CNN变体模型学习
文章目录
- 前言
- 文献阅读
-
- 摘要
- 数据和方法
- 性能指标
- 结论
- LeNet5
- AlexNet
- VGGNet
- NiN网络中的网络
- 总结
前言
This week, I read an article that proposed a new method to improve the prediction effectiveness of numerical models based on deep learning technology. As well as I know LeNet, AlexNet, VGGNet, and NIN models and their code design.
本周,阅读了文章,这篇文章研究提出了一种基于深度学习技术提高数值模型预测有效性的新方法。以及我了解LeNet,AlexNet,VGGNet,以及NIN四种模型及其模型代码的设计。
文献阅读
摘要
空气质量预测是公共卫生知道和空气污染控制的重要工具。三维数值模型可以代表大气中大多数主要的物理和化学过程。它可以在区域尺度上以高空间和时间分辨率明确反映空气污染物的形成和消散;这是空气质量预测的主流方向。然而,由于污染物排放清单的不确定性、气象预测的偏差、化学过程的复杂性以及模型中物理过程参数化的不完善等,数值模型的预测结果与PM等主要污染物的观测浓度仍存在显著偏差。2.5和 O3;这对空气质量预报的准确性有直接影响。已经开发了多种数值模型输出的校正方法,以最小化预测偏差。统计模型校正是一种常用方法,通过使用同一时间段的模型预测和观测数据,初步建立了一定的统计关系用于修正污染物浓度数值模型的预测偏差。作为一种新形式的统计模型,深度学习可以使用深度神经网络从大量训练数据中自动学习特征,其非线性预测能力优于传统统计方法。本研究提出了一种基于深度学习技术提高数值模型预测有效性的新方法。每小时PM2.5和 O3以中南部BTH区域的浓度数据和相应网格的WRF-Chem模型预测结果为训练数据,同时纳入预测时间前的观测数据,构建多源数据融合预报优化系统。
数据和方法
天气研究和预报模型与化学(WRF-Chem)是由NOAA(国家海洋和大气管理局)和NCAR(国家大气研究中心)开发的完全耦合的化学输运模型。
整个数据集分为训练集、验证集和测试集三类,具体信息如表1所示。

问题定义:
我们假设相对于时刻的开始时间为 t = 0。因此,对于给定的接下来 p 个时间段的空气质量 WRF-Chem 模拟 {w0,w1 ,wp−1} 和实际空气质量观测 {O−h,O−2 ,O−1} 对于过去的 h 时间段,我们旨在预测下一个 p 时间段 {O0,O1 ,Op−1}.具体而言,建立了以下映射关系:
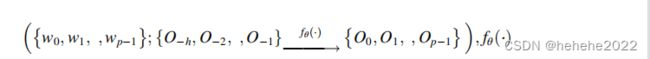
上面表示输入和输出之间的映射模型,将使用深度神经网络技术实现,其中 θ 是要在网络中学习的参数。
输入过去空气质量观测值的时间范围设置为24 h,并预测未来144 h的空气质量;因此,h = 24 和 p = 144。本文设计的神经网络预测模型将进行 24 小时预测的训练,训练模型将用于六次递归迭代的测试,以计算未来 144 小时的预测结果。
在深度学习中,通常用于处理时间序列数据的网络结构包括门控循环单元(GRU)(Cho等人,2014)和转换器(Vaswani等人,2017)。本研究分别基于GRU和变压器设计了两种深度学习模型结构DeepPM和APTR。前者侧重于挖掘空气质量变化的周期性模式,而后者则对时间序列数据中的长期连接具有很强的建模能力。
性能指标
使用4个指标评估预测结果:均方根误差(RMSE)、绝对值误差(MAE)、对称平均绝对百分比误差(SMAPE)和皮尔逊相关系数(r)。
上述指标定义如下:
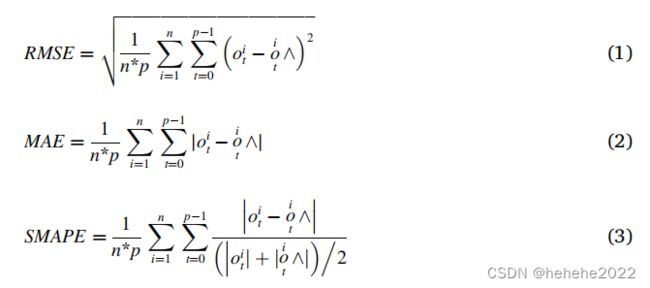
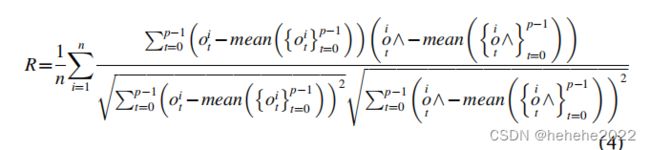
n 表示测试样本的数量,p 表示预测持续时间
coti 和 ̂oit分别表示t检验样本的预测矩i的观测值和模拟值。
结论
DeepPM和APTR模型优化每小时浓度预测的有效性的总体评估PM2.5和 O3对于WRF-Chem输出的所有站点。优化的PM2.5和 O3无论是对未来的24小时预测还是144小时预测,两种模型的预测都明显优于WRF-Chem的直接输出。
LeNet5
LeNet的模型图:
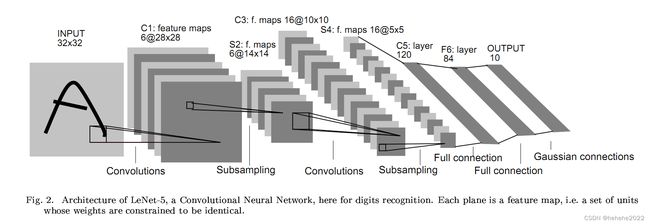
该网络的特点:
- 所有卷积核均为5X5,步长为1
- 所有池化方法为平均池化
- 所有激活函数为sigmoid
通过梯度下降训练卷积神经网络,目的是实现手写数字识别。
卷积核块用的是5X5的窗口,得到的结果做sigmoid,从单通道变成了6通道,
LeNet的代码:
#定义一个网络模型
class mylenet5(nn.Module):
def __init__(self):
super(mylenet5, self).__init__()
self.c1=nn.Conv2d(in_channels=1,out_channels=6,kernel_size=5,padding=2)
self.Sigmoid=nn.Sigmoid()
self.s2=nn.AvgPool2d(kernel_size=2,stride=2)
self.c3=nn.Conv2d(in_channels=6,out_channels=16,kernel_size=5)
self.s4=nn.AvgPool2d(kernel_size=2,stride=2)
self.c5=nn.Conv2d(in_channels=16,out_channels=120,kernel_size=5)
self.flatten=nn.Flatten()
self.f6=nn.Linear(120,84)
self.output=nn.Linear(84,10)
def forward(self,x):
x=self.Sigmoid(self.c1(x))
x=self.s2(x)
x=self.Sigmoid(self.c3(x))
x=self.s4(x)
x=self.c5(x)
x=self.flatten(x)
x=self.f6(x)
x=self.output(x)
return x
AlexNet
相当于更深更大的LeNet,主要的改进:
- 丢弃法 :因为模型变大了,用丢弃法做一些正则化处理,隐藏全连接层后加入了丢弃层。
- ReLu:激活函数从sigmoid改为relu,减缓了梯度消失
- MaxPooling
AlexNet 和 LeNet的架构对比:用了更大的核窗口和步长,因为图片更大了;更大的池化窗口,使用更大的池化层。

AlexNet进去的图片是224X224的彩色图片,用更大的窗口11X11,通道数从6变为了96,stride为4,3X3的池化窗口,LeNet是32X32的灰度图片,5X5的卷积窗口,输出的通道数为6,pad为1,2X2的池化窗口。
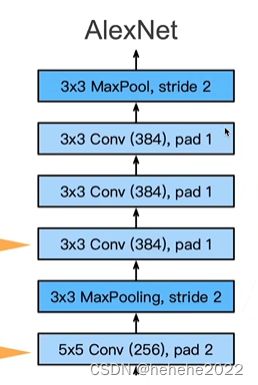
AlexNet用了5X5的卷积,pad为2(让输入和输出的尺度一样),输出通道是256(LeNet的输出通道是16),池化层大小为3X3,步长为2,连用三个3X3的卷积层,最后用一次最大池化。
数据增强:卷积对位置光照比较敏感,在输入图片里面增加大量的变种(变化颜色,光亮)。
总结:
AlexNet是更大更深的LeNet,10x参数个数,260X计算复杂度。
新进入了丢弃法,ReLU,最大池化层,和数据增强。
代码:
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 96, 11, 4,1), # in_channels, out_channels, kernel_size, stride, padding
nn.ReLU(),
nn.MaxPool2d(3, 2), # kernel_size, stride
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96, 256, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(3, 2),
# 连续3个卷积层,且使用更小的卷积窗口。除了最后的卷积层外,进一步增大了输出通道数。
nn.Conv2d(256, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 256, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(3, 2)
)
self.fc = nn.Sequential(
nn.Linear(256*5*5, 4096),
nn.ReLU(),
nn.Dropout(0.5),#加丢弃层,丢弃的概率为0.5,也就是50%的概率将输出置为0
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, 10),
)
def forward(self, img):
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0], -1))
return output
VGGNet
研究卷积网络深度对研究的影响,使用3X3的卷积,将深度增加到16-19层可以显著的改进。
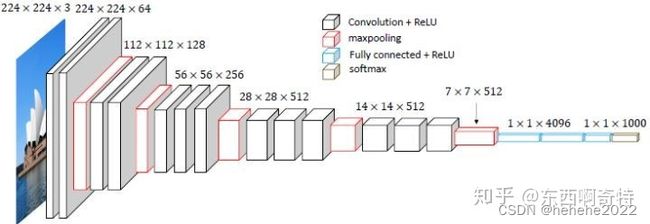
输入尺寸是224X224的RGB图片,图像通过一系列卷积层,每层都使用3X3的卷积核,因为3X3是能够捕捉画面上下左右中心的最小尺寸,如上图中的第一层conv1,64是卷积宽(卷积核的个数),卷积核的步长为1,填充为1,在卷积后面使用了5个最大池化层,最大池化的窗口为2X2,步长为2;卷积层后是三个全连接层,前两个层各有4096个通道,第三个有1000个通道,每个通道表示一类,最后是softmax层。
创新点
VGGNet全部使用33的卷积核和22的池化核,通过不断加深网络结构来提升性能。网络层数的增长并不会带来参数量上的爆炸,因为参数量主要集中在最后三个全连接层中。同时,两个33卷积层的串联相当于1个55的卷积层,3个33的卷积层串联相当于1个77的卷积层,即3个33卷积层的感受野大小相当于1个77的卷积层。但是3个33的卷积层参数量只有77的一半左右,同时前者可以有3个非线性操作,而后者只有1个非线性操作,这样使得前者对于特征的学习能力更强。
模型的主要代码:
def vgg13(input_shape=(224,224,3), nclass=1000):
"""
build vgg13 model using keras with TensorFlow backend.
:param input_shape: input shape of network, default as (224,224,3)
:param nclass: numbers of class(output shape of network), default as 1000
:return: vgg13 model
"""
input_ = Input(shape=input_shape)
x = Conv2D(64, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu')(input_)
x = Conv2D(64, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu')(x)
x = MaxPool2D(pool_size=(2, 2), strides=(2, 2), padding='same')(x)
x = Conv2D(128, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu')(x)
x = Conv2D(128, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu')(x)
x = MaxPool2D(pool_size=(2, 2), strides=(2, 2), padding='same')(x)
x = Conv2D(256, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu')(x)
x = Conv2D(256, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu')(x)
x = MaxPool2D(pool_size=(2, 2), strides=(2, 2), padding='same')(x)
x = Conv2D(512, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu')(x)
x = Conv2D(512, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu')(x)
x = MaxPool2D(pool_size=(2, 2), strides=(2, 2), padding='same')(x)
x = Conv2D(512, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu')(x)
x = Conv2D(512, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu')(x)
x = MaxPool2D(pool_size=(2, 2), strides=(2, 2), padding='same')(x)
x = Flatten()(x)
x = Dense(4096, activation='relu')(x)
x = Dropout(0.5)(x)
x = Dense(4096, activation='relu')(x)
x = Dropout(0.5)(x)
output_ = Dense(nclass, activation='softmax')(x)
model = Model(inputs=input_, outputs=output_)
model.summary()
opti_sgd = optimizers.sgd(lr=0.01, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=opti_sgd, metrics=['accuracy'])
return model
NiN网络中的网络
全连接层的问题:
之前在AlexNet 和 VGGNet都在最后用了两个比较大的4096的全连接层,全连接层占用参数空间,重要的问题是会带来过拟合问题。
卷积后的第一个全连接层的参数:
LeNet 16X5X5X120=48K
AlexNet 256X5X5X4096=26M
VGG 512X7X7X4096=102M
NIN的思想是完全不要全连接层。
NiN块:
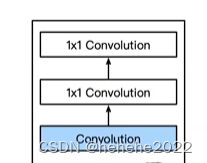
首先有一个卷积层,接下来跟两个全连接层,1X1的卷积就可以等价成全连接层。
步幅为1,无填充,输出形状跟卷积层输出一样。
NIN架构没有全连接层,它交替使用NIN块和步幅为2 的最大池化层,最后使用全局的平均池化层得到输出。全局池化层的高宽就等于输入的高宽。
总结:
NIN块使用卷积层加两个1X1卷积层,后者对每个像素增加了非线性。NIN使用全局的平均池化层来代替VGG和AlexNet中的全连接层,不易拟合,有更少的参数个数。
模型设计:
class NiN(nn.Module):
def __init__(self, num_labels):
super(NiN, self).__init__()
self.net = nn.Sequential(
self.nin_block(in_channels=3, out_channels=96, kernel_size=11, stride=4, padding=2),
nn.Dropout(p=0.5),
nn.MaxPool2d(kernel_size=3, stride=2),
self.nin_block(in_channels=96, out_channels=256, kernel_size=5, stride=1, padding=2),
nn.Dropout(p=0.5),
nn.MaxPool2d(kernel_size=3, stride=2),
self.nin_block(in_channels=256, out_channels=384, kernel_size=3, stride=1, padding=1),
nn.Dropout(p=0.5),
nn.MaxPool2d(kernel_size=3, stride=2),
self.nin_block(in_channels=384, out_channels=num_labels, kernel_size=3, stride=1, padding=1),
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten()
)
self.init_weight()
def forward(self,x):
return self.net(x)
def init_weight(self):
for layer in self.net:
if isinstance(layer, nn.Conv2d):
nn.init.kaiming_normal_(layer.weight, mode='fan_out', nonlinearity='relu')
nn.init.constant_(layer.bias, 0)
def nin_block(self, in_channels, out_channels, kernel_size, stride, padding):#NIN块的设计
return nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride,
padding=padding),
nn.ReLU(),
nn.Conv2d(in_channels=out_channels, out_channels=out_channels, kernel_size=(1, 1), stride=(1, 1)),
nn.ReLU(),
nn.Conv2d(in_channels=out_channels, out_channels=out_channels, kernel_size=(1, 1), stride=(1, 1)),
nn.ReLU()
)
def test_output_shape(self):
test_img = torch.rand(size=(1, 3, 227, 227), dtype=torch.float32)
for layer in self.net:
test_img = layer(test_img)
print(layer.__class__.__name__, 'output shape: \t', test_img.shape)
# nin = NiN(num_labels=5)
# nin.test_output_shape()
总结
本周学习了CNN的四个变体模型,对这四种模型的模型设计有了一定的了解,下周将继续学习其他的变体模型。