RNN学习
文章目录
- 前言
- 文献阅读
-
- 摘要
- 介绍
- 模型
- 结论
- 循环神经网络
-
- 为什么不使用标准的神经网络呢?
- 什么是循环神经网络?
- 不同类型的RNN
- 循环神经网络的梯度消失
- GRU门控循环单元
- 总结
前言
This week,I read a paper which describes the authors use a conditional deep convolutional generative adversarial network to predict the geopotential height of the 500 hPa pressure level, the two-meter temperature and the total precipitation for the next 24 h over Europe.In addition,I also learn about the Recurrent Neural Network,such as the types of the RNN,the gradient disappearance and GRU.
本周阅读了一篇文献《A generative adversarial network approach to (ensemble) weather prediction》,文献主要讲了作者使用了CGAN对欧洲上空500hPa气压水平的地势高度、两米温度和未来24小时的总降水量进行预测。学习了循环神经网络的相关知识,如RNN的种类、梯度消失以及GRU相关知识。
文献阅读
题目:A generative adversarial network approach to (ensemble) weather prediction
作者:Alex Bihlo
Department of Mathematics and Statistics, Memorial University of Newfoundland, St. John’s (NL), A1C 5S7, Canada
摘要
作者使用了条件深度卷积生成对抗网络来预测欧洲上空500hPa气压水平的地势高度、两米温度和未来24小时的总降水量。提出的模型基于4年的ERA5再分析数据进行训练,发现对位势高度和2米温度的预测和真实值一致,但在总降水量上预测不一致,进一步使用蒙特卡洛dropout开发一个基于深度学习策略的集成天气预测系统,进一步提高预测模型的能力。
介绍
传统的天气预报是用先进的数值模型来完成的,计算成本高,还需要对未解决过程采取先进的物理参数化方案。深度神经网络可以以传统基于微分方程的预报的一小部分计算成本发布数值天气预报。作者旨在研究两个问题:
1.旨在研究基于条件生成对抗网络(cGAN)的架构学习大气系统基本条件分布的能力。换句话说,我们的目标是研究cGANs如何学习气象数据背后的物理原理。
2.第二个问题是使用机器学习量化天气预报中的不确定性的问题。
我们旨在研究是否可以通过运行略有不同的cGAN的集合来获得有意义的统计信息。实现此目的的一种计算成本低且直接的方法是将 dropout 层引入模型并在训练和测试阶段使用 dropout,即通过使用 Monte-Carlo dropout。也就是调查使用蒙特卡洛dropout产生的统计信息是否与未来大气状态的有意义的物理不确定性一致。
GAN(Generative Adversarial Networks)的介绍:一种无监督的深度学习模型
GAN模型的主要组成:
1,生成器G(generator)
2,判别器D(discriminator)
GAN训练的目的是希望生成器G能够学习到样本的真实分布Pdata(x),那么G就能生成之前不存在的但是却又很真实的样本。
z是随机的噪声,它属于F为任意分布,将z放到generator当中,generator可以看作一个函数,生成X,x服从PG(X)分布,PG(X)分布不是我们想要的,我们希望经过生成器可以生成一个满足Pdata(X)的分布,我们可以通过调整generator中的参数,使得生成的分布和真实分布尽可能接近。

参数如何更新的?
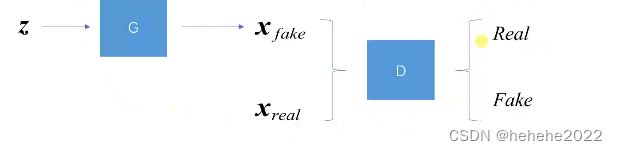
GAN的网络结构示意图:
输入Z通过generator生成一个Xfake,有满足Pdata的真实数据Xreal,将Xfake与Xreal送入判别器中进行训练,判别器对输入做二分类,判断真假。
数学表达:
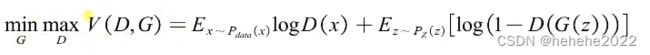
D(X)是判别器最终输出的值,首先G不动,通过调整D的值来最大化我们的价值函数V(D,G),让D(x)趋近于1,D(G(z))趋近于0,把真数据和假数据进行区分;通过调整G来最小化maxV,让D(G(z))趋近于1。 返现D(G(z))趋近于0和D(G(z))趋近于1产生了冲突对抗。
模型
本研究训练的cGAN模型本质上是对其他人提出的经典pix2pix体系结构的三位改变。生成器G是由Ronneberger,Fischer和Brox首次提出的U-net架构,通过二维再分析数据输入一系列帧,旨在预测下一帧未来的二维再分析数据。也就是说,我们不是一次一步地进行预测,而是一次预测整个图像序列。
U-net 生成器中的数据下采样使用核大小为(4,4,4)和步长为(2,2,2)或(1,2,2)的三位跨卷积完成。除第一层外,其他所有数据都使用批处理归一化。在每个下采样层中选择的激活是ReLU.总共使用六个下采样层,分别具有64、128、256、256、256、256个滤波器。生成器模型的瓶颈由两层核大小(2,2)的卷积LSTM组成和,每层有256 个过滤器。
判别器是使用与生成器中使用的编码器块相同的编码器块,这里共使用5层,分别有64、128、256、512和1个过滤器。最后一层使用 sigmoid 激活函数。生成器和鉴别器的网络结构如图


使用蒙特卡洛dropout的集成预测
在pix2pix架构中明确添加噪声,就像标准无条件GANs那样,不是一个有效的策略,因为模型忽略了其预测中的噪声。相反,通过在训练和测试时使用dropout来添加噪声,观察到结果模型仅表现出最低限度的随机性。虽然高度随机的输出可能与图像到图像的转换等应用范围相关,但天气预报是否需要广泛的随机性是一个基本问题。大气系统在多大程度上是随机的,因此是可预测的,还有待讨论,大多数数值天气预报模型的核心是确定性的,随机性进入参数化和集成预测技术的水平。因此,评估基于的改进的cGAN架构是否可以有效地捕获其建模的大气参数的基本条件分布及其固有不确定性程度是很好的。
结论
在本文中,研究了使用条件生成对抗网络来学习大气系统物理学的条件概率分布。选择了 500 hPa 压力水平的高度、两米的温度和总降水量作为参数,并使用 4 年的 ERA5 再分析数据训练了完全相同的 vid2vid架构的三个独立版本,以预测未来 24 小时内的天气 1 年。
通过ACC,RMSE,CRPS和个别案例研究以及与其他模型的比较评估的所有参数获得的结果显示了该架构学习基本物理过程的潜在能力以及大气系统演变背后的一些固有不确定性。特别是,蒙特卡洛dropout的加入通过为基于机器学习的天气预报提供廉价的误差估计来提高结果的可靠性。
循环神经网络
建模会用到的符号定义
举例,识别出一个句子中的人名。
输入 X:Harry Potter and Hermione Granger invented a new spell.
输出 Y:1 1 0 1 1 0 0 0 0
用9组特征来表示9个单词,用Xt来表示句子中每一个单词,t 指示序列中的位置,输出也是一样的,用Yt来表示,用Tx=9表示输入数据的长度,Ty表示输出序列的长度。
将词汇表中的每一个都用one-hot的表示,单词在的那一位表示为1,其他的表示为0,当一个单词不在词汇表中,创建一个新的标记,称其为Unknown Word、< UNK >。
为什么不使用标准的神经网络呢?
问题:
1.输入和输出对于不同的例子会有不同的长度。
2,最重要的是标准神经网络不会共享那些从不同的文本位置学到的特征。
什么是循环神经网络?
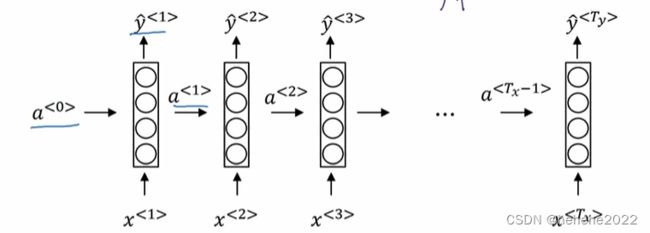
如果从左到右读一个句子,读的第一个词语将其表示为x1,输入到神经网络中,预测输出判断输出是不是人名的一部分,当读取句子的第二个词的时候,不仅通过X2去预测Y2,还将第一步的计算结果作为其输入信息的一部分,后面依次是类似的,通常会在最开始加上一个a0,一般是全0向量。循环神经网络从左到右扫描数据,它所用的参数是共享的,Wax表示,激活函数各层水平链接是由一组参数Waa来控制的,相似的Wya控制输出预测。
RNN的缺点是它只是用序列中早期的信息来做预测。
前向传播的公式表示:

压缩参数矩阵,将Waa和Wax堆叠起来,就得到了Wa, 如果a是100维的向量,X是10000维的向量,Waa是100X100维度的向量,Wax是100X10000维度的矩阵,Wa是一个100X10100维的矩阵。

RNN反向传播:
损失函数使用交叉熵损失函数,从以前学习的例子中可以看出反向传播要求在相反的方向进行计算和传递信息,最重要的是从右向左的那条反向传播,基于时间的反向传播算法。
不同类型的RNN
前面一直说的输入和输出是等长的,这种称为多对多架构,许多输入和输出是不同的类别,这个时候Tx就不等于Ty,可以通过修改RNN的基本结构来解决这个问题,比如情绪分级问题,输入是一段影评,输出是0、1,正负面评价,我们可以让RNN输入完整的句子,在最后一个时间步骤输出Y。
总结RNN的种类:

one to one :原始的神经网络,不需要RNN来处理。
one to many:像一段音频的生成,或一段序列产生的例子。
many to one :情绪分级的例子
many to many:一种是Tx=Ty,一种是Tx!=Ty
循环神经网络的梯度消失
基本的RNN算法还有一个很大的问题,就是梯度消失的问题。一个很深很深的网络100层,甚至更深,对这个网络从左到右做前向传播然后再反向传播。我们知道如果这是个很深的神经网络,从输出 y ^ 得到的梯度很难传播回去,很难影响靠前层的权重,很难影响前面层的计算。
对于有同样问题的RNN,首先从左到右前向传播,然后反向传播。但是反向传播会很困难,因为同样的梯度消失的问题,后面层的输出误差很难影响前面层的计算。事实上梯度消失在训练RNN时是首要的问题,尽管梯度爆炸也是会出现,但是梯度爆炸很明显,因为指数级大的梯度会让你的参数变得极其大,以至于你的网络参数崩溃。所以梯度爆炸很容易发现,因为参数会大到崩溃,会看到很多NaN,或者不是数字的情况,这意味网络计算出现了数值溢出。如果发现了梯度爆炸的问题,一个解决方法就是用梯度修剪。梯度修剪的意思就是观察你的梯度向量,如果它大于某个阈值,缩放梯度向量,保证它不会太大,这就是通过一些最大值来修剪的方法。所以如果你遇到了梯度爆炸,如果导数值很大,或者出现了NaN,就用梯度修剪,这是相对比较鲁棒的,这是梯度爆炸的解决方法。然而梯度消失更难解决。
GRU门控循环单元
它修改了循环神经网络的隐藏层,使其可以更好地捕捉长距离的关系,并改善了梯度消失问题。

“The cat, which already ate……, was full.”,你需要记得猫是单数的,这里是was而不是were,“The cat was full.”或者是“The cats were full”。当我们从左到右读这个句子,GRU单元将会有个新的变量称为 c ,代表细胞(cell),即记忆细胞。记忆细胞的作用是提供了记忆的能力,比如说一只猫是单数还是复数,所以当它看到之后的句子的时候,它仍能够判断句子的主语是单数还是复数。于是在时间 t 处,有记忆细胞Ct,GRU实际上输出了激活值at,at=ct。所以这些等式表示了GRU单元的计算,在每个时间步,我们将用一个候选值重写记忆细胞,即C~t的值,所以它就是个候选值,替代了Ct的值。然后我们用tanh激活函数来计算,C ~t=tanh(Wc[Ct-1,Xt]+bc)。
总结
本周阅读的文献理解的不是很深入,关于实现的细节还不是很懂,下周会继续进行学习。对于RNN的学习,主要学了RNN的模型结构,公式,以及GRU,下周学习LSTM以及RNN的代码。