《Improved Recurrent Neural Networks for Session-based Recommendations》 DLRS 2016 阅读笔记
摘要:本篇论文在上篇论文的基础上对该模型进行优化,主要体现在以下几点:
- 新的数据预处理方式,数据增强
- 数据分布改变(时效性)
- Generalised distillation
- item embedding代替全预测空间
1.基础模型
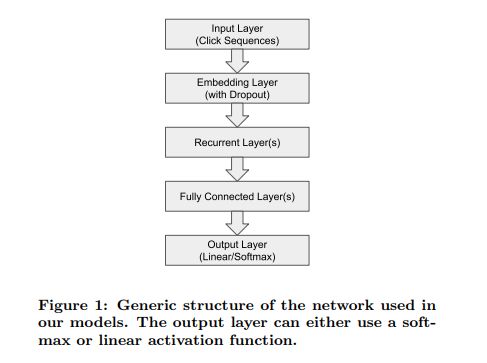
模型依旧简单,但是不同于之前的模型,它对embedding层加入了dropout参数来防止过拟合。
首先介绍:
2.1数据增强
本篇作者用了两种方法做数据增强,一种是预处理增加数据量,一种是embedding dropout;众所周知每个session又长又短,有些用户一次就能找到自己想要的,而有些需要大量点击后才能找到自己想要的,所以对于这种序列不定长并且都有意义的情况下,作者认为每一个time-stamp的点击都应该视为训练样本,即对于一个点击序列 [x1, x2, x3, x4,… xn],它的训练样本拆分为([x1, V(x2)]),([x1, x2, V(x3)]), [x1, x2, x3, V(x4)]

第二种Embedding dropout(理论是用户可能存在噪声点击即错误点击,这种方式可以用来减轻过拟合):
嵌入丢失是应用于输入序列的一种正则化形式[6]。将其应用于单击序列相当于随机删除单击的预处理步骤。直观地说,这使得我们的模型对嘈杂的点击不太敏感,例如用户可能无意中点击了不感兴趣的项目。因此,它使模型不太可能过度适应特定的噪声序列。它也可以被看作是数据扩充的一种形式,在这种情况下,为模型训练生成更短的剪枝序列。我们将这两种方法应用于所有模型,图3显示了一个图形示例。请注意,在每个训练阶段的每个序列中都会有不同的单击。

2.2 时空适应性改变(Adapting to temporal changes)
作者提出推荐不同于常规NLP任务,输入的特性是可能随时空改变的,比如新上的产品和过早的产品的关联性可能就不那么大,为此作者提出了时间阈值,过时的item将被剔除,但是这样会减少训练数据,所以作者提出了一个fine-tune的方法,即:
在全部数据集上训练初始模型,并用其参数来初始化另一个模型,该模型只在训练满足阈值的数据。即pre-trained方法。
2.3 Use of privileged information
这里是使用privileged information(不知是否可以翻译为超越信息)来训练模型。假设有序列[x1,x2,…,xr,xr+1,…,xn-1,xn],当此条训练数据是使用[x1,x2,…,xr]预测xr+1,那么其对应的privileged information是[xn,xn-1,…,xr+2]。
思路是,用户点击某item后的点击序列中实际上能提供该item的信息,这些信息尽管在实际预测时使用不上,但在训练时我们可以加以利用。具体做法上,先使用privileged information训练一个模型,作为teacher模型,然后训练一个student模型,即我们实际想要学习的模型。
假设teacher模型是M*,模型输出是M*(x*),student模型是M,模型输出为M(x),预测的实际输出(即label对应的one-hot encoding)为V(xn),那么此时的损失函数为:
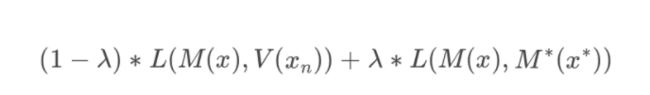
2.4 Output embeddings for faster predictions
本文提出了一种新的做法,即输出层预测的不再是点击每个item的概率,而是直接输出item的embedding,并与label对应的item的embedding进行对比,计算cosine距离作为损失。
但是,这种方法需要item的embedding十分准确,本文提出的方法是使用模型训练出的item embedding作为label。而这里的模型可以是使用基准模型+前三种改进方式训练出的模型
实验:
训练集:RecSys Challenge 2015 dataset
训练样本:7966257 ;测试集:15234 ;preprocess后训练样本:23670981
作者设置了四个时间阈值 [1/256, 1/64, 1/16, 1/4, 1/1] ,按照时间选择最近的训练样本;
训练时,对于batch序列补零。RNN使用GRU
M1:RNN + preprocess + embedding dropout
M2:M1 + fine-tune with recent training dataset
M3:M3 + privileged information
M4:fast predict output embedding
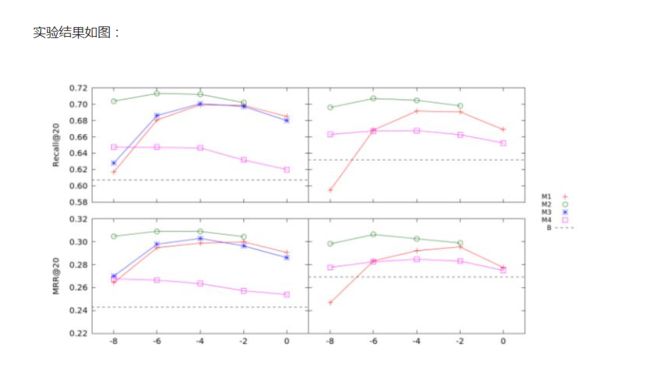
左图为RNN 100维的结果,右图为RNN 1000维的结果,横轴是时间阈值的选择。
在结合之前模型的结果看:

很明显, fine-tune with recent dataset是很有必要的;作者没有在RNN 1000下展示结果是因为其训练时间过长。可以看到对于baseline的RNN方法,作者提出的模型都有提升,只不过RNN的维度增加并不能保证准确率的提升。
另外针对M4,作者给出表格:
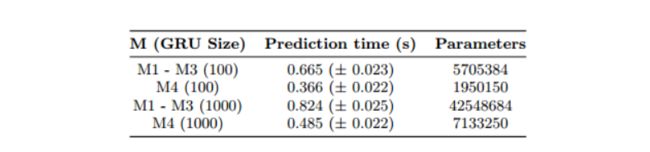
显示其预测时间可以大大缩短,未来前景不错。
结论:针对Session-based Recommendation, 在前人的基础上作者没有过多探索模型层面的改进,而是在数据处理上更精细,包括数据增强,微调,过拟合embedding dropout的处理和future prediction的介入都很巧妙,并且尝试了一种embedding的方法来加速推荐预测的速度,未来可以探索更多权衡embedding-based的方法。
Reference
- https://zhuanlan.zhihu.com/p/30550859
- https://www.jianshu.com/p/e73f47050e0a