论文精讲 | CVPR 2022|RHFL-对抗噪声的联邦学习
模型异构的联邦学习,是一种每个client拥有互不相同模型的联邦学习任务,其能够解决联邦学习中每个成员希望独立设计自己模型的需求,但目前同样面临着来自数据层面和成员层面的各种挑战,比如数据标记困难,训练中存在搭便车成员,及其进一步导致的标签噪声问题。
当前的异构联邦学习的假设是基于一些完全“干净”的数据集,而针对标签噪声的解决方案则只被应用在机器学习的方案中。而这篇文章针对上述问题首次提出了一种:具有标签噪声鲁棒性的模型异构联邦学习,即RHFL(Robust Heterogeneous Federated Learning)。
作者提出的全新的具有噪声鲁棒性的异构联邦学习方法,同时提出了评估成员模型好坏的CCR方法。在实验中,验证了该方法比FedMD,FedDF等state of the art方法具有更好的performance。

论文标题
Robust Federated Learning with Noisy and Heterogeneous Clients
论文来源
CVPR 2022
论文链接
https://openaccess.thecvf.com/content/CVPR2022/papers/Fang_Robust_Federated_Learning_With_Noisy_and_Heterogeneous_Clients_CVPR_2022_paper.pdf
代码链接
https://gitee.com/mindspore/contrib/tree/master/papers/RHFL
1介绍
传统机器学习场景中的噪声处理方法主要包括以下这几种:
❶ 标签转换矩阵;❷ 标签的鲁棒性正则化;❸ 损失函数的鲁棒性正则化;❹ 挑选“干净”的数据样本。
在联邦学习场景中,成员对独立设计私有模型的需求不断增加,而联邦学习过程中成员的质量也参差不齐。

图1:展示了联邦学习中不同client的模型,以及其对应的私有数据集噪声含量的情况。
在这文章中,作者提出了如下的背景假设:
以异构联邦学习的setting为基础:有K个clients,一个server。C是所有client的集合,有|C|=K。对于第K个client,有私有数据集
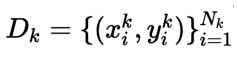
其中

即y代表一个one-hot的标签向量,作为正确标注的标签,同时每个client也含有其噪声数据集
![]()
代表错误标注的标签。第k个client私有模型θk,对于不同的k,θk所代表的模型各不相同。f(xk,θk)代表样本xk输入经过θk模型之后的logits层输出。
此外有公共数据集

联合学习(collaborative)更新参数的epoch记作Tc,在本地(local)更新参数的epoch记作T1。由于模型异构以及标签噪声问题导致的各神经网络logits层输出不相同,记作
![]()
作者为解决以上问题而提出的学习流程主要分为三个部分:
① HFL:异构clients之间交流,互相学习并优化参数(2.1)
② SL:防止模型对noise标签的过拟合现象(2.2)
③ CCR:对每个client获得一个权重来减弱noisy client的贡献(2.3)
2方法
2.1 Heterogeneous Federated Learning(HFL)
在协作学习阶段,作者用D0作为桥梁来实现clients之间的沟通。在Tc epoch中,client ck用其在该epoch内的本地模型θk来计算D0的logits层输出,从而获得一种客户端ck上的"knowledge distribution"(知识分布):
![]()
这里作者使用了"Kullback-Leibler divergence"(KL散度)来描述两种不同分布之间的差异,考虑两中不同的变量分布:
![]()
以及
![]()
关于两种分布的KL散度的表达式记为:

KL值越大,代表两种变量分布差距越大,当KL函数值为0时,认为两种变量遵循相同分布。所以可以写出针对第k个client来说,其知识distribution的损失函数:

当损失函数越小时,第k个client的模型与其余模型的logits层输出的相似度就越高。计算出损失函数后,每个clients分别开始模型参数更新如下:
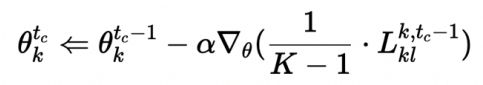
MindSpore代码实现HFL:

对每个participant进行KL损失计算,然后participant进行参数更新。
2.2 Local Noise Learning(SL)
CE损失函数:

来源于KL损失函数。CE损失函数不能同时充分学习所有类的数据,导致需要更多的epoch才能让loss充分收敛。在那些由于需要学习难以学习的类,而额外学习的epoch中,之前已经学习好的,容易学习的类中很容易产生过拟合(对噪声的过拟合),这时模型的performance将会下降。
考虑到noisy label的存在,模型的预测结果在某种程度上比给定的label更加可靠。因此作者提出了反向交叉熵损失函数:Reverse Cross Entrophy(RCE)function,用来代表:假设以预测结果为基准时,给定标签的有效性:

定义Symmetric Cross Entropy Learning(SL)(对称交叉熵学习)的损失函数:
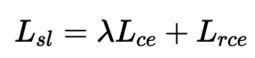
其中λ系数作为超参数,代表对噪声的控制程度。
之后,作者用新的SL损失函数设计了新的本地参数update过程如下:
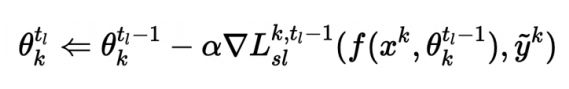
MindSpore代码实现SL:

分别计算出CE和RCE,再加起来算出SL损失函数。
2.3 Client Confidence Re-weighting(CCR)
Client Confidence Re-weighting(CCR)机制主要用来减弱某些搭便车的noisy client对其他client的影响。
考虑到如下事实:如果第k个本地模型θk在其私有数据集(包括噪声集)上的SL损失很大,那就说明该client的私有数据集拥有较大的噪声。作者据此定义出了针对第k个client的标签质量(label quality)函数:
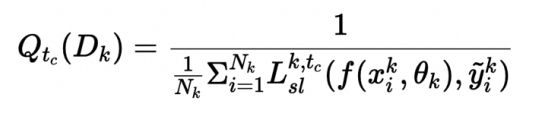
为量化学习效率(learning efficiency),作者同时定义了第k个client,在Tc中的SL drop rate函数:

同时考虑到标签质量(label quality)以及学习效率,定义第k个client的置信度(confidence)函数:

对client k,其权重可记为:
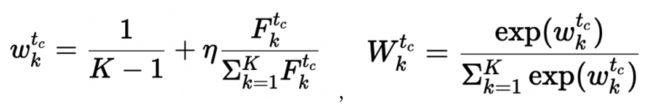
特殊地,当η为0时,公式退化为不考虑client置信度的一般情况。考虑动态权重的参数更新公式如图:
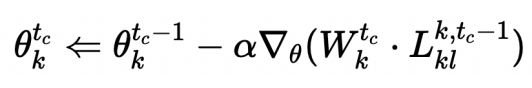
MindSpore代码实现CCR:

代码略长,是按上文中陈述顺序,先求质量函数,再求置信度函数,之后得到权重,最后进行根据权重的参数更新过程。
2.4 学习流程
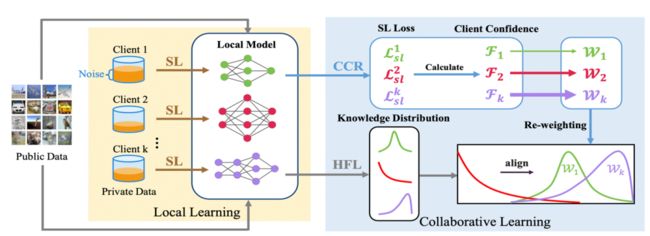
图2:RHFL的全过程示意图
3实验结果
这里展示了主要实验成果和数据,更多任务和实验消除分析的细节请参见论文。
3.1 基于无噪声异构设定下的实验
作者首先在无噪声的异构模型下进行试验:θi代表第i个client的私有模型,而Avg则代表平均预测精度:

比较发现RHFL方法下绝大部分的client的预测精度,以及所有client的平均预测精度,在无噪声的情况下均高于state of the art的方法。
3.2 基于有噪声同构设定下的实验
作者其次进行了同构模型(ResNet12)下的实验,分别设置了不同噪声比例:μ=0.1/0.2,以及不同噪声类型:Pairflip, Symflip,组合而成的共四种噪声数据组成:

实验结果表明,RHFL在所有设定下均有高于state of the art的预测精度。
3.3 基于有噪声且模型异构设定下的实验
作者将模型异构和噪声结合到一起,得到如下数据:

结果中RHFL在绝大多数的client的预测精度和全部平均精度上均高于state of the art方法。
3.4 消融实验
作者对paper中提出的几种方法做了异构模型下不同噪声比例的消融实验如图:

可以看出,在大部分情况下HFL,SL以及CCR方法同时存在才能取得最好的performance。
4总结与展望
这篇paper研究了一个全新的问题,即如何在有噪声的异构客户端中执行鲁棒的联邦学习。为了解决这个问题,作者提出了一种新的解决方案RHFL。首先公共数据上的反馈分布,以实现模型异构客户机之间的联邦学习。其次,为避免每个模型在局部学习过程中对噪声过度拟合,作者采用了对称损失函数来更新局部模型。最后,对于来自其他参与者的噪声反馈,本文提出了一种灵活的重加权方法CCR,有效地避免了来自噪声客户端的过度学习,实现了鲁棒的联邦协作。
广泛的实验证明了所提出方法中每个成员方法的有效性。实验结果表明,所提方法在模型同构和异构场景下均取得了比当前先进技术更高的精度,未来将会继续在联邦学习领域的探索。