CUDA By Example(三)——CUDA C并行编程
前面的章节可以看到把一个标准C函数放到GPU设备上运行是很容易的。只需在函数定义前面加上
__global__修饰符,并通过一种特殊的尖括号语法来调用它,就可以在GPU上执行这个函数。但之间的案例是串行执行,是很低效的,下面学习如何启动一个并行执行的设备核函数。
文章目录
- 矢量求和运算
-
- 基于CPU的矢量求和
- 基于GPU的矢量求和
- 绘制Julia集的曲线
-
- 基于CPU的Julia集
- 基于GPU的Julia集
- 遇到的问题与解决方案
-
- 构造函数未加 `__device__` 修饰符
- 找不到glut64.lib和glut64.dll
矢量求和运算
下面通过一个简单的示例来说明线程的概念,以及如何使用CUDA C来实现线程。假设有两组数据,我们需要将这两组数据中对应的元素两两相加,并将结果保存在第三个数组中。下图给出了这个计算过程,其实这就是一个矢量求和运算。

基于CPU的矢量求和
首先,使用传统的C代码来实现这个求和运算:
#include 运行结果
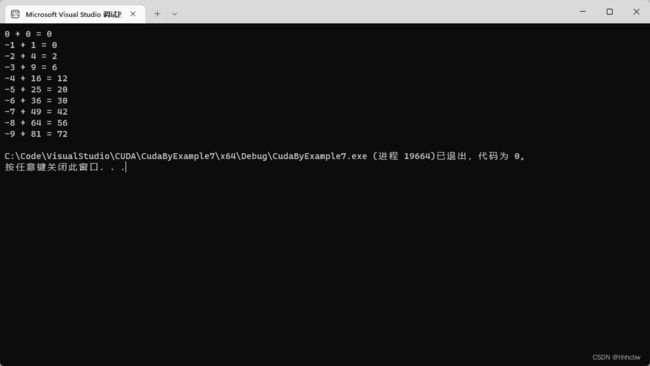
上面的 while 循环虽然有些复杂,但这是为了使代码能够在拥有多个CPU或者CPU核的系统上并行运行。例如,在双核处理器上可以将每次递增的大小改为2,这样其中一个核从 tid=0 开始执行循环,而另一个核从 tid=1 开始执行循环。第一个核将偶数索引的元素相加,而第二个核则将奇数索引的元素相加。这相当于在每个CPU核上执行以下代码:

当然在CPU上进行并行运算,还需要增加更多的代码。例如,需要编写一定数量的代码来创建工作线程,每个线程都执行函数 add(),并假设每个线程都将并行执行。
基于GPU的矢量求和
下面代码为基于GPU的矢量求和代码
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "../common/book.h"
#include 运行结果如下
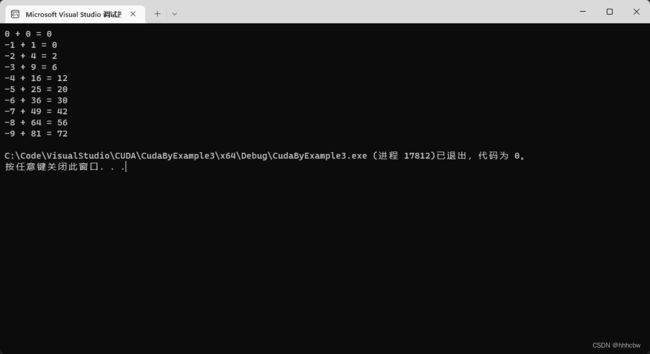
上面的代码依旧使用了一些通用模式:
- 调用
cudaMalloc()在设备上为三个数组分配内存:在其中两个数组(dev_a和dev_b)中包含了输入值,而在数组dev_c中包含了计算结果。 - 为了避免内存泄漏,在使用完GPU内存后通过
cudaFree()释放它们。 - 通过
cudaMemcpy()将输入数据复制到设备中,同时指定参数cudaMemcpyHostToDevice,在计算完成后,将计算结果通过参数cudaMemcpyDeviceToHost复制回主机。 - 通过尖括号语法,在主机代码
main()中执行add()中的设备代码。
接下来是 add() 函数,这个函数看上去非常类似于基于CPU实现的 add()
__global__ void add(const int *a, const int *b, int *c)
{
int tid = blockIdx.x; // 计算位于这个索引处的数据
if (tid < N)
c[tid] = a[tid] + b[tid];
}
这里在函数 add() 中也使用了一种通用模式:
- 编写的一个在设备上执行的函数
add()。我们采用C来编写代码,并在函数名字前添加了一个修饰符__global__。
到目前位置,除了执行的计算不是将 2 和 7 相加外,在这个示例中没有包含任何新的东西。然后,这个示例中有两个值得注意的地方:尖括号中的参数以及核函数中包含的代码,这两处地方都引入了新的概念。
这个示例中,尖括号的数值并不是1:
add<<<N,1>>>(dev_a, dev_b, dev_c);
这里尖括号中的两个参数,第一个参数表示设备在执行核函数时使用的并行线程块的数量。在这个示例中,指定这个参数为N。
例如,如果指定的是 kernel<<<2,1>>>(),那么可以认为运行时将创建核函数的两个副本,并以并行方式来运行它们。我们将每个并行执行环境都称为一个线程块(Block)。如果指定的是 kernel<<<256,1>>>(),那么将有256个线程块在GPU上运行。
但这种运行方式引出了一个问题:既然GPU将运行核函数的N个副本,那如何在代码中知道当前正在运行的是哪一个线程块?这个问题的答案在于示例中核函数的代码本身。具体来说,是在于变量 blockIdx.x
这里不需要定义变量 blockIdx,它是一个内置变量,在CUDA运行时中已经预先定义了这个变量。而且,这个变量名字的含义也就是变量的作用。变量中包含的值就是当前执行设备代码的线程块的索引。
这里是 blockIdx.x 的原因在于CUDA支持二维的线程块数组。对于二维空间的计算问题,例如矩阵数学运算或者图像处理,使用二维索引往往会带来很大的便利,因为它可以避免将线性索引转换为矩形索引。
当启动核函数时,我们将并行线程块的数量指定为N。这个并行线程块集合也称为一个线程格(Grid)。这是告诉运行时,我们想要一个一维的线程格,其中包含N个线程块。每个线程块的 blockIdx.x 值都是不同的,第一个线程块的 blockIdx.x 为0,而最后一个线程块的 blockIdx.x 为 N-1。因此,假设有4个线程块,并且所有线程块都运行相同的设备代码,但每个线程块的 blockIdx.x 的值是不同的。当四个线程块并行执行时,运行时将用相应的线程块索引来替换 blockIdx.x,每个线程块实际执行的代码如下所示:

如果我们想编写更大规模的并行应用程序,只需将 #define N 10 中的10改为10000或者50000,这样可以启动数万个并行线程块。但是需要注意的是:在启动线程块数组时,数组每一维的最大数量都不能超过65535,这是一种硬件限制,如果启动的线程块数量超过了这个限值,那么程序将运行失败。
绘制Julia集的曲线
下面通过绘制Julia集的曲线,进一步学习CUDA C的并行编程。
Julia集可以简单认为是满足某个复数计算函数的所有点构成的边界。对于函数参数的所有取值,生成的边界将形成一种不规则的碎片形状,这是数学中最有趣和最漂亮的形状之一。
生成Julia集的算法非常简单,其基本算法如下:
通过一个简单的迭代等式对复平面中的点求值。如果在计算某个点时,迭代等式的计算结果是发散的,那么这个点就不属于Julia集合。也就是说,如果在迭代等式中计算得到的一系列值朝着无穷大的方向增长,那么这个点就被认为不属于Julia集合。相反,如果在迭代等式中计算得到的一系列值都位于某个边界范围之内,那么这个点就属于Julia集合。
迭代等式为 Z n + 1 = Z n 2 + C Z_{n+1}=Z_{n}^{2}+C Zn+1=Zn2+C,首先计算当前值的平方,然后再加上一个常数以得到等式的下一个值。
下面依旧分为基于CPU的实现和基于GPU的实现
基于CPU的Julia集
首先其 main() 函数如下:
int main()
{
CPUBitmap bitmap(DIM, DIM);
unsigned char* ptr = bitmap.get_ptr();
kernel(ptr);
bitmap.display_and_exit();
return 0;
}
main 函数非常简单。它通过工具库创建了一个大小合适的位图图像。接下来,它将一个指向位图数据的指针传递给了核函数。
void kernel(unsigned char* ptr) {
for (int y = 0; y < DIM; y++) {
for (int x = 0; x < DIM; x++) {
int offset = x + y * DIM;
int juliaValue = julia(x, y);
ptr[offset * 4 + 0] = 255 * juliaValue;
ptr[offset * 4 + 1] = 0;
ptr[offset * 4 + 2] = 0;
ptr[offset * 4 + 3] = 255;
}
}
}
核函数对将要绘制的所有点进行迭代,并在每次迭代时调用 julia() 来判断该点是否属于 Julia 集。如果该点位于集合中,那么函数 julia() 将返回 1,否则将返回 0。如果 julia() 返回 1,那么将该点的颜色设置为红色,如果返回 0 则设置为黑色。这些颜色是任意的,你可以根据自己的喜好来选择合适的颜色。
int julia(int x, int y) {
const float scale = 1.5;
float jx = scale * (float)(DIM / 2 - x) / (DIM / 2);
float jy = scale * (float)(DIM / 2 - y) / (DIM / 2);
cuComplex c(-0.8, 0.156);
cuComplex a(jx, jy);
int i = 0;
for (i = 0; i < 200; i++) {
a = a * a + c;
if (a.magnitude2() > 1000)
return 0;
}
return 1;
}
julia() 函数首先将像素坐标转换为复数空间的坐标。为了将复平面的原点定位到图像中心,我们将像素位置移动了 DIM/2。然后,为了确保图像的范围为 [-1.0,1.0],我们将图像的坐标缩放了 DIM/2 倍。这样,给定一个图像点 (x,y),就可以计算并得到复空间中的一个点 ((DIM/2-x)/(DIM/2), (DIM/2-y)/(DIM/2))。
然后,我们引入了一个 scale 因数来实现图形的缩放。当前,这个 scale 被硬编码为 1.5,当然你也可以调整这个参数来缩小或者放大图形。更完善的做法是将其作为一个命令行参数。
在计算出复空间中的点之后,需要判断这个点是否属于 Julia 集。在前面提到过,这是通过计算迭代等式 Z n + 1 = Z n 2 + C Z_{n+1}=Z_{n}^{2}+C Zn+1=Zn2+C来判断的。 C C C 是一个任意的复数常量,这里选择的值是 -0.8 + 0.156i,因为这个值刚好能生成一张有趣的图片。如果想看看其他的 Julia 集,可以修改这个常量。
在这个示例中,我们计算了 200 次迭代。在每次迭代计算完成后,都会判断结果是否超过某个阈值(在这里是1000)。如果超过了这个阈值,那么等式就是发散的,因此将返回 0 以表示这个点不属于 Julia 集合。反之,如果所有的 200 次迭代都计算完毕后,并且结果仍然是小于 1000,那么我们就认为这个点属于该集合,并且给调用者 kernel() 返回 1。
由于所有计算都是在复数上进行的,因此我们定义了一个通用结构来保存复数值。
struct cuComplex {
float r;
float i;
cuComplex(float a, float b) : r(a), i(b) {}
float magnitude2(void) { return r * r + i * i; }
cuComplex operator*(const cuComplex& a) {
return cuComplex(r * a.r - i * a.i, i * a.r + r * a.i);
}
cuComplex operator+(const cuComplex& a) {
return cuComplex(r + a.r, i + a.i);
}
};
这个类表示一个复数值,包含两个成员:单精度的实部 r 和单精度的虚部 i。在这个类中定义了复数的加法运算符和乘法运算符。最后,还定义了一个方法来返回复数的模。
完整代码如下
#include 结果如下

基于GPU的Julia集
在 GPU 设备上计算 Julia 集的代码与CPU版本的代码非常类似。
int main()
{
CPUBitmap bitmap(DIM, DIM);
unsigned char* dev_bitmap;
HANDLE_ERROR(cudaMalloc((void**)&dev_bitmap, bitmap.image_size()));
dim3 grid(DIM, DIM);
kernel << <grid, 1 >> > (dev_bitmap);
HANDLE_ERROR(cudaMemcpy(bitmap.get_ptr(), dev_bitmap, bitmap.image_size(), cudaMemcpyDeviceToHost));
bitmap.display_and_exit();
HANDLE_ERROR(cudaFree(dev_bitmap));
return 0;
}
基于GPU版本的 main() 看上去比基于CPU的版本要更复杂,但实际上程序的执行流程是相同的。与 CPU 版本一样,首先通过工具库创建一个 DIM x DIM 大小的位图图像。然后,由于接下来将在 GPU 上执行计算,因此在代码中声明了一个指针 dev_bitmap,用来保存设备上数据的副本。同样,为了保存数据,我们需要通过 cudaMalloc() 来分配内存。
然后,我们像在CPU版本中那样来运行 Kernel() 函数,但是它现在是一个 __global__ 函数,这意味着将在GPU上运行。与CPU示例一样,在前面代码中分配的指针会传递给 kernel() 来保存计算结果。唯一的差异在于这线程块内存驻留在GPU上,而不是在主机上。
由于每个点的计算与其他点的计算都是相互独立的,因此可以为每个需要计算的点都执行该函数的一个副本。这里使用二维的线程格有利于我们进行计算。
dim3 grid(DIM, DIM);
类型 dim3 并不是标准 C 定义的类型。在 CUDA 头文件中定义了一些辅助类型来封装多维数组。类型 dim3 表示一个三维数组,可以用于指定启动的线程块的数量。然而,为什么要使用三维数组,而我们实际需要的只是一个二维线程格?
这么做是因为CUDA运行时希望得到一个三维的 dim3 值。虽然当前并不支持三维的线程格,但CUDA运行时仍然希望得到一个 dim3 类型的参数,只不过最后一维的大小为 1。当仅用两个值来初始化 dim3 类型的变量时,例如在语句 dim3 grid(DIM, DIM) 中,CUDA运行时将自动把第3维的大小指定为 1.
然后,在下面这行代码中将 dim3 变量 grid 传递给 CUDA 运行时:
kernel<<<grid,1>>>(dev_bitmap);
最后,在执行完 kernel() 之后,在设备上会生成计算结果,我们需要将这些结果复制回主机。和前面一样,通过 cudaMemcpy() 来实现这个操作,并将复制方向指定为 cudaMemcpyDeviceToHost。
HANDLE_ERROR(cudaMemcpy(bitmap.get_ptr(), dev_bitmap, bitmap.image_size(), cudaMemcpyDeviceToHost));
在基于CPU的版本与基于GPU的版本之间,关键差异之一在于 kernel() 的实现。
__global__ void kernel(unsigned char* ptr) {
// 将threadIdx/BlockIdx映射到像素位置
int x = blockIdx.x;
int y = blockIdx.y;
int offset = x + y * gridDim.x;
// 现在计算这个位置上的值
int juliaValue = julia(x, y);
ptr[offset * 4 + 0] = 255 * juliaValue;
ptr[offset * 4 + 1] = 0;
ptr[offset * 4 + 2] = 0;
ptr[offset * 4 + 3] = 255;
}
首先,需要将 kernel() 声明为一个 __global__ 函数,从而可以从主机上调用并在设备上运行。与CPU版本不同的是,我们不需要通过嵌套的 for() 循环来生产像素索引以传递给 julia()。与矢量相加示例一样,CUDA运行时将在变量 blockIdx 中包含这些索引。这种方式是可行的,因为在声明线程格时,线程格每一维的大小与图像每一维的大小与图像每一维的大小是相等的,因此在 (0,0) 和 (DIM-1,DIM-1) 之间的每个像素点 (x,y) 都能获得一个线程块。
然后通过内置变量 gridDim 来计算输出缓冲区 ptr 中的线性偏移。对所有的线程块来说,gridDim 是一个常数,用来保存线程格每一维的大小。在示例中,gridDim 的值是 (DIM, DIM)。因此,将行索引乘以线程格的宽度,再加上列索引,就得到了 ptr 中的唯一索引,其取值范围为 [0, DIM*DIM-1]。
int offset = x + y * gridDim.x;
判断某个点是否属于 Julia 集的代码,与 CPU 版本基本相同。除了函数起始有 __device__ 标识符,这表示代码将在GPU而不是主机上运行。由于这些函数已声明为 __device__ 函数,因此只能从其他 __device__ 函数或者从 __global__ 函数中调用它们。
同样对于 cuComplex 结构体,对于其中的方法也需要加上 __device__ 标识符
struct cuComplex {
float r;
float i;
__device__ cuComplex( float a, float b ) : r(a), i(b) {}
__device__ float magnitude2(void) {
return r * r + i * i;
}
__device__ cuComplex operator*(const cuComplex& a) {
return cuComplex(r * a.r - i * a.i, i * a.r + r * a.i);
}
__device__ cuComplex operator+(const cuComplex& a) {
return cuComplex(r + a.r, i + a.i);
}
};
完整代码如下:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include 结果如下

遇到的问题与解决方案
在编译运行书中所给示例代码时出现了两个问题。
构造函数未加 __device__ 修饰符
书中的代码未给构造函数加上__device__修饰符,如果构造函数未加 __device__ 修饰符,就会报以下错误

解决方案就是给构造函数加上__device__修饰符
找不到glut64.lib和glut64.dll
对于这个问题,首先需要在项目属性中的VC目录中的库目录中添加 glut64.lib 所在目录
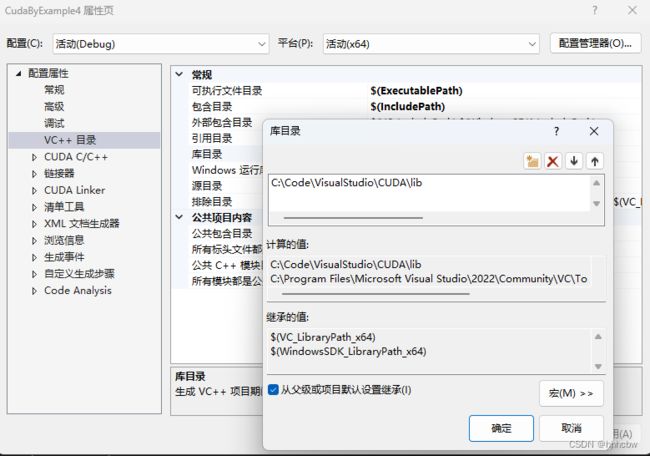
然后把 glut64.dll 放入当前项目所在文件夹即可。