GPU编程自学8 —— 纹理内存
深度学习的兴起,使得多线程以及GPU编程逐渐成为算法工程师无法规避的问题。这里主要记录自己的GPU自学历程。
目录
- 《GPU编程自学1 —— 引言》
- 《GPU编程自学2 —— CUDA环境配置》
- 《GPU编程自学3 —— CUDA程序初探》
- 《GPU编程自学4 —— CUDA核函数运行参数》
- 《GPU编程自学5 —— 线程协作》
- 《GPU编程自学6 —— 函数与变量类型限定符》
- 《GPU编程自学7 —— 常量内存与事件》
- 《GPU编程自学8 —— 纹理内存》
- 《GPU编程自学9 —— 原子操作》
- 《GPU编程自学10 —— 流并行》
八、 纹理内存
同常量内存一样,纹理内存(Texture Memory)也是一种只读内存。 之所以称之为 “纹理”,是因为最初是为图形应用设计的。 当程序中存在大量局部空间操作时,纹理内存可以提高性能。
8.1 为什么纹理内存可以加速
纹理内存可以加速应用主要原因有两方面:
1. 纹理内存也是缓存在片上的,因此一些情况下相比从芯片外的DRAM上获取数据,纹理内存可以通过减少内存请求来提高带宽。
2. 纹理内存是针对图形应用设计的,可以更高效地处理局部空间的内存访问。
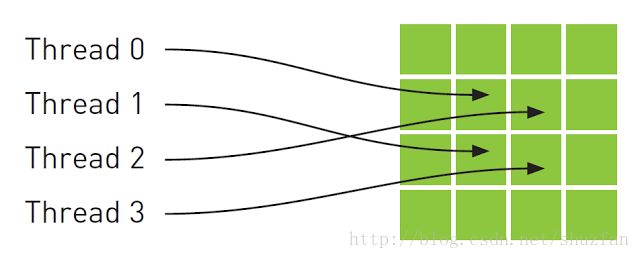
从数学的角度,上图中的4个地址并非连续的,在一般的CPU缓存中,这些地址将不会缓存。但由于GPU纹理缓存是专门为了加速这种访问模式而设计的,因此如果在这种情况中使用纹理内存而不是全局内存,那么将会获得性能的提升。
8.2 纹理内存的数据限制
下图是常见内存的存储位置,以及读取模式:

由上图可以看出,纹理内存是只读的,而且可以同时被主机和设备读取。
此外,纹理内存可以被声明为1D、2D或者3D数组,但数组的大小有限制,具体可以点击链接查看《不同计算能力GPU的指标》。
同时纹理内存中存储的数据也必须声明为固定类型,即各种对齐类型中的一种,如(char、short、int、long、float、double等)。
8.3 纹理内存使用
纹理内存的使用依赖于API函数。下面直接给出常见的使用流程:
8.3.1 声明纹理变量
texture VarName;
//Type: 前面提到的基本的整型和浮点类型,以及其它的对齐类型
//Dim: 纹理数组的维度,值为1或2或3,默认缺省为1
//ReadMode:cudaReadModelNormalizedFloat 或 cudaReadModelElementType(默认) - cudaReadModelNormalizedFloat:如果Type为整型(8bit或者16bit),则读取数据时会自动将整型数据转化为浮点数。具体地,如果是无符号整型,则转化为[0 1]之间的浮点数;如果是有符号整型,则转化为[-1 1]之间的浮点数。
- cudaReadModelElementType:默认值,不进行任何转换
8.3.2 开辟内存
分配内存,内存形式有两种 线性内存 和 CUDA数组。
- 线性内存通过cudaMalloc()、cudaMallocPitch()或者cudaMalloc3D()分配;
- CUDA数组可以通过cudaMalloc3DArray()或者cudaMallocArray()分配。前者可以分配1D、2D、3D的数组,后者一般用于分配2D的CUDA数组。
比如开辟一个二维CUDA数组ArrayName(64 x 64):
cudaChannelFormatDesc channelDesc = cudaCreateChannelDesc<float>();
cudaArray *ArrayName;
cudaMallocArray(&ArrayName, &channelDesc, 64, 64); 8.3.3 绑定纹理内存
纹理绑定(texture binding)的作用有两个:
- 将指定的缓冲区作为纹理来使用;
- 纹理引用作为纹理的“名字”
通常使用cudaBindTexture() 或 cudaBindTexture2D() 分别将线性内存绑定到1D和2D纹理内存,使用cudaBindTextureToArray()将CUDA数组与纹理绑定。
注意: 线性内存只能与一维或二维纹理绑定;CUDA数组则可以与一维、二维、三维纹理绑定。切两种绑定有着一些不同的特性。
| 与纹理绑定的内存结构 | 拾取坐标 | 滤波模式 | 归一化坐标 | 类型转换 | 多维纹理 | 寻址模式 |
|---|---|---|---|---|---|---|
| 线性内存 | 整型 | 不支持浮点型像元 | 不支持 | 支持 | 不支持 | 不支持 |
| CUDA数组 | 浮点型 | 支持 | 支持 | 支持 | 支持 | 支持 |
以cudaBindTexture()为例(有两种级别的调用)
high-level API
cudaBindtexture (size *t offset, const struct texture & tex , const void * devptr, size_t size= UINT_MAX)
// offset: 字节偏移量
// tex: 待绑定的纹理
// devPtr: 设备上已开辟的内存地址
// size : 开辟的内存大小 调用例子如下:
texture<Type, Dim, ReadMode> tex;
cudaMalloc((void**)&devPtr, size);
cudaBindTexture(NULL, tex, devPtr, size);low-level API
此种情况稍微复杂一点, 是将开辟的缓存与“纹理参考系”绑定。
纹理参照系(texture reference)约定从数据的地址到纹理坐标的映射方式,其定义如下:
struct textureReference {
int normalized;
enum cudaTextureFilterMode filterMode;
enum cudaTextureAddressMode addressMode[3];
struct cudaChannelFormatDesc channelDesc;
...
}可能用到的主要有下面3个参数:
- normalized设置是否对纹理坐标归一化(纹理内存支持浮点坐标索引,[0 ~ N]的坐标索引会被归一化到 [0 1-1/N])
- filterMode用于设置纹理的滤波模式(纹理缓存一次预取拾取坐标对应位置附近的几个象元,可以实现滤波模式)
- addressMode说明了寻址方式
此时纹理内存被声明为引用形式:
texture texRef; 完整的使用示例如下:
texture<float, cudaTextureType1D, cudaReadModeElementType> texRef; textureReference* texRefPtr;
cudaGetTextureReference(&texRefPtr, &texRef);
cudaChannelFormatDesc channelDesc = cudaCreateChannelDesc<float>();
size_t offset;
cudaBindTexture2D(&offset, texRefPtr, devPtr, &channelDesc, width, height, pitch);8.3.4 拾取纹理内存
在kernel中访问纹理内存称为纹理拾取(texture fetching)。 访问纹理内存必须使用API函数,而不能使用方括号索引的形式。因为我们需要API函数将读取请求转发到纹理内存而不是全局内存。
对于线性存储器绑定的纹理,使用tex1Dfetch()访问,采用的纹理坐标是整型。 对与一维、二维、三维cuda数组绑定的纹理,分别使用tex1D(), tex2D() 和 tex3D()函数访问,并且使用浮点型纹理坐标。
此外,tex1Dfetch()是一个编译器内置函数,因此纹理引用必须声明为文件域内的全局变量,因为编译器在编译阶段需要知道tex1Dfetch()对哪些纹理采样。
8.3.5 解绑纹理内存
最后当程序结束时,我们需要释放之前开辟的内存并解除纹理内存的绑定。
示例代码如下:
cudaUnbindTexture (tex);
cudaFree(devPtr);8.4 使用纹理内存实现均值滤波
下面给出一个我实现的简单的3x3均值滤波,即滤波后的一个像素值是其周围3x3范围内9个像素值的平均值。 均值滤波可以有效去除高斯噪声。
#include "cuda_runtime.h"
#include "opencv.hpp"
#include "highgui.hpp"
// 声明2D纹理内存引用
texture<uchar, 2, cudaReadModeElementType> texRef;
// 核函数, 用于均值滤波
__global__ void meanfilter_kernel(uchar* dstcuda, int width)
{
unsigned int x = blockIdx.x * blockDim.x + threadIdx.x;
unsigned int y = blockIdx.y * blockDim.y + threadIdx.y;
// 3x3范围内求和, 然后计算均值
// 注意tex2D会自动对索引越界进行处理,因此不用判断x-1是否小于0
dstcuda[y * width + x] = (tex2D(texRef, x - 1, y - 1) + tex2D(texRef, x, y - 1) + tex2D(texRef, x + 1, y - 1) +
tex2D(texRef, x - 1, y) + tex2D(texRef, x, y) + tex2D(texRef, x + 1, y) +
tex2D(texRef, x - 1, y + 1) + tex2D(texRef, x, y + 1) + tex2D(texRef, x + 1, y + 1)) / 9;
}
int main()
{
// 读取待滤波图片(1024x640含高斯噪声灰度图)
cv::Mat srcImg = cv::imread("gray_scarleet_noisy.jpg",cv::IMREAD_GRAYSCALE);
// 开辟系统内存
cudaChannelFormatDesc channelDesc = cudaCreateChannelDesc(8,0,0,0,cudaChannelFormatKindUnsigned);
cudaArray* srcArray;
cudaMallocArray(&srcArray, &channelDesc, srcImg.cols, srcImg.rows);
// 将图像copy进内存
cudaMemcpyToArray(srcArray, 0, 0, srcImg.data, srcImg.cols * srcImg.rows, cudaMemcpyHostToDevice);
// 将内存与纹理引用绑定
cudaBindTextureToArray(&texRef,srcArray,&channelDesc);
// 声明用于储存滤波后的图像
cv::Mat dstImg = cv::Mat(cv::Size(srcImg.cols, srcImg.rows), CV_8UC1);
uchar * dstcuda;
cudaMalloc((void**)&dstcuda, srcImg.cols * srcImg.rows * sizeof(uchar));
// 运行核函数
dim3 dimBlock(32, 32);
dim3 dimGrid((srcImg.cols + dimBlock.x - 1) / dimBlock.x, (srcImg.rows + dimBlock.y - 1) / dimBlock.y);
meanfilter_kernel << > > (dstcuda, srcImg.cols);
// 线程同步
cudaThreadSynchronize();
// 将数据copy回主机
cudaMemcpy(dstImg.data, dstcuda, srcImg.cols * srcImg.rows * sizeof(uchar), cudaMemcpyDeviceToHost);
// 解除绑定并释放内存
cudaUnbindTexture(&texRef);
cudaFreeArray(srcArray);
cudaFree(dstcuda);
// 显示效果图
cv::imshow("Source Image", srcImg);
cv::imshow("Result Image", dstImg);
cvWaitKey();
return 0;
} 效果如下:
高斯噪声图

滤波后

参考资料
- 《CUDA by Example: An Introduction to General-Purpose GPU Programming》 中文名《GPU高性能编程CUDA实战》
- “CUDA Toolkit Documentation B.C ”http://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#c-language-extensions
- CUDA中的纹理内存: http://cuda-programming.blogspot.jp/2013/02/texture-memory-in-cuda-what-is-texture.html
- CUDA线性内存分配: http://blog.csdn.net/u012361418/article/details/45419463
- CUDA纹理内存(内存绑定): http://www.cnblogs.com/traceorigin/archive/2013/04/11/3015755.html