机器学习之决策树(Decision Tree)
决策树(Decision Tree)
- 决策树又称为判定树,是数据挖掘中的一种重要的分类与回归方法,它是一种以树结构(包括二叉树和多叉树)形式来表达的预测分析模型
- 是一种有监督的算法
- 决策树有两种,一种是分类树(输入是离散的),一种是回归树(输入是连续的)
决策树由节点和分支组成:(详情参考数据结构书本)
- 节点分为三种:根节点,内部节点,叶节点
- 分支:用于连接各个节点
决策树分为以下结构:
- 每个内部节点对应于某个属性上的测试(test)或者说是大类
- 每个分支对应于该测试的一种可能结果
- 每个叶节点对应于一个预测结果
- 学习过程:通过对训练样本的分析来确定 划分属性,即内部节点所对应的属性
- 预测过程:将测试示例从根节点开始沿着划分属性所构成的 判定测试序列向下行进,直到到达叶节点
决策树学习的目的是为了产生一棵泛化能力强的决策树,决策树如下所示
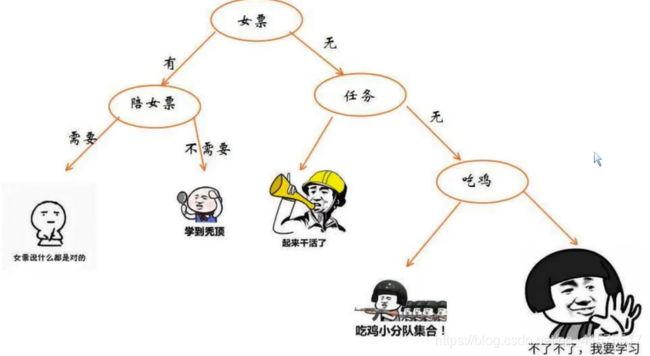
也就是用多个判定语句进行判定,很容易转化成if-then语句:
- 由决策树的根节点到叶节点的每一条路径构建一条规则
- 路径上内部节点的特征对应着规则的条件,而叶节点的类标签对应着规则的结论
决策树的生成过程中一定要遵循 互斥且完备这一规则(互斥且完备:每一个实例都被有且只有一条路路径或一条规则所覆盖)
决策树的构建
策略:自上而下,分而治之
-
自根节点至叶节点的递归过程中,在每个中间节点寻找一个划分属性
- 构建根节点,并且所有训练数据都放在根节点,选择一个最优特征,按着这一特征将训练数据集分割成子集,进入子节点
- 所有子集按内部节点的属性然后递归的进行分割
- 如果这些子集已经能够被基本正确分类,那么构建叶子结点,并将这些子集分到对应的叶节点上去
- 每个子集都被分到叶子节点上,即都拥有了明确的类别,则决策树构建完成
-
停止条件
- 无需划分:当前节点包含的样本全属于同一类别
- 无法划分:当前属性集为空,或是所有样本在所有属性上取值相同
- 不能划分:当前节点包含的样本集合为空
-
如何选择最优的划分属性是决策树算法的核心,也就是先划分哪一个属性
-
特征(属性)选择
-
特征选择是决定用哪一个特征来划分空间
-
我们希望决策树的内部节点所包含的样本尽可能属于同一类别,即节点的纯度越来越高,可以高效的从根节点到达叶节点,得到决策结果
-
信息熵:是度量样本纯度的最常用的指标

若P=0,则P ㏒₂P = 0
若P=1,则P ㏒₂P = 0
ENT(D)的最小值为0,最大值为㏒₂|y|
ENT(D)的值越小,则D的纯度越高
-
信息增益:信息增益直接以信息熵为基础,计算当前划分对信息熵所造成的变化
-
离散属性a的取值:{a₁,a₂,a₃,…,av} , Dv:D在a上取值为av的样本集合
-
以属性a对数据集D进行划分所获得的信息增益为:
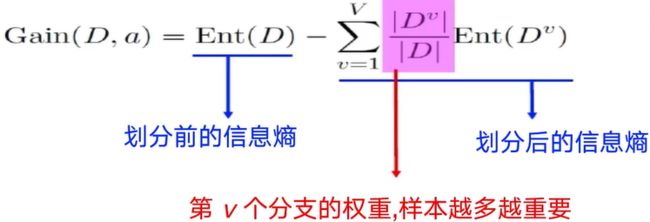
信息增益越大,则意味着使用属性a来进行划分所获得的 纯度提升 越大
以信息增益为基础进行分类的著名决策树算法有ID3决策树算法
-
-
-
特征选择表示从众多的特征中选择一个特征作为当前节点分裂的标准
-
如何选择特征有不同的量化评估方法,从而衍生出不同的决策树
-
-
==算法改进(C4.5算法):==以信息增益为基础进行分类的决策树算法有缺陷,表现为:对可取值数目较多的属性有所偏好,所以就引出了增益率这一概念,可以在信息增益的基础上将数目对属性的影响进行消除,使结果更加合理。

-
基尼指数(CART算法):此算法抛弃了信息熵,而是采用基尼指数来进行运算

决策树的一般构建步骤(按照信息熵):
首先要按照此公式计算出根节点的信息熵(根节点的分类其实就是以最终的判别结果来进行的分类)
以鸢尾花的分类为例(鸢尾花有四个特征,分别为花萼长度、花萼宽度、花瓣长度、花瓣宽度):
为了方便理解,此处鸢尾花的每个特征都假设为只有三个值,分别为长,中,短
==|y| :==表示区分成的种类数,判别鸢尾花的时候只有三种标签(iris-setosa或iris-versicolour或 iris-virginica),所以鸢尾花分类中的|y| = 3
==Pk:==此变量的k也是以鸢尾花的类别进行分类的,也就是每个种类占总数集的比重,比如设iris-setosa的比重为P1,iris-versicolour的比重为P2,iris-virginica的比重为P3,且P1+P2+P3 = 1
所以由此可以计算出根节点的信息熵ENT(D)(ENT(D)的值越小,则D的纯度越高),判断根节点是否纯,如果不纯需要进行下面的划分。
然后进行根节点的选取,也就是以哪一个特征作为根节点来进行第一次的种类划分,依旧是求信息熵,不过此时求的信息熵是以各个特征为准来分别进行划分,假设先求鸢尾花的花萼长度的信息熵,步骤如下:
花萼长度分别有长花萼(D1)、中花萼(D2)、短花萼(D3)
先求Pk,找出长花萼中所对应的各个种类(iris-setosa或iris-versicolour或 iris-virginica)占长花萼总数量的比重即为每个种类所对应的P,P(长花萼iris-setosa)+P(长花萼iris-versicolour)+P(长花萼iris-virginica) = 1,但此时的y依旧是根据标签来判定的,也就是说要代入的数据Pk是每个种类中各个标签所占的比重,而不是本种类占总数目的比重
中花萼和短花萼的信息熵的求法与此相同
由此可以求出各个花萼长度的信息熵D1、D2、D3
也是就是说要计算每一个特征的各个属性的信息熵
然后再以此公式求得此特征的信息增益:
公式的前半部分:Ent(D)是根节点的信息熵,也就是上面第一步所求得的
公式的后半部分:V表示特征中属性的个数,上述例子中V=3,而分母中的|D|则表示特征中参与运算的数据的条数, |Dv|则表示Dv属性的条数,Ent(Dv)表示Dv的信息熵,上面步骤已经求得,直接计算即可
然后对每个特征都进行上述运算,可以针对每个特征分别得出一个信息增益,假设所得信息增益为(信息增益越大证明分类越纯):
Gain(D,花萼长度)、Gain(D,花萼宽度)、Gain(D,花瓣长度)、Gain(D,花瓣宽度),假设其中的花瓣长度所得信息增益最大,那么,则以花瓣长度代替前面提到的根节点作为新的根节来点进行第一次划分所得的枝干分别为
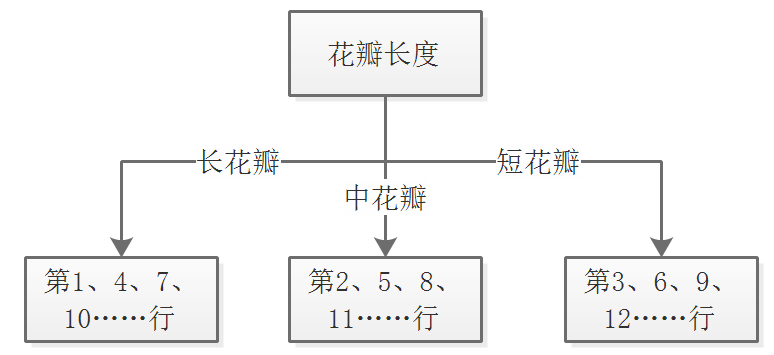
注意:当下面继续划分的时候,则进入递归,此时注意排除掉花瓣长度这一特征,因为计算时要使决策树保持互斥的特性,并且特别需要注意的是,假设在长花瓣的分支下继续进行分类的时候,此时参与分类的只有D1{1、4、7、10……}数据行,其他行不参与此次计算
参与计算的特征集合为花萼长度、花萼宽度、花瓣宽度三个特征,此时要基于D1按照上面所述方法计算各特征的信息增益,若有多个特征的信息增益同样大,则任取一个特征来进行划分
最终可得到一个完整的决策树
值得一提的是,假设分类的时候特征数据不是长、中、短之类的简单条件,而是全部是数,此时决策树中的中间节点则可以按照临界值来划分,也就是以一个值为阈值,特征中的值若大于它,则属于某一类,若小于它,则属于另一类,并且可以制定多个阈值来多次划分。
决策树剪枝
在对决策树泛化性能的影响方面来看,相对于用不同的方法构建决策树,剪枝方法和程度对决策树泛化性能的影响更为显著
剪枝是防止决策树过拟合(过拟合:测试集结果完全贴合训练集,也就是测试集和训练集完全一样)的手段
决策树剪枝对决策树性能提升非常大,尤其是数据带噪声的时候
剪枝的基本策略为:
- 预剪枝:提前终止某些分支的生长
- 后剪枝:生成一棵完全树,再回头剪枝
剪枝的判断依据为剪枝之前的精度和剪枝之后的精度比较,如果精度下降,则此枝不剪;否则减掉此枝,需要将中间节点一个一个的进行比较
预剪枝和后剪枝的对比:
- 时间开销:
- 预剪枝:训练时间开销降低(因为其在构建的时候枝还未生长就已经剪掉了,所以花费时间少一点),测试时间开销降低(其剪枝步骤为:先求出最每一个特征的信息增益率,挑选出信息增益率最大的特征作为根节点,然后以此根节点为基础按照训练集中的各个标签的比重直接进行分类,然后将测试集代入直接进行判断测试集的正确概率并记录,然后也是最关键的地方,也就是判断是否要进行每一个枝的分类,根据其他特征的信息增益率进行分类,计算分类后的正确率并与未分类之前的正确率进行比较,换句话说也就是判断,观察正确率和剪枝之前相比其是否有提升,若有提升,则进行划分;否则禁止划分)
- 后剪枝:训练时间开销增加(因为后剪枝是先构建一棵树,然后再进行剪枝,所以花费时间更多一点),测试时间开销降低(其剪枝步骤为:将某一个中间节点先替换为叶节点,判断替换后的精度是否有提升,若有提升,则直将此节点下面的分类直接删除,也就是这个分类下面不再进行剪枝了(只要是符合条件都认为是某一个标签),此节点直接替换为叶节点;否则不替换)
- 过拟合和欠拟合风险
- 预剪枝:过拟合风险降低,欠拟合风险增加
- 后剪枝:过拟合风险降低,欠拟合风险基本不变
- 泛化性能
- 后剪枝优于预剪枝
连续值与缺失值处理
-
连续值处理:
在很多情况下处理的是连续的数据,由于连续属性的可取值数目不再有限,因此不能直接根据连续属性的可取值来对节点进行划分,而处理这种数据的办法为:连续属性离散化:基本思路为可以在这个连续值上面区分几个区间,按照区间的不同来对数据进行划分,常用方法为二分法
-
缺失值处理:
在很多情况下会遇到带有缺失值的数据,但是如果对带有缺失值的数据弃之不用的话,则会对数据带来极大的浪费,所以需要对数据的划分进行处理,从如何进行划分属性的选择和若如何对样本属性值有缺失的数据划分属性。解决的基本思路为:样本赋权,权重划分
-
在划分进行计算的时候直接以未缺失的样本来进行计算即可,比如计算信息熵,但是注意在计算信息增益率的时候是有权重的。假如在计算的时候一共有19条样本数据,但是只有15条样本数据是完整的,所以此时在计算信息增益率的时候需要给赋一个15/19的权重
决策树的本质
- 每个属性视为坐标空间中的一个坐标轴,假设有d个属性描述的样本,就对应了d维空间中的一个数据点,而决策树中的对样本分类,实质上就是在这个坐标空间中寻找不同类样本中的分类边界
- 决策树的分类边界特点是轴平行,也就是它的分类边界由若干个与坐标轴平行的分段组成
- 当学习任务对应的分类边界很复杂时,需要很多段划分才能获得较好近似,划分出来的分类面可能在图像上呈梯形等图形,当无限精分的时候,梯形等图形就可能会呈现出一条柔滑的曲线
- 注意,决策树可能不仅仅是一棵决策树,还可以在决策树的节点中嵌入神经网络模型或者其他非线性模型,嵌入了其他模型的决策树叫混合决策树
- 决策树由于其算法本身的限制,算法受内存大小限制,不适合进行大数据集的训练,只能进行中小样本的训练
决策树使用的方法
-
可以使用 sklearn.tree 中的模型直接计算,使用方法和支持向量机套用模型的方法类似,在测试鸢尾花数据集的时候,其错误率要比支持向量机错误率高
""" -*- coding: utf-8 -*- @Time : 2021/8/5 8:57 @Author : wcc @FileName: DecisionTree.py @Software: PyCharm @Blog :https://blog.csdn.net/qq_41575517?spm=1000.2115.3001.5343 """ from sklearn.tree import DecisionTreeClassifier import numpy as np import matplotlib.pyplot as plt import pandas as pd class Iris: def __init__(self, file_name, data_set, labels_set, normal_data_set, data_division): self.fileName = file_name self.dataMat = data_set self.labelsMat = labels_set self.normalDataSet = normal_data_set self.dataDivision = data_division # 数据预处理 def iris_processData(self): fr = open(self.fileName) numOfLines = len(fr.readlines()) # 此处一定记得要把标签排除在外 dataMat = np.zeros((numOfLines, 4)) # 标签单独成一列 labelsMat = [] fr.seek(0, 0) index = 0 for line in fr.readlines(): line = line.strip() listLine = line.split(',') dataMat[index, :] = listLine[0:4] if listLine[-1] == 'Iris-setosa': labelsMat.append(1) if listLine[-1] == 'Iris-versicolor': labelsMat.append(2) if listLine[-1] == 'Iris-virginica': labelsMat.append(3) index += 1 labelsMat = np.array(labelsMat) self.dataMat = dataMat self.labelsMat = labelsMat # 数据归一化(0-1归一化) def iris_normal(self): colDataMax = self.dataMat.max(0) colDatamin = self.dataMat.min(0) normalDataSet = np.zeros(self.dataMat.shape) normalDataSet = (self.dataMat - colDatamin)/(colDataMax - colDatamin) self.normalDataSet = normalDataSet # 决策树对测试集进行测试 def iris_decision(self): totSize = int(self.normalDataSet.shape[0]) trainSize = int(self.normalDataSet.shape[0]*self.dataDivision) testSize = int(self.normalDataSet.shape[0]*(1-self.dataDivision)) result = [] errorCount = 0 errorRecords = {} correctRecords = {} index = 0 # 模型定义 model = DecisionTreeClassifier() # 模型函数,参数为样本数据和数据标签 model.fit(self.normalDataSet[0:trainSize, :], self.labelsMat[0:trainSize]) # 模型测试,predict()方法为预测方法,参数为测试集数据 result = model.predict(self.normalDataSet[trainSize:totSize, :]) for i in range(int(testSize)): if self.labelsMat[trainSize + i] != result[i]: errorCount += 1 errorRecords[i] = result[i] correctRecords[i] = self.labelsMat[trainSize + i] print('错误个数:') print(errorCount) print('错误位置及错误值:') print(errorRecords) print('相应位置的正确值:') print(correctRecords) print('正确率:%f%%' % ((1-errorCount/testSize)*100)) if __name__ == '__main__': fileName = 'iris.txt' # 'datingTestSet.txt'# 文件路径 dataMat = [] # 数据集(自己读取) labelsMat = [] # 标签集(自己读取) normalDataSet = [] #归一化后的数据集 dataDivision = 0.8 # 数据集中训练集和测试集的划分比例 iris = Iris(file_name=fileName, data_set=dataMat, labels_set=labelsMat, normal_data_set=normalDataSet, data_division=dataDivision) iris.iris_processData() iris.iris_normal() iris.iris_decision() -
可以按照算法思路自己写决策树的算法并进行优化