深度学习开发任务实例(无人小车)
目录
1 机器学习VS深度学习
2 深度学习开发实例
2.1任务背景与目标
2.2 任务需求梳理
2.3 明确数据采集需求
2.4数据采集
2.5 数据标注
2.6 数据集拆分
2.7 检测算法原理
2.8 模型训练
2.9 效果与指标
3 总结与拓展
1 机器学习VS深度学习
如果使用传统机器学习方法我们要实现图片分类,做法如下:
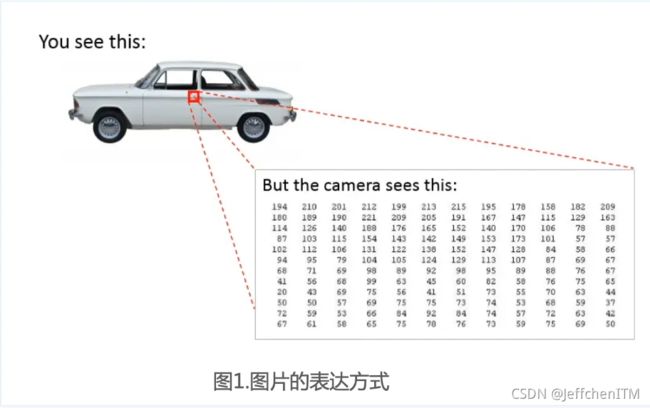
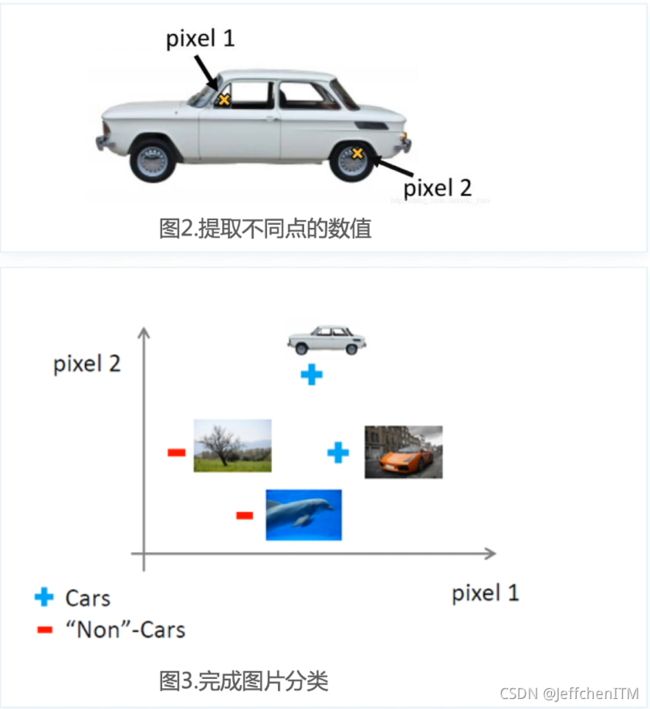
缺点:特征过多,如果将每个像素都作为特征点,那么对于一张640×320的RPG图片,特征数量为640×320×3≈61万个特征
机器学习: 利用算法使计算机能够像人一样从数据中挖掘出信息
深度学习:相比于其他方法参数更多、模型更复杂、使得模型对数据理解更深、更智能。

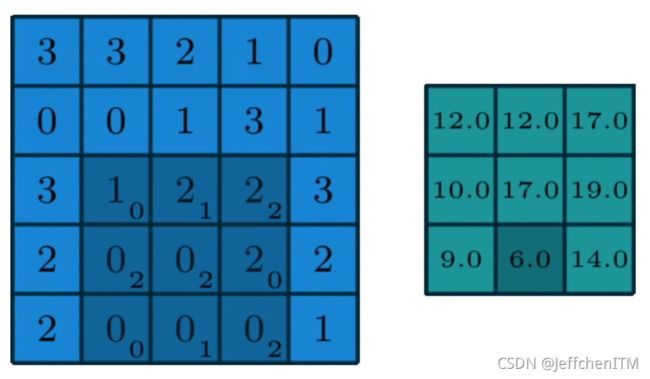
深度学习的特征提取方法:卷积
满足“线性性”和“平移不变性”。
卷积神经网络中的“卷积运算”,本质上对应的是计算“相关性”
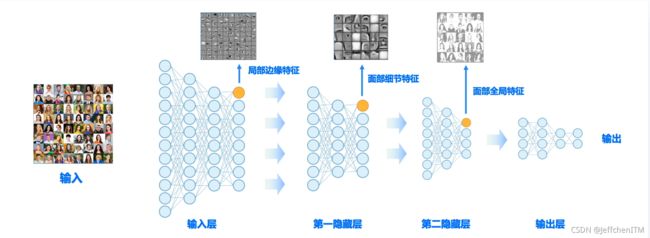
多隐层的深度神经网络
以面部识别为例,构建一个含有两个隐藏层的前馈神经网络
学习的是神经元中的权重参数
2 深度学习开发实例
2.1任务背景与目标
任务背景:
自动驾驶行业近些年来逐渐火爆,计算机视觉在其中起到了非常重要的作用。某公司希望给其生产的玩具车赋予检测交通标志的能力。希望能够在模拟场景中识别常见交通标志。
任务目标:
在玩具车前置摄像头采集到的图片中,检测交通标志的具体位置
任务解析过程:

2.2 任务需求梳理
样本具体化:
图像是具体的表现形式,除了主体以外会包含大量信息,如:背景、光照等。
算法光线敏感:
侧光、面向光、背光、强光、暗光对算法的效果会有不同的影响,甚至室内室外也会有差别,实际使用时,如果训练数据中没有相关光照场景的数据,可能会在该场景下模型效果表现欠佳。
理解硬件条件可能造成的图片效果偏差:
图片数据采集过程中,由于硬件或者工程组装差别,可能会使图片采集发生色差、模糊、角度变化等,如果训练数据中没有相关数据,模型泛化性会较弱。
客户理解偏差:
当前阶段,不少客户对计算机视觉领域的任务理解依然有偏差,如不理解光线对模型效果的影响,不能清晰的表达业务场景诉求等。这些都要在任务初始阶段梳理清晰,否则可能会在模型交付时影响客户口碑。
因此,我们需要在任务开始前,对这些细节进行梳理与沟通。通过对细节的梳理,可以使数据采集过程与测试用例梳理时更加明确,也可以增进客户对算法能力的理解。
2.3 明确数据采集需求



2.4数据采集
根据确认的需求,采集对应的图片,图片采集需要注意:
使用真实的玩具车进行数据采集·覆盖不同场景
涵盖所有可能的光照情况
涵盖所有交通标志推动了一大类非线性映射函数学习问题的解决
采集数量:根据任务要求不同略有差异,玩具车场景任务较为简单,总计采集1万张图片。
采集方式:让小车在不同场景形式,使用摄像头录制视频,然后将每帧导出为jpg格式图片。

2.5 数据标注
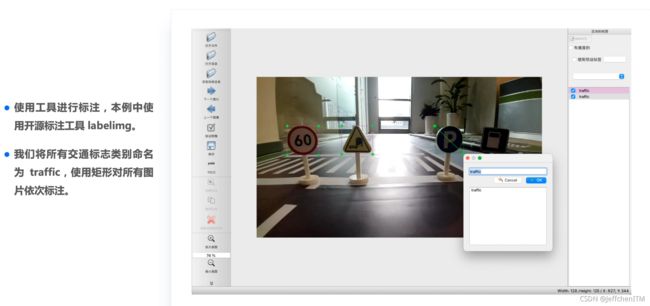
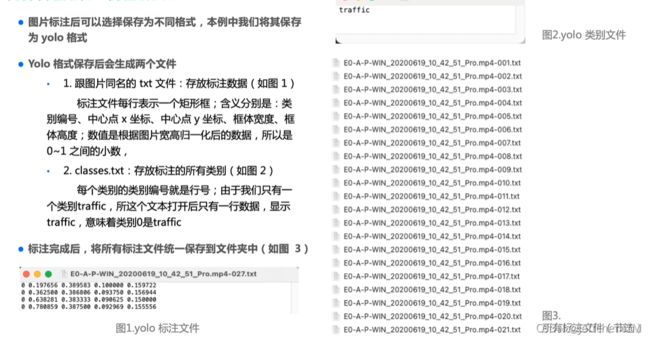
标注检验:
检验标注任务质量
抽查比例由具体任务决定,由于本案中的检测任务较为简单,我们抽查1%,即100张。
抽查通过在标注工具中点击空格将其背景转换为绿色。
2.6 数据集拆分
将所有数据按照8∶2的比例拆分为训练集与测试集,注意标注文件也应当对应拆分。
训练集将提供跟算法组用于模型训练;测试集将提供给测试组用于验证数据的泛化效果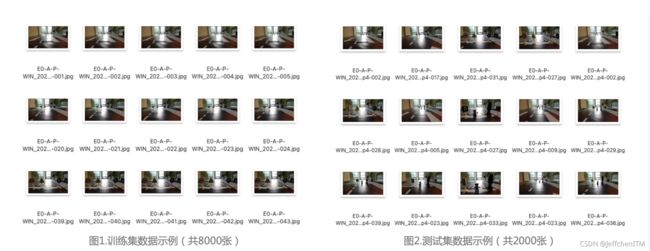
2.7 检测算法原理
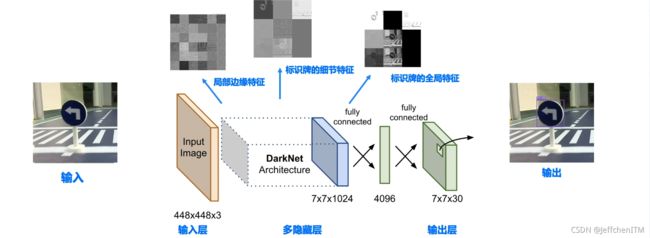
多隐层的深度神经网络
为实现目标检测任务的有效特征识别,构建一个含有多隐藏层的前馈神经网络。
学习的是神经元中的权重参数,可以看到神经网络模型可以有效的提取出输入图像中的特征信息。
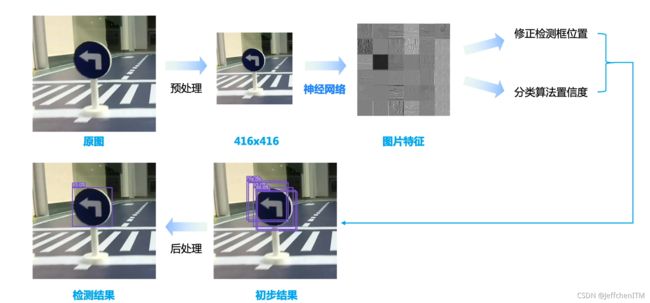
2.8 模型训练
使用训练集进行训练,同步观察输出结果
精确率(Precision ):在被识别为正类别的样本中,确实为正类别的比例是多少
召回率(Recall ):在所有正类别样本中,被正确识别为正类别的比例是多少?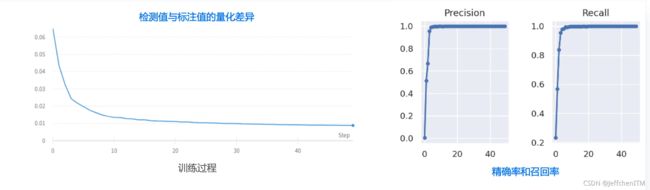
2.9 效果与指标
3 总结与拓展
