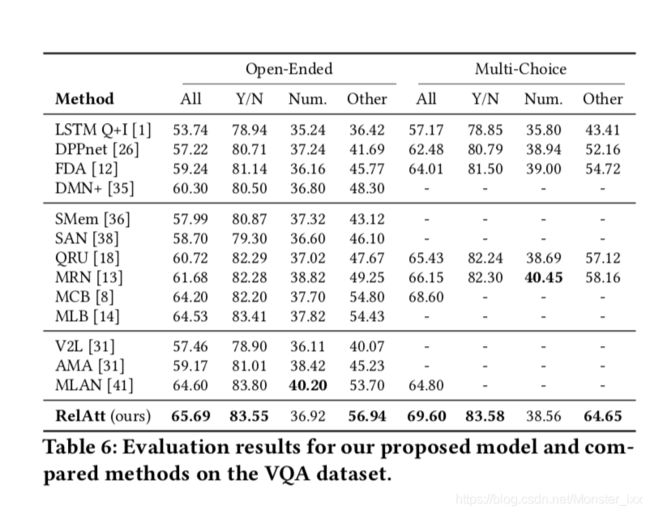
表6展示了我们提出的开放式和多选择任务模型,其中VQA测试集具有最新技术水平。请注意,所有列出的方法仅应用一种类型的可视要素和单个模型的报告结果。
表格的第一部分显示了使用简单的多模式联合学习而没有关注机制的模型。第二部分中的模型基于视觉注意,而第三部分中的模型应用语义关注来学习概念和属性等语义知识。结果表明,我们提出的多步骤语义关注网络(表示为RelAtt)将开放式任务中最先进的MLAN [41]模型从64.60%提高到65.69%,从64.80%提高到69.60%关于多项选择任务。具体而言,我们的模型在其他问题类型中获得2.51%的改进。作为最先进的模型,除了视觉注意外,MLAN还使用语义注意来挖掘基于图像内容的重要概念。相比之下,我们的模型RelAtt引入关联事实而不是概念作为语义知识,这显然增加了语义能力。此外,我们训练关系检测器以基于视觉和文本内容来学习事实,而不是仅使用图像[41]。由于我们提出的从Visual Genome数据集扩展的R-VQA数据集与VQA和COCO-QA等当前数据集共享相似的图像语义空间,因此从事实检测器获取的语义知识可以轻松转移到VQA任务。这些是RelAtt显着击败MLAN的主要原因。
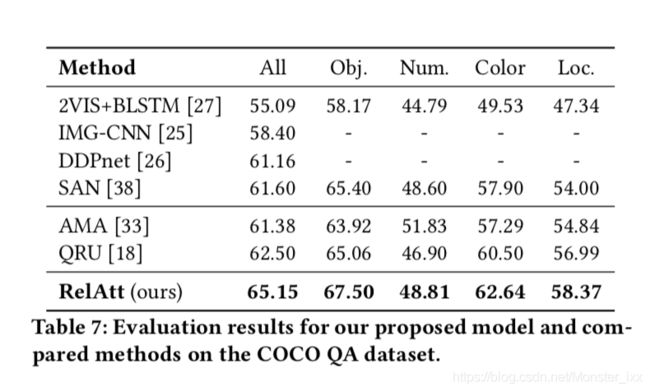
表7将我们的方法与COCO-QA数据集上的最新技术进行了比较。与VQA数据集不同,COCO-QA不包含多项选择任务,报告的结果较少。我们的模型将最先进的QRU [18]从62.50%提高到65.15%,增长率为2.65%。特别是,我们的模型明显优于最先进的语义关注模型AMA [33] 3.77%,表明了建立语义关联事实和从R-VQA数据集学习语义知识的有效性。
6.4 消融研究
在本节中,我们进行了五次消融实验,以研究在我们的模型中设计的各个组件的作用。 表8报告了比较基线模型的消融结果,这些模型在训练集上训练,并在验证集上进行评估。 具体来说,消融实验如下:
- Q + I,我们只用图像和问题来推断答案,图像问题联合表示是通过元素加法的简单融合方法学习的。
- Q + R,其中仅考虑检测器生成的问题和关联事实来预测答案。
- Q + I + Att,我们应用视觉注意来学习图像和问题的联合表示。
- RelAtt-Average,从我们最好的模型RelAtt中删除了方程20-22中所述的语义注意机制。 相反,事实表示是通过平均不同的事实嵌入来计算的。
- RelAtt-MUL,在方程式23中通过多次重复替换,以学习联合知识嵌入。
前三个消融模型的结果表明,视觉注意为问答提供了有限的视觉信息,而关联事实在包含语义信息时可以发挥重要作用。 RelAtt-Average的准确率下降0.79%表明语义注意对于编码关联事实至关重要。 此外,结果表明,在编码联合视觉文本知识表示时,元素加法的融合方法可能比乘法更好。

6.5 案例研究
为了说明我们的模型在学习关联事实作为语义知识的能力,我们在VQA测试集上展示了一些关于图像,问题和预测答案的例子。 我们还列出了事实检测器生成的关联事实及其在语义关注组件中的注意力。 为了节省空间,图5中只显示了五个关联事实中的五个。在图5(a)和(b)中,事实检测器挖掘了与图像和问题相关的语义事实候选,并且语义注意最有可能突出显示 回答问题的事实。 在图5(c)和(d)中,尽管给出相同的图像,但事实检测器可以依赖于不同的问题来生成相应的语义事实。
7 结论
在本文中,我们的目的是从图像和问题中学习视觉关联事实,用于视觉问答的语义推理。 我们通过首先基于构建的Relation-VQA(R-VQA)数据集学习关系因子检测器来提出新的框架。 然后开发了一个多步骤注意模型,将检测到的关联事实与顺序的视觉和语义注意相结合,实现视觉和语义知识的有效融合以便回答。 我们的综合实验表明,我们的方法优于最先进的方法,并证明了考虑视觉语义知识的有效性。
致谢
我们要感谢我们的匿名审稿人提供的建设性反馈和建议。 这项工作部分由国家自然科学基金资助,编号为61532010,编号为61702190,部分由国家基础研究计划(973计划)资助,编号为2014C B340505,部分由上海提供。 航运计划编号为17YF1404500,部分由上海晨光计划编号为16CG24,部分由微软公司提供。
引用
[1]Stanislaw Antol,Aishwarya Agrawal,Jiasen Lu,Margaret Mitchell,Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. 2015. Vqa: Visual question answering. In International Conference on Computer Vision (ICCV ’15). 2425–2433.
[2] SörenAuer,ChristianBizer,GeorgiKobilarov,JensLehmann,RichardCyganiak, and Zachary Ives. 2007. Dbpedia: A nucleus for a web of open data. In The semantic web. Springer, 722–735.
[3] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2014. Neural machine translation by jointly learning to align and translate. In International Conference on Learning Representations (ICLR ’14).
[4] Hedi Ben-Younes, Rémi Cadène, Nicolas Thome, and Matthieu Cord. 2017. MU- TAN: Multimodal Tucker Fusion for Visual Question Answering. In International Conference on Computer Vision (ICCV ’17).
[5] Kurt Bollacker, Colin Evans, Praveen Paritosh, Tim Sturge, and Jamie Taylor. 2008. Freebase: a collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD international conference on Management of data (SIGMOD ’08). ACM, 1247–1250.
[6] AntoineBordes,NicolasUsunier,AlbertoGarcia-Duran,JasonWeston,andOk- sana Yakhnenko. 2013. Translating embeddings for modeling multi-relational data. In Advances in neural information processing systems (NIPS ’13). 2787–2795.
[7] KyunghyunCho,BartvanMerriënboer,ÇaħlarGülçehre,DzmitryBahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. 2014. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Empirical Methods in Natural Language Processing (EMNLP ’14). 1724–1734.
[8] Akira Fukui, Dong Huk Park, Daylen Yang, Anna Rohrbach, Trevor Darrell, and Marcus Rohrbach. 2016. Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding. In Empirical Methods in Natural Language Processing (EMNLP ’16). 457–468.
[9] PengGao,HongshengLi,ShuangLi,LuPan,LiYikang,StevenHoi,andXiao- gang Wang. 2018. Question-Guided Hybrid Convolution for Visual Question Answering. In European Conference on Computer Vision (ECCV ’18).
[10] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR ’16). 770–778.
[11] SeppHochreiterandJürgenSchmidhuber.1997.Longshort-termmemory.Neural Computation 9, 8 (1997), 1735–1780.
[12] Ilija Ilievski, Shuicheng Yan, and Jiashi Feng. 2016. A focused dynamic attention model for visual question answering. arXiv preprint arXiv:1604.01485 (2016).
[13] Jin-Hwa Kim, Sang-Woo Lee, Donghyun Kwak, Min-Oh Heo, Jeonghee Kim, Jung-Woo Ha, and Byoung-Tak Zhang. 2016. Multimodal residual learning for visual qa. In Advances In Neural Information Processing Systems (NIPS ’16).
[14] Jin-Hwa Kim, Kyoung Woon On, Woosang Lim, Jeonghee Kim, Jung-Woo Ha, and Byoung-Tak Zhang. 2017. Hadamard product for low-rank bilinear pooling. In International Conference on Learning Representations (ICLR ’17).
[15] Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A Shamma, et al. 2017. Visual genome: Connecting language and vision using crowdsourced dense image annotations. International Journal of Computer Vision 123 (2017), 32–73.
[16] Guohao Li, Hang Su, and Wenwu Zhu. 2017. Incorporating External Knowledge to Answer Open-Domain Visual Questions with Dynamic Memory Networks. arXiv preprint arXiv:1712.00733 (2017).
[17] Huayu Li, Martin Renqiang Min, Yong Ge, and Asim Kadav. 2017. A Context-aware Attention Network for Interactive Question Answering. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (SIGKDD ’17). ACM, 927–935.
[18] Ruiyu Li and Jiaya Jia. 2016. Visual question answering with question represen- tation update (qru). In Advances In Neural Information Processing Systems (NIPS ’16).
[19] Yikang Li, Wanli Ouyang, Xiaogang Wang, et al. 2017. Vip-cnn: Visual phrase guided convolutional neural network. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR ’17). 7244–7253.
[20] Xiaodan Liang, Lisa Lee, and Eric P Xing. 2017. Deep variation-structured reinforcement learning for visual relationship and attribute detection. In IEEEConference on Computer Vision and Pattern Recognitio (CVPR ’17). IEEE, 4408–4417.
[21] Guang-Hai Liu, Jing-Yu Yang, and ZuoYong Li. 2015. Content-based image
retrieval using computational visual attention model. Pattern Recognition 48, 8 (2015), 2554–2566.
[22] Yunfei Long, Lu Qin, Rong Xiang, Minglei Li, and Chu-Ren Huang. 2017. A Cognition Based Attention Model for Sentiment Analysis. In Conference on Empirical Methods in Natural Language Processing (EMNLP ’17). 462–471.
[23] Cewu Lu, Ranjay Krishna, Michael Bernstein, and Li Fei-Fei. 2016. Visual Rela- tionship Detection with Language Priors. In European Conference on Computer Vision (ECCV ’16).
[24] Pan Lu, Hongsheng Li, Wei Zhang, Jianyong Wang, and Xiaogang Wang. 2018.Co-attending Free-form Regions and Detections with Multi-modal Multiplicative Feature Embedding for Visual Question Answering… In The AAAI Conference on Artificial Intelligence (AAAI’18). 7218–7225.
[25] Lin Ma, Zhengdong Lu, and Hang Li. 2016. Learning to Answer Questions from Image Using Convolutional Neural Network… In The AAAI Conference on Artificial Intelligence (AAAI ’16).
[26] Hyeonwoo Noh, Paul Hongsuck Seo, and Bohyung Han. 2016. Image question an- swering using convolutional neural network with dynamic parameter prediction. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR ’16).
[27] Mengye Ren, Ryan Kiros, and Richard Zemel. 2015. Exploring models and data for image question answering. In Advances In Neural Information Processing Systems (NIPS ’16).
[28] Karen Simonyan and Andrew Zisserman. 2014. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014).
[29] Richard Socher, Danqi Chen, Christopher D Manning, and Andrew Ng. 2013. Rea- soning with neural tensor networks for knowledge base completion. In Advances in neural information processing systems (NIPS ’13). 926–934.
[30] Xuejian Wang, Lantao Yu, Kan Ren, Guanyu Tao, Weinan Zhang, Yong Yu, and Jun Wang. 2017. Dynamic attention deep model for article recommendation by learning human editors’ demonstration. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (SIGKDD ’17). ACM, 2051–2059.
[31] Qi Wu, Chunhua Shen, Lingqiao Liu, Anthony Dick, and Anton van den Hengel. 2016. What value do explicit high level concepts have in vision to language problems?. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR ’16). 203–212.
[32] QiWu,ChunhuaShen,PengWang,AnthonyDick,andAntonvandenHengel. 2017. Image Captioning and Visual Question Answering Based on Attributes and External Knowledge. IEEE Transactions on Pattern Analysis and Machine Intelligence (2017).
[33] Qi Wu, Peng Wang, Chunhua Shen, Anthony Dick, and Anton van den Hengel.
2016. Ask me anything: Free-form visual question answering based on knowl- edge from external sources. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR ’16). 4622–4630.
[34] Tianjun Xiao, Yichong Xu, Kuiyuan Yang, Jiaxing Zhang, Yuxin Peng, and Zheng Zhang. 2015. The application of two-level attention models in deep convolu- tional neural network for fine-grained image classification. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR ’15). 842–850.
[35] Caiming Xiong, Stephen Merity, and Richard Socher. 2016. Dynamic memory networks for visual and textual question answering. In International Conference on Machine Learning (ICML ’16).
[36] Huijuan Xu and Kate Saenko. 2016. Ask, attend and answer: Exploring question- guided spatial attention for visual question answering. In European Conference on Computer Vision (ECCV ’16). 451–466.
[37] Zhao Yan, Nan Duan, Junwei Bao, Peng Chen, Ming Zhou, Zhoujun Li, and Jianshe Zhou. 2016. Docchat: An information retrieval approach for chatbot engines using unstructured documents. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (ACL ’16), Vol. 1. 516–525.
[38] Zichao Yang, Xiaodong He, Jianfeng Gao, Li Deng, and Alex Smola. 2016. Stacked attention networks for image question answering. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR ’16). 21–29.
[39] Zichao Yang, Diyi Yang, Chris Dyer, Xiaodong He, Alexander J Smola, and Ed- uard H Hovy. 2016. Hierarchical Attention Networks for Document Classification. In The 16th Annual Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (HLT-NAACL ’16). 1480–1489.
[40] Quanzeng You, Hailin Jin, Zhaowen Wang, Chen Fang, and Jiebo Luo. 2016. Image captioning with semantic attention. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR ’16). 4651–4659.
[41] Dongfei Yu, Jianlong Fu, Tao Mei, and Yong Rui. 2017. Multi-level attention networks for visual question answering. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR ’17). 4709–4717.
[42] Shuangfei Zhai, Keng-hao Chang, Ruofei Zhang, and Zhongfei Mark Zhang. 2016. Deepintent: Learning attentions for online advertising with recurrent neural networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (SIGKDD ’16). ACM, 1295–1304.
[43] Wei Zhang, Wen Wang, Jun Wang, and Hongyuan Zha. 2018. User-guided Hier- archical Attention Network for Multi-modal Social Image Popularity Prediction. In Proceedings of the 2018 World Wide Web Conference (WWW ’18). 1277–1286.